 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIMusicGuru: Music Assisted Human Pose Correction
Mar 24, 2022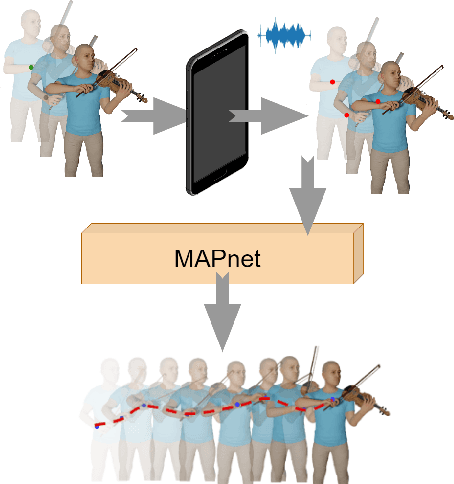
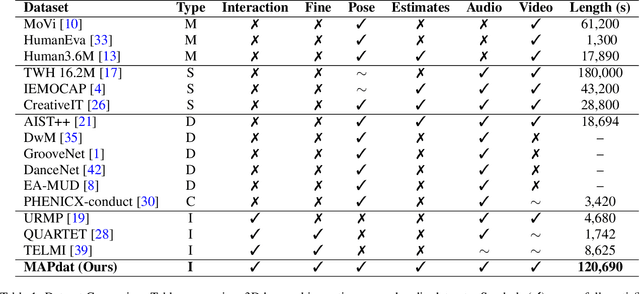
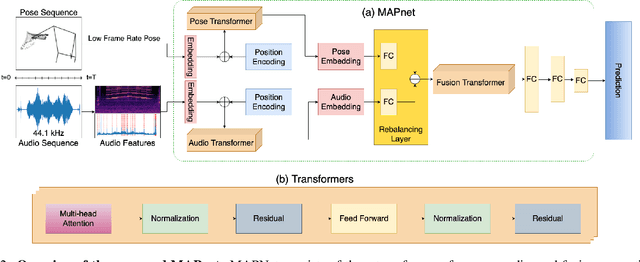
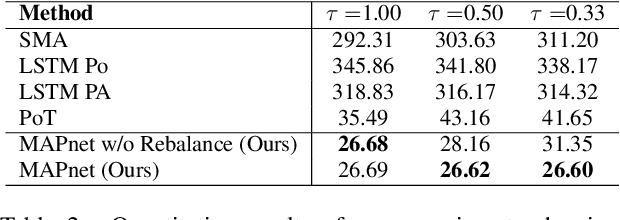
Pose Estimation techniques rely on visual cues available through observations represented in the form of pixels. But the performance is bounded by the frame rate of the video and struggles from motion blur, occlusions, and temporal coherence. This issue is magnified when people are interacting with objects and instruments, for example playing the violin. Standard approaches for postprocessing use interpolation and smoothing functions to filter noise and fill gaps, but they cannot model highly non-linear motion. We present a method that leverages our understanding of the high degree of a causal relationship between the sound produced and the motion that produces them. We use the audio signature to refine and predict accurate human body pose motion models. We propose MAPnet (Music Assisted Pose network) for generating a fine grain motion model from sparse input pose sequences but continuous audio. To accelerate further research in this domain, we also open-source MAPdat, a new multi-modal dataset of 3D violin playing motion with music. We perform a comparison of different standard machine learning models and perform analysis on input modalities, sampling techniques, and audio and motion features. Experiments on MAPdat suggest multi-modal approaches like ours as a promising direction for tasks previously approached with visual methods only. Our results show both qualitatively and quantitatively how audio can be combined with visual observation to help improve any pose estimation methods.
DiffPoseNet: Direct Differentiable Camera Pose Estimation
Mar 21, 2022

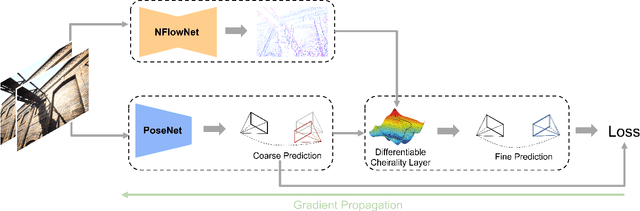

Current deep neural network approaches for camera pose estimation rely on scene structure for 3D motion estimation, but this decreases the robustness and thereby makes cross-dataset generalization difficult. In contrast, classical approaches to structure from motion estimate 3D motion utilizing optical flow and then compute depth. Their accuracy, however, depends strongly on the quality of the optical flow. To avoid this issue, direct methods have been proposed, which separate 3D motion from depth estimation but compute 3D motion using only image gradients in the form of normal flow. In this paper, we introduce a network NFlowNet, for normal flow estimation which is used to enforce robust and direct constraints. In particular, normal flow is used to estimate relative camera pose based on the cheirality (depth positivity) constraint. We achieve this by formulating the optimization problem as a differentiable cheirality layer, which allows for end-to-end learning of camera pose. We perform extensive qualitative and quantitative evaluation of the proposed DiffPoseNet's sensitivity to noise and its generalization across datasets. We compare our approach to existing state-of-the-art methods on KITTI, TartanAir, and TUM-RGBD datasets.
GradTac: Spatio-Temporal Gradient Based Tactile Sensing
Mar 14, 2022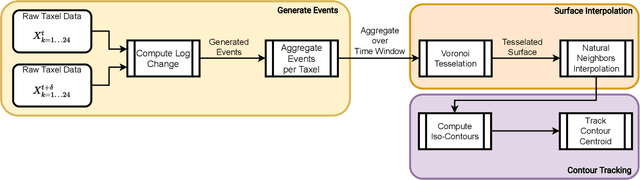
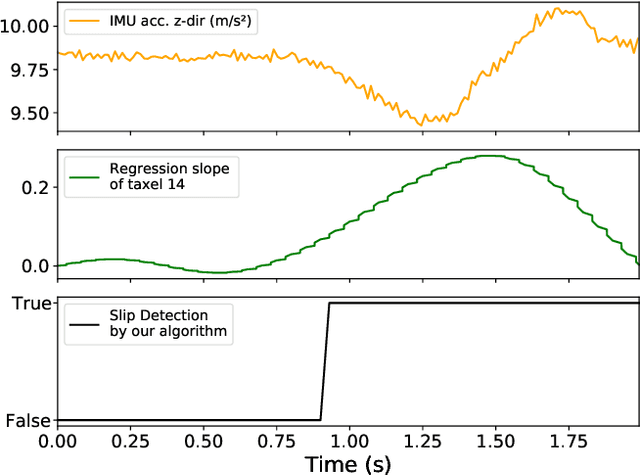

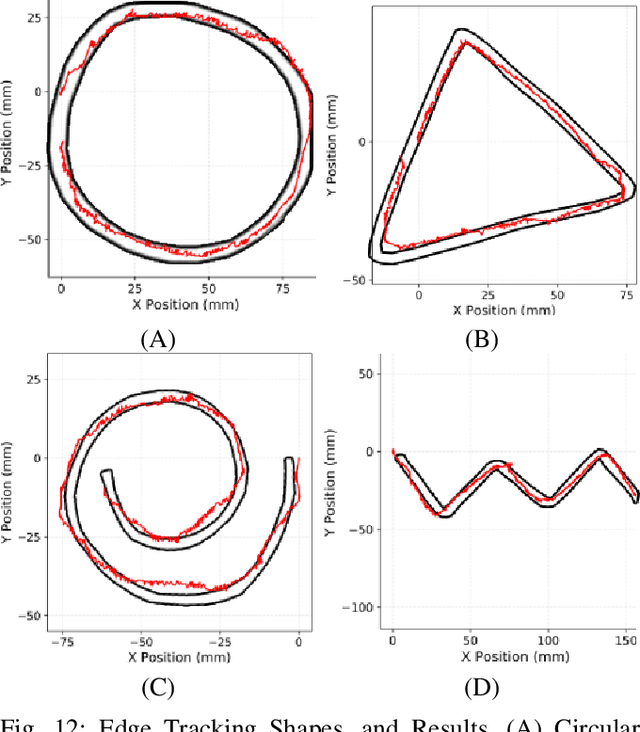
Tactile sensing for robotics is achieved through a variety of mechanisms, including magnetic, optical-tactile, and conductive fluid. Currently, the fluid-based sensors have struck the right balance of anthropomorphic sizes and shapes and accuracy of tactile response measurement. However, this design is plagued by a low Signal to Noise Ratio (SNR) due to the fluid based sensing mechanism "damping" the measurement values that are hard to model. To this end, we present a spatio-temporal gradient representation on the data obtained from fluid-based tactile sensors, which is inspired from neuromorphic principles of event based sensing. We present a novel algorithm (GradTac) that converts discrete data points from spatial tactile sensors into spatio-temporal surfaces and tracks tactile contours across these surfaces. Processing the tactile data using the proposed spatio-temporal domain is robust, makes it less susceptible to the inherent noise from the fluid based sensors, and allows accurate tracking of regions of touch as compared to using the raw data. We successfully evaluate and demonstrate the efficacy of GradTac on many real-world experiments performed using the Shadow Dexterous Hand, equipped with the BioTac SP sensors. Specifically, we use it for tracking tactile input across the sensor's surface, measuring relative forces, detecting linear and rotational slip, and for edge tracking. We also release an accompanying task-agnostic dataset for the BioTac SP, which we hope will provide a resource to compare and quantify various novel approaches, and motivate further research.
NudgeSeg: Zero-Shot Object Segmentation by Repeated Physical Interaction
Sep 22, 2021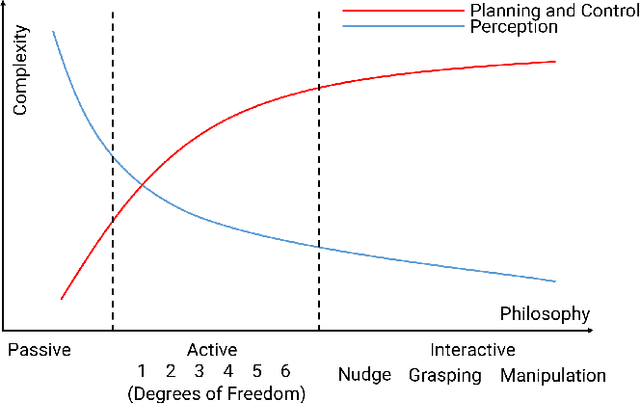
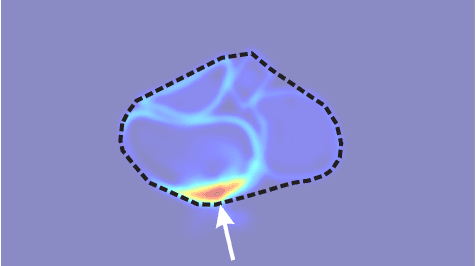
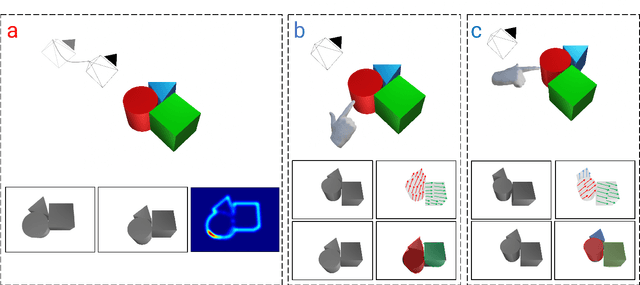

Recent advances in object segmentation have demonstrated that deep neural networks excel at object segmentation for specific classes in color and depth images. However, their performance is dictated by the number of classes and objects used for training, thereby hindering generalization to never seen objects or zero-shot samples. To exacerbate the problem further, object segmentation using image frames rely on recognition and pattern matching cues. Instead, we utilize the 'active' nature of a robot and their ability to 'interact' with the environment to induce additional geometric constraints for segmenting zero-shot samples. In this paper, we present the first framework to segment unknown objects in a cluttered scene by repeatedly 'nudging' at the objects and moving them to obtain additional motion cues at every step using only a monochrome monocular camera. We call our framework NudgeSeg. These motion cues are used to refine the segmentation masks. We successfully test our approach to segment novel objects in various cluttered scenes and provide an extensive study with image and motion segmentation methods. We show an impressive average detection rate of over 86% on zero-shot objects.
* 8 Pages, 7 Figures, 3 Tables
EVPropNet: Detecting Drones By Finding Propellers For Mid-Air Landing And Following
Jun 29, 2021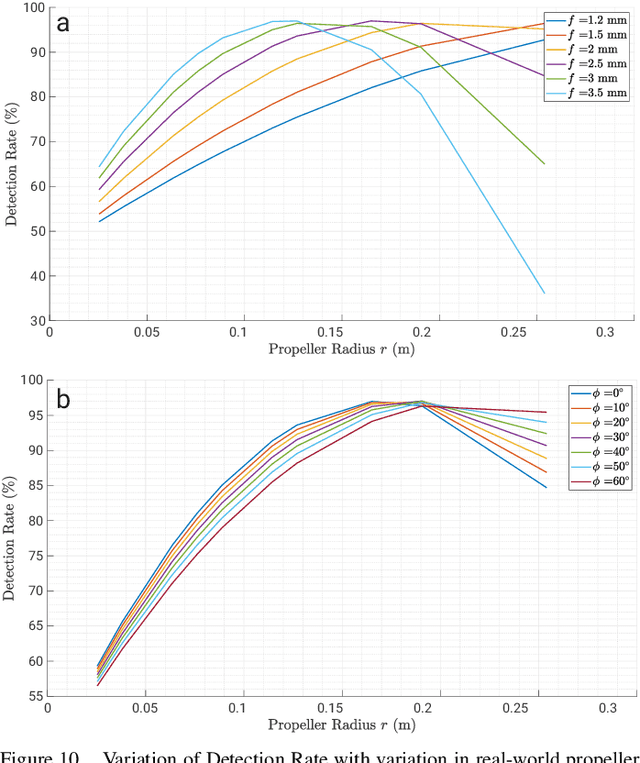
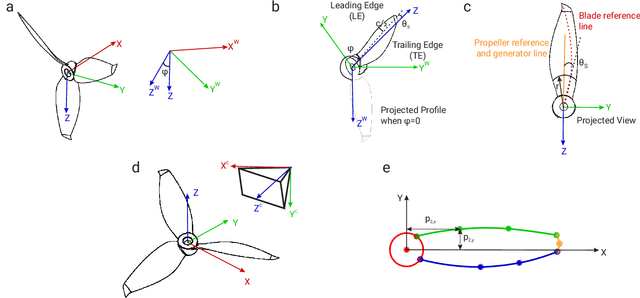
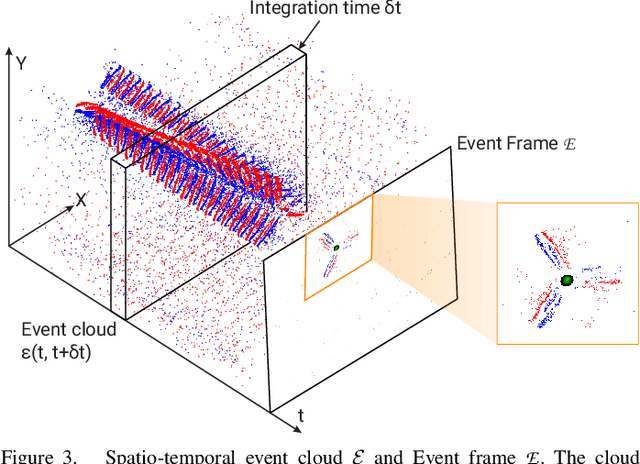

The rapid rise of accessibility of unmanned aerial vehicles or drones pose a threat to general security and confidentiality. Most of the commercially available or custom-built drones are multi-rotors and are comprised of multiple propellers. Since these propellers rotate at a high-speed, they are generally the fastest moving parts of an image and cannot be directly "seen" by a classical camera without severe motion blur. We utilize a class of sensors that are particularly suitable for such scenarios called event cameras, which have a high temporal resolution, low-latency, and high dynamic range. In this paper, we model the geometry of a propeller and use it to generate simulated events which are used to train a deep neural network called EVPropNet to detect propellers from the data of an event camera. EVPropNet directly transfers to the real world without any fine-tuning or retraining. We present two applications of our network: (a) tracking and following an unmarked drone and (b) landing on a near-hover drone. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with different propeller shapes and sizes. Our network can detect propellers at a rate of 85.1% even when 60% of the propeller is occluded and can run at upto 35Hz on a 2W power budget. To our knowledge, this is the first deep learning-based solution for detecting propellers (to detect drones). Finally, our applications also show an impressive success rate of 92% and 90% for the tracking and landing tasks respectively.
SpikeMS: Deep Spiking Neural Network for Motion Segmentation
May 13, 2021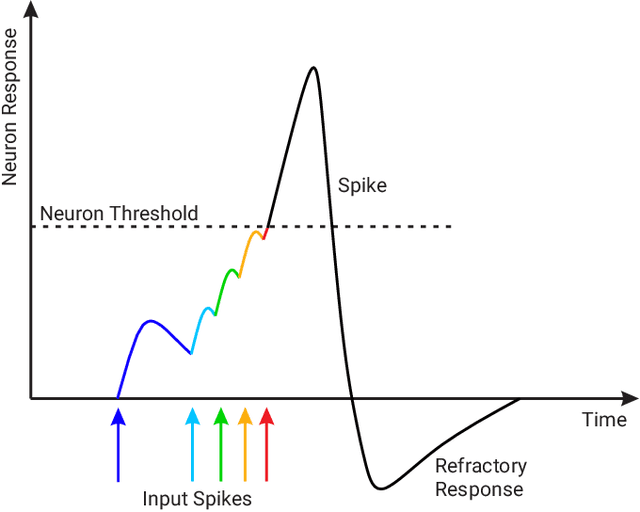
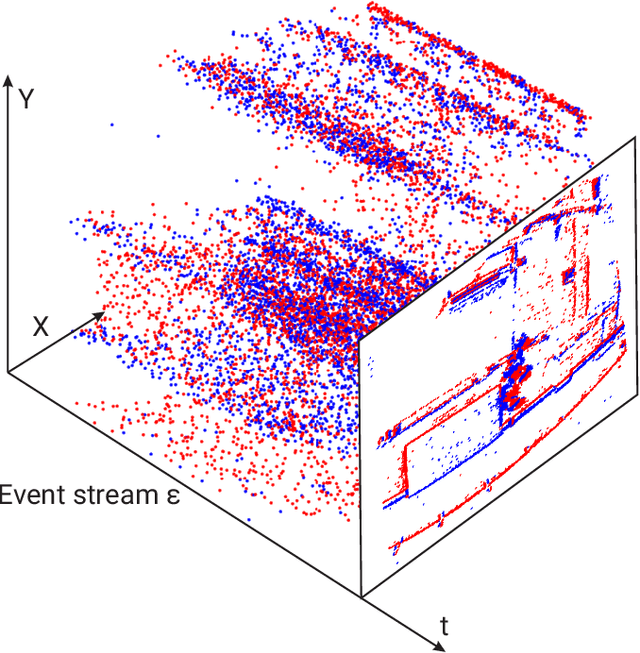
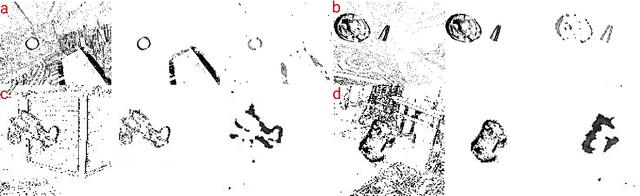
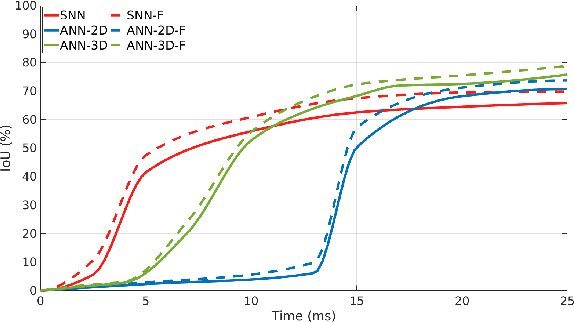
Spiking Neural Networks (SNN) are the so-called third generation of neural networks which attempt to more closely match the functioning of the biological brain. They inherently encode temporal data, allowing for training with less energy usage and can be extremely energy efficient when coded on neuromorphic hardware. In addition, they are well suited for tasks involving event-based sensors, which match the event-based nature of the SNN. However, SNNs have not been as effectively applied to real-world, large-scale tasks as standard Artificial Neural Networks (ANNs) due to the algorithmic and training complexity. To exacerbate the situation further, the input representation is unconventional and requires careful analysis and deep understanding. In this paper, we propose \textit{SpikeMS}, the first deep encoder-decoder SNN architecture for the real-world large-scale problem of motion segmentation using the event-based DVS camera as input. To accomplish this, we introduce a novel spatio-temporal loss formulation that includes both spike counts and classification labels in conjunction with the use of new techniques for SNN backpropagation. In addition, we show that \textit{SpikeMS} is capable of \textit{incremental predictions}, or predictions from smaller amounts of test data than it is trained on. This is invaluable for providing outputs even with partial input data for low-latency applications and those requiring fast predictions. We evaluated \textit{SpikeMS} on challenging synthetic and real-world sequences from EV-IMO, EED and MOD datasets and achieving results on a par with a comparable ANN method, but using potentially 50 times less power.
MOMS with Events: Multi-Object Motion Segmentation With Monocular Event Cameras
Jun 11, 2020



Segmentation of moving objects in dynamic scenes is a key process in scene understanding for both navigation and video recognition tasks. Without prior knowledge of the object structure and motion, the problem is very challenging due to the plethora of motion parameters to be estimated while being agnostic to motion blur and occlusions. Event sensors, because of their high temporal resolution, and lack of motion blur, seem well suited for addressing this problem. We propose a solution to multi-object motion segmentation using a combination of classical optimization methods along with deep learning and does not require prior knowledge of the 3D motion and the number and structure of objects. Using the events within a time-interval, the method estimates and compensates for the global rigid motion. Then it segments the scene into multiple motions by iteratively fitting and merging models using input tracked feature regions via alignment based on temporal gradients and contrast measures. The approach was successfully evaluated on both challenging real-world and synthetic scenarios from the EV-IMO, EED, and MOD datasets, and outperforms the state-of-the-art detection rate by as much as 12% achieving a new state-of-the-art average detection rate of 77.06%, 94.2% and 82.35% on the aforementioned datasets.
EVDodge: Embodied AI For High-Speed Dodging On A Quadrotor Using Event Cameras
Jun 07, 2019
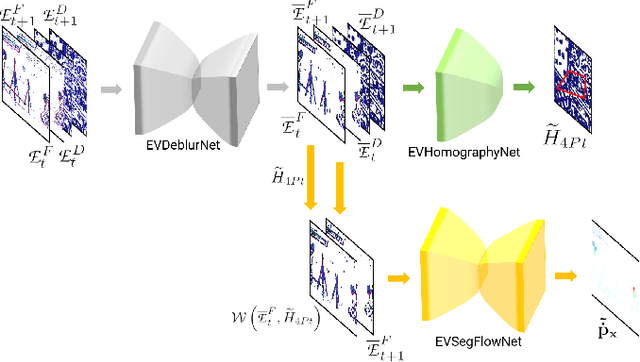
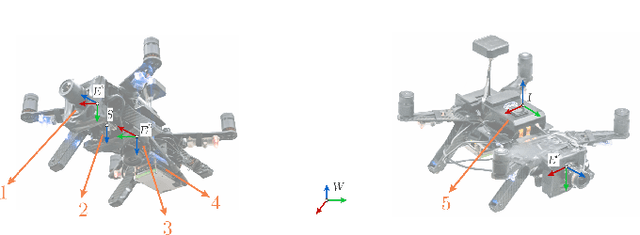
The human fascination to understand ultra-efficient agile flying beings like birds and bees have propelled decades of research on trying to solve the problem of obstacle avoidance on micro aerial robots. However, most of the prior research has focused on static obstacle avoidance. This is due to the lack of high-speed visual sensors and scalable visual algorithms. The last decade has seen an exponential growth of neuromorphic sensors which are inspired by nature and have the potential to be the de facto standard for visual motion estimation problems. After re-imagining the navigation stack of a micro air vehicle as a series of hierarchical competences, we develop a purposive artificial intelligence based formulation for the problem of general navigation. We call this AI framework "Embodied AI" - AI design based on the knowledge of agent's hardware limitations and timing/computation constraints. Following this design philosophy we develop a complete AI navigation stack for dodging multiple dynamic obstacles on a quadrotor with a monocular event camera and computation. We also present an approach to directly transfer the shallow neural networks trained in simulation to the real world by subsuming pre-processing using a neural network into the pipeline. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with obstacles of different shapes and sizes, achieving an overall success rate of 70% including objects of unknown shape and a low light testing scenario. To our knowledge, this is the first deep learning based solution to the problem of dynamic obstacle avoidance using event cameras on a quadrotor. Finally, we also extend our work to the pursuit task by merely reversing the control policy proving that our navigation stack can cater to different scenarios.