 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Training-Free Framework for Precise Mobile Manipulation of Small Everyday Objects
Feb 19, 2025Many everyday mobile manipulation tasks require precise interaction with small objects, such as grasping a knob to open a cabinet or pressing a light switch. In this paper, we develop Servoing with Vision Models (SVM), a closed-loop training-free framework that enables a mobile manipulator to tackle such precise tasks involving the manipulation of small objects. SVM employs an RGB-D wrist camera and uses visual servoing for control. Our novelty lies in the use of state-of-the-art vision models to reliably compute 3D targets from the wrist image for diverse tasks and under occlusion due to the end-effector. To mitigate occlusion artifacts, we employ vision models to out-paint the end-effector thereby significantly enhancing target localization. We demonstrate that aided by out-painting methods, open-vocabulary object detectors can serve as a drop-in module to identify semantic targets (e.g. knobs) and point tracking methods can reliably track interaction sites indicated by user clicks. This training-free method obtains an 85% zero-shot success rate on manipulating unseen objects in novel environments in the real world, outperforming an open-loop control method and an imitation learning baseline trained on 1000+ demonstrations by an absolute success rate of 50%.
Opening Cabinets and Drawers in the Real World using a Commodity Mobile Manipulator
Feb 27, 2024



Pulling open cabinets and drawers presents many difficult technical challenges in perception (inferring articulation parameters for objects from onboard sensors), planning (producing motion plans that conform to tight task constraints), and control (making and maintaining contact while applying forces on the environment). In this work, we build an end-to-end system that enables a commodity mobile manipulator (Stretch RE2) to pull open cabinets and drawers in diverse previously unseen real world environments. We conduct 4 days of real world testing of this system spanning 31 different objects from across 13 different real world environments. Our system achieves a success rate of 61% on opening novel cabinets and drawers in unseen environments zero-shot. An analysis of the failure modes suggests that errors in perception are the most significant challenge for our system. We will open source code and models for others to replicate and build upon our system.
Mitigating Perspective Distortion-induced Shape Ambiguity in Image Crops
Dec 11, 2023



Objects undergo varying amounts of perspective distortion as they move across a camera's field of view. Models for predicting 3D from a single image often work with crops around the object of interest and ignore the location of the object in the camera's field of view. We note that ignoring this location information further exaggerates the inherent ambiguity in making 3D inferences from 2D images and can prevent models from even fitting to the training data. To mitigate this ambiguity, we propose Intrinsics-Aware Positional Encoding (KPE), which incorporates information about the location of crops in the image and camera intrinsics. Experiments on three popular 3D-from-a-single-image benchmarks: depth prediction on NYU, 3D object detection on KITTI & nuScenes, and predicting 3D shapes of articulated objects on ARCTIC, show the benefits of KPE.
Predicting Motion Plans for Articulating Everyday Objects
Mar 02, 2023



Mobile manipulation tasks such as opening a door, pulling open a drawer, or lifting a toilet lid require constrained motion of the end-effector under environmental and task constraints. This, coupled with partial information in novel environments, makes it challenging to employ classical motion planning approaches at test time. Our key insight is to cast it as a learning problem to leverage past experience of solving similar planning problems to directly predict motion plans for mobile manipulation tasks in novel situations at test time. To enable this, we develop a simulator, ArtObjSim, that simulates articulated objects placed in real scenes. We then introduce SeqIK+$\theta_0$, a fast and flexible representation for motion plans. Finally, we learn models that use SeqIK+$\theta_0$ to quickly predict motion plans for articulating novel objects at test time. Experimental evaluation shows improved speed and accuracy at generating motion plans than pure search-based methods and pure learning methods.
Source detection via multi-label classification
Sep 27, 2022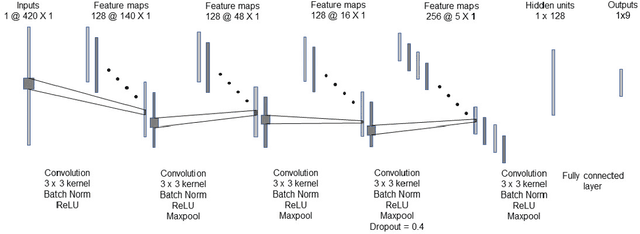
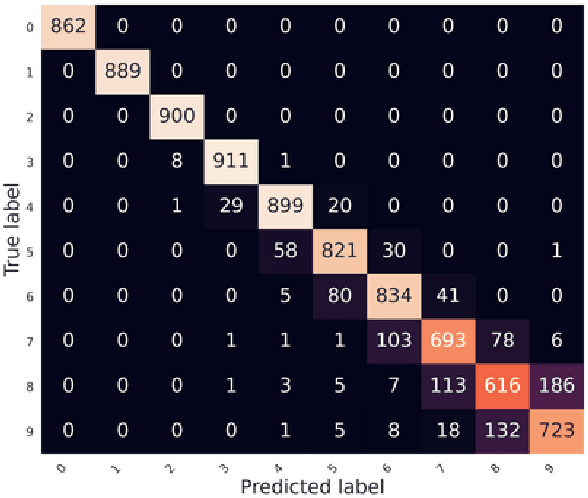
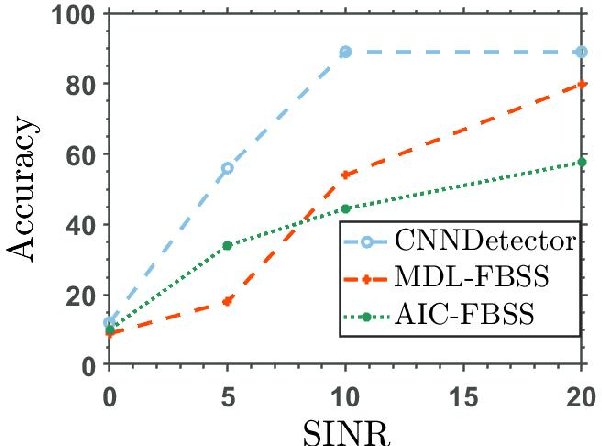
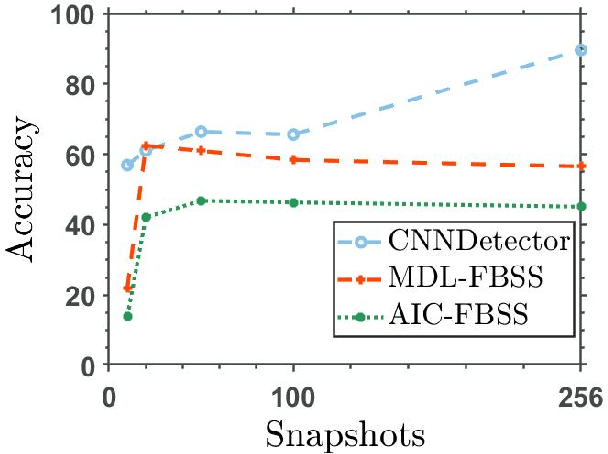
The problem of radio source detection is reformulated as a multi-class classification problem and solved using deep learning frameworks. Incoming waveforms are sampled using a centro-symmetric linear array with omni-directional elements and the normalized upper triangle of the autocorrelation matrix is extracted as the input feature to an uni-dimensional (1D) CNN, trained to detect the sources in the presence of both uncorrelated and correlated signals. The detection algorithms are introduced and subsequently benchmarked against the conventional source detection algorithms. We stress test the algorithms for challenging operational conditions and present extensive evaluations to show the efficacy and contributions of the introduced predictive models.
Learning Value Functions from Undirected State-only Experience
Apr 26, 2022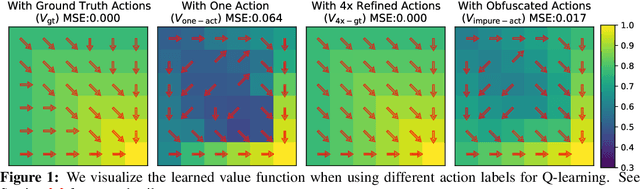



This paper tackles the problem of learning value functions from undirected state-only experience (state transitions without action labels i.e. (s,s',r) tuples). We first theoretically characterize the applicability of Q-learning in this setting. We show that tabular Q-learning in discrete Markov decision processes (MDPs) learns the same value function under any arbitrary refinement of the action space. This theoretical result motivates the design of Latent Action Q-learning or LAQ, an offline RL method that can learn effective value functions from state-only experience. Latent Action Q-learning (LAQ) learns value functions using Q-learning on discrete latent actions obtained through a latent-variable future prediction model. We show that LAQ can recover value functions that have high correlation with value functions learned using ground truth actions. Value functions learned using LAQ lead to sample efficient acquisition of goal-directed behavior, can be used with domain-specific low-level controllers, and facilitate transfer across embodiments. Our experiments in 5 environments ranging from 2D grid world to 3D visual navigation in realistic environments demonstrate the benefits of LAQ over simpler alternatives, imitation learning oracles, and competing methods.
Datasets for Studying Generalization from Easy to Hard Examples
Aug 13, 2021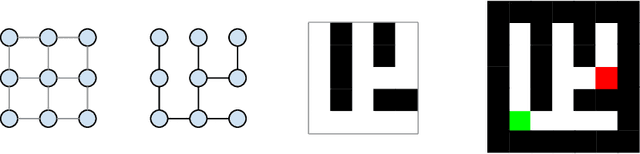
We describe new datasets for studying generalization from easy to hard examples.
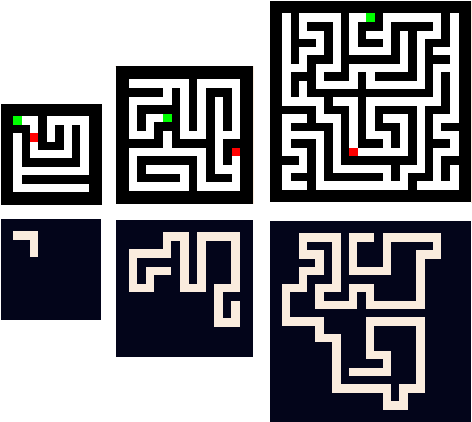
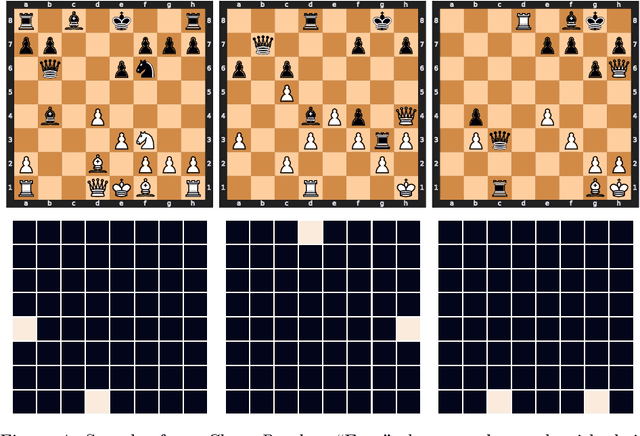
Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent Networks
Jun 08, 2021

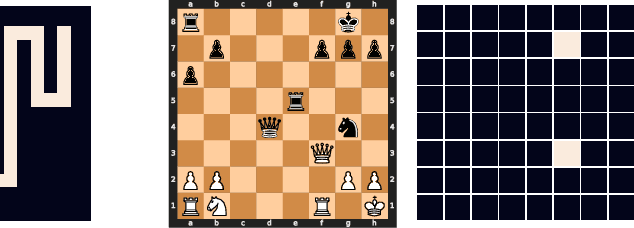

Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans possess the ability to extrapolate reasoning strategies learned on simple problems to solve harder examples, often by thinking for longer. For example, a person who has learned to solve small mazes can easily extend the very same search techniques to solve much larger mazes by spending more time. In computers, this behavior is often achieved through the use of algorithms, which scale to arbitrarily hard problem instances at the cost of more computation. In contrast, the sequential computing budget of feed-forward neural networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning to accommodate harder problems. In this work, we show that recurrent networks trained to solve simple problems with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference. We demonstrate this algorithmic behavior of recurrent networks on prefix sum computation, mazes, and chess. In all three domains, networks trained on simple problem instances are able to extend their reasoning abilities at test time simply by "thinking for longer."
Thinking Deeply with Recurrence: Generalizing from Easy to Hard Sequential Reasoning Problems
Mar 17, 2021
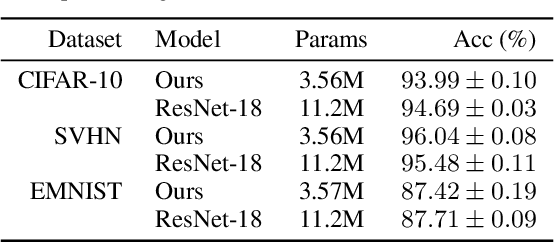
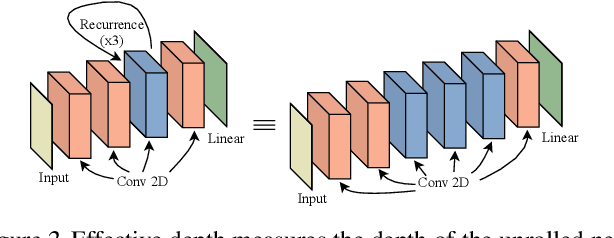

Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans can extrapolate simple reasoning strategies to solve difficult problems using long sequences of abstract manipulations, i.e., harder problems are solved by thinking for longer. In contrast, the sequential computing budget of feed-forward networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning capabilities without retraining. In this work, we observe that recurrent networks have the uncanny ability to closely emulate the behavior of non-recurrent deep models, often doing so with far fewer parameters, on both image classification and maze solving tasks. We also explore whether recurrent networks can make the generalization leap from simple problems to hard problems simply by increasing the number of recurrent iterations used at test time. To this end, we show that recurrent networks that are trained to solve simple mazes with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference.
DP-InstaHide: Provably Defusing Poisoning and Backdoor Attacks with Differentially Private Data Augmentations
Mar 02, 2021Data poisoning and backdoor attacks manipulate training data to induce security breaches in a victim model. These attacks can be provably deflected using differentially private (DP) training methods, although this comes with a sharp decrease in model performance. The InstaHide method has recently been proposed as an alternative to DP training that leverages supposed privacy properties of the mixup augmentation, although without rigorous guarantees. In this work, we show that strong data augmentations, such as mixup and random additive noise, nullify poison attacks while enduring only a small accuracy trade-off. To explain these finding, we propose a training method, DP-InstaHide, which combines the mixup regularizer with additive noise. A rigorous analysis of DP-InstaHide shows that mixup does indeed have privacy advantages, and that training with k-way mixup provably yields at least k times stronger DP guarantees than a naive DP mechanism. Because mixup (as opposed to noise) is beneficial to model performance, DP-InstaHide provides a mechanism for achieving stronger empirical performance against poisoning attacks than other known DP methods.