 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatSGLD: A Dataset with Speech, Gesture, Logic, and Demonstration for Robot Learning in Natural Human-Robot Interaction
Feb 23, 2025Recent advances in multimodal Human-Robot Interaction (HRI) datasets emphasize the integration of speech and gestures, allowing robots to absorb explicit knowledge and tacit understanding. However, existing datasets primarily focus on elementary tasks like object pointing and pushing, limiting their applicability to complex domains. They prioritize simpler human command data but place less emphasis on training robots to correctly interpret tasks and respond appropriately. To address these gaps, we present the NatSGLD dataset, which was collected using a Wizard of Oz (WoZ) method, where participants interacted with a robot they believed to be autonomous. NatSGLD records humans' multimodal commands (speech and gestures), each paired with a demonstration trajectory and a Linear Temporal Logic (LTL) formula that provides a ground-truth interpretation of the commanded tasks. This dataset serves as a foundational resource for research at the intersection of HRI and machine learning. By providing multimodal inputs and detailed annotations, NatSGLD enables exploration in areas such as multimodal instruction following, plan recognition, and human-advisable reinforcement learning from demonstrations. We release the dataset and code under the MIT License at https://www.snehesh.com/natsgld/ to support future HRI research.
* arXiv admin note: substantial text overlap with arXiv:2403.02274
VioPose: Violin Performance 4D Pose Estimation by Hierarchical Audiovisual Inference
Nov 19, 2024



Musicians delicately control their bodies to generate music. Sometimes, their motions are too subtle to be captured by the human eye. To analyze how they move to produce the music, we need to estimate precise 4D human pose (3D pose over time). However, current state-of-the-art (SoTA) visual pose estimation algorithms struggle to produce accurate monocular 4D poses because of occlusions, partial views, and human-object interactions. They are limited by the viewing angle, pixel density, and sampling rate of the cameras and fail to estimate fast and subtle movements, such as in the musical effect of vibrato. We leverage the direct causal relationship between the music produced and the human motions creating them to address these challenges. We propose VioPose: a novel multimodal network that hierarchically estimates dynamics. High-level features are cascaded to low-level features and integrated into Bayesian updates. Our architecture is shown to produce accurate pose sequences, facilitating precise motion analysis, and outperforms SoTA. As part of this work, we collected the largest and the most diverse calibrated violin-playing dataset, including video, sound, and 3D motion capture poses. Project page: is available at https://sj-yoo.info/viopose/.
Choreographing the Digital Canvas: A Machine Learning Approach to Artistic Performance
Mar 26, 2024



This paper introduces the concept of a design tool for artistic performances based on attribute descriptions. To do so, we used a specific performance of falling actions. The platform integrates a novel machine-learning (ML) model with an interactive interface to generate and visualize artistic movements. Our approach's core is a cyclic Attribute-Conditioned Variational Autoencoder (AC-VAE) model developed to address the challenge of capturing and generating realistic 3D human body motions from motion capture (MoCap) data. We created a unique dataset focused on the dynamics of falling movements, characterized by a new ontology that divides motion into three distinct phases: Impact, Glitch, and Fall. The ML model's innovation lies in its ability to learn these phases separately. It is achieved by applying comprehensive data augmentation techniques and an initial pose loss function to generate natural and plausible motion. Our web-based interface provides an intuitive platform for artists to engage with this technology, offering fine-grained control over motion attributes and interactive visualization tools, including a 360-degree view and a dynamic timeline for playback manipulation. Our research paves the way for a future where technology amplifies the creative potential of human expression, making sophisticated motion generation accessible to a wider artistic community.
NatSGD: A Dataset with Speech, Gestures, and Demonstrations for Robot Learning in Natural Human-Robot Interaction
Mar 04, 2024



Recent advancements in multimodal Human-Robot Interaction (HRI) datasets have highlighted the fusion of speech and gesture, expanding robots' capabilities to absorb explicit and implicit HRI insights. However, existing speech-gesture HRI datasets often focus on elementary tasks, like object pointing and pushing, revealing limitations in scaling to intricate domains and prioritizing human command data over robot behavior records. To bridge these gaps, we introduce NatSGD, a multimodal HRI dataset encompassing human commands through speech and gestures that are natural, synchronized with robot behavior demonstrations. NatSGD serves as a foundational resource at the intersection of machine learning and HRI research, and we demonstrate its effectiveness in training robots to understand tasks through multimodal human commands, emphasizing the significance of jointly considering speech and gestures. We have released our dataset, simulator, and code to facilitate future research in human-robot interaction system learning; access these resources at https://www.snehesh.com/natsgd/
Considerations for Minimizing Data Collection Biases for Eliciting Natural Behavior in Human-Robot Interaction
Apr 19, 2023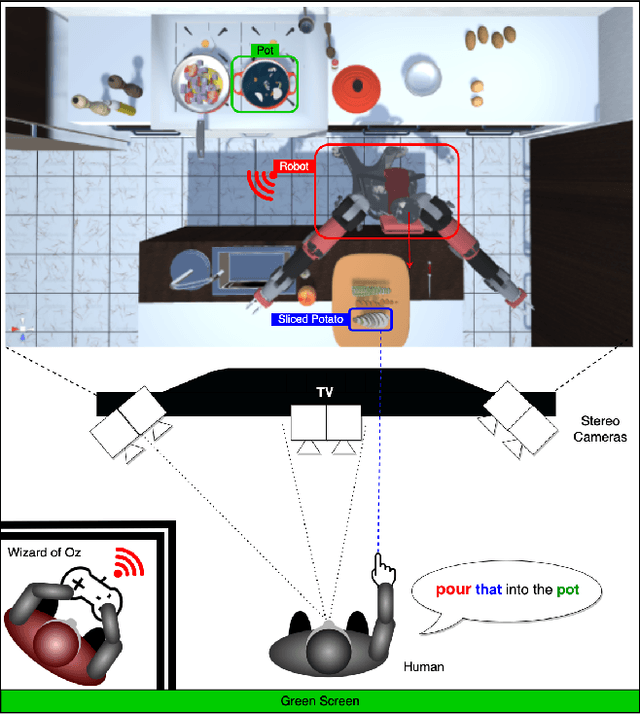
Many of us researchers take extra measures to control for known-unknowns. However, unknown-unknowns can, at best, be negligible, but otherwise, they could produce unreliable data that might have dire consequences in real-life downstream applications. Human-Robot Interaction standards informed by empirical data could save us time and effort and provide us with the path toward the robots of the future. To this end, we share some of our pilot studies, lessons learned, and how they affected the outcome of our experiments. While these aspects might not be publishable in themselves, we hope our work might save time and effort for other researchers towards their research and serve as additional considerations for discussion at the workshop.
AIMusicGuru: Music Assisted Human Pose Correction
Mar 24, 2022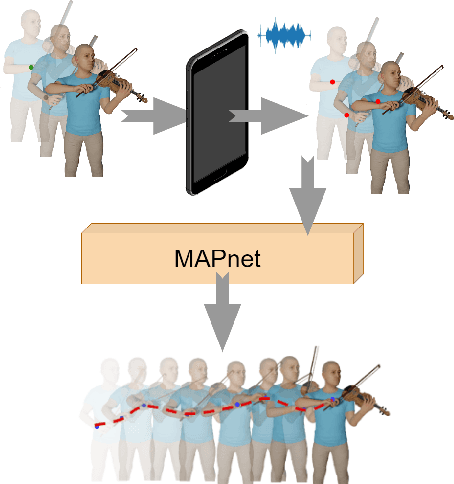
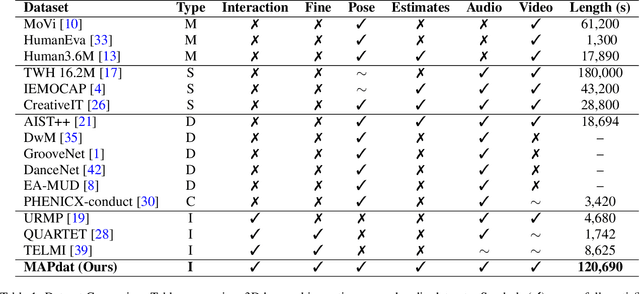
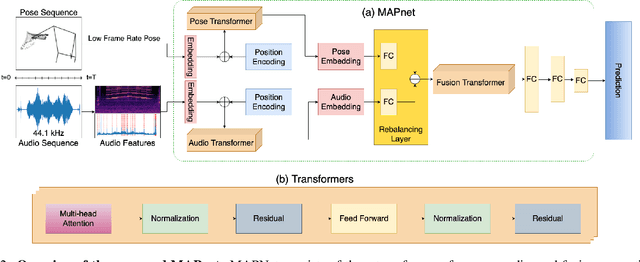
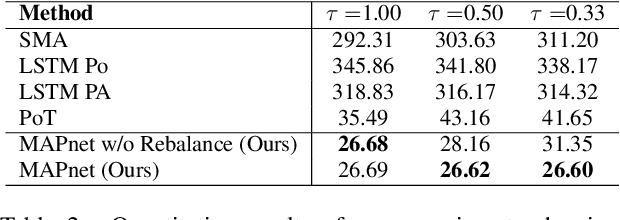
Pose Estimation techniques rely on visual cues available through observations represented in the form of pixels. But the performance is bounded by the frame rate of the video and struggles from motion blur, occlusions, and temporal coherence. This issue is magnified when people are interacting with objects and instruments, for example playing the violin. Standard approaches for postprocessing use interpolation and smoothing functions to filter noise and fill gaps, but they cannot model highly non-linear motion. We present a method that leverages our understanding of the high degree of a causal relationship between the sound produced and the motion that produces them. We use the audio signature to refine and predict accurate human body pose motion models. We propose MAPnet (Music Assisted Pose network) for generating a fine grain motion model from sparse input pose sequences but continuous audio. To accelerate further research in this domain, we also open-source MAPdat, a new multi-modal dataset of 3D violin playing motion with music. We perform a comparison of different standard machine learning models and perform analysis on input modalities, sampling techniques, and audio and motion features. Experiments on MAPdat suggest multi-modal approaches like ours as a promising direction for tasks previously approached with visual methods only. Our results show both qualitatively and quantitatively how audio can be combined with visual observation to help improve any pose estimation methods.
Hybrid Backpropagation Parallel Reservoir Networks
Oct 27, 2020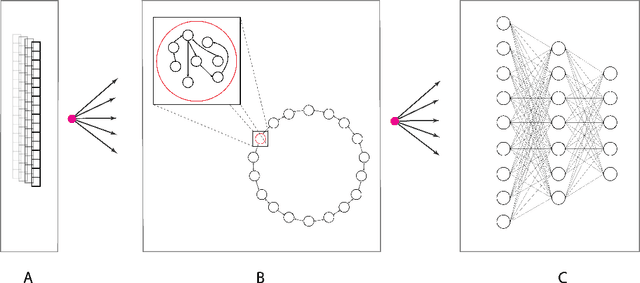
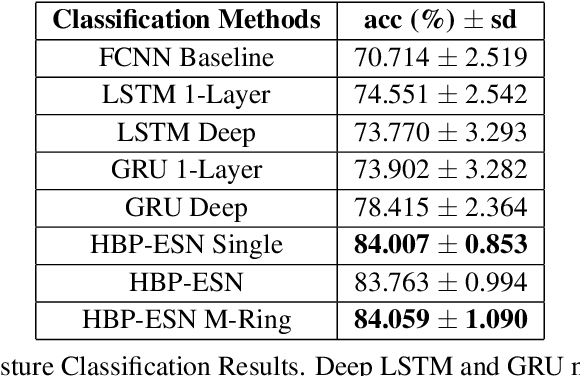

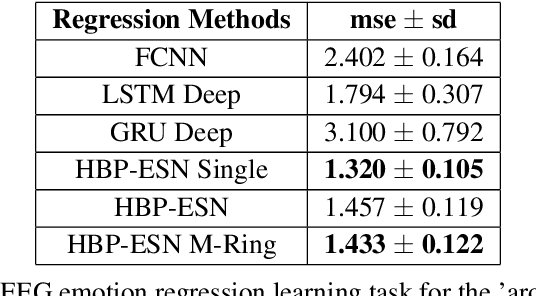
In many real-world applications, fully-differentiable RNNs such as LSTMs and GRUs have been widely deployed to solve time series learning tasks. These networks train via Backpropagation Through Time, which can work well in practice but involves a biologically unrealistic unrolling of the network in time for gradient updates, are computationally expensive, and can be hard to tune. A second paradigm, Reservoir Computing, keeps the recurrent weight matrix fixed and random. Here, we propose a novel hybrid network, which we call Hybrid Backpropagation Parallel Echo State Network (HBP-ESN) which combines the effectiveness of learning random temporal features of reservoirs with the readout power of a deep neural network with batch normalization. We demonstrate that our new network outperforms LSTMs and GRUs, including multi-layer "deep" versions of these networks, on two complex real-world multi-dimensional time series datasets: gesture recognition using skeleton keypoints from ChaLearn, and the DEAP dataset for emotion recognition from EEG measurements. We show also that the inclusion of a novel meta-ring structure, which we call HBP-ESN M-Ring, achieves similar performance to one large reservoir while decreasing the memory required by an order of magnitude. We thus offer this new hybrid reservoir deep learning paradigm as a new alternative direction for RNN learning of temporal or sequential data.