 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Vision Transformers Learn? A Visual Exploration
Dec 13, 2022



Vision transformers (ViTs) are quickly becoming the de-facto architecture for computer vision, yet we understand very little about why they work and what they learn. While existing studies visually analyze the mechanisms of convolutional neural networks, an analogous exploration of ViTs remains challenging. In this paper, we first address the obstacles to performing visualizations on ViTs. Assisted by these solutions, we observe that neurons in ViTs trained with language model supervision (e.g., CLIP) are activated by semantic concepts rather than visual features. We also explore the underlying differences between ViTs and CNNs, and we find that transformers detect image background features, just like their convolutional counterparts, but their predictions depend far less on high-frequency information. On the other hand, both architecture types behave similarly in the way features progress from abstract patterns in early layers to concrete objects in late layers. In addition, we show that ViTs maintain spatial information in all layers except the final layer. In contrast to previous works, we show that the last layer most likely discards the spatial information and behaves as a learned global pooling operation. Finally, we conduct large-scale visualizations on a wide range of ViT variants, including DeiT, CoaT, ConViT, PiT, Swin, and Twin, to validate the effectiveness of our method.
Canary in a Coalmine: Better Membership Inference with Ensembled Adversarial Queries
Oct 19, 2022
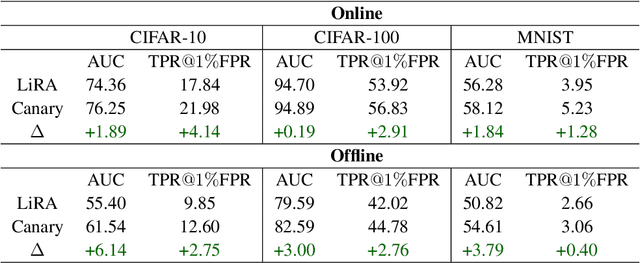
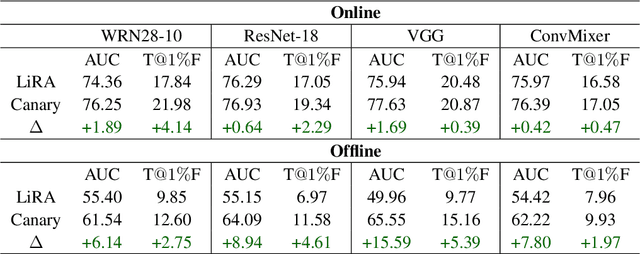
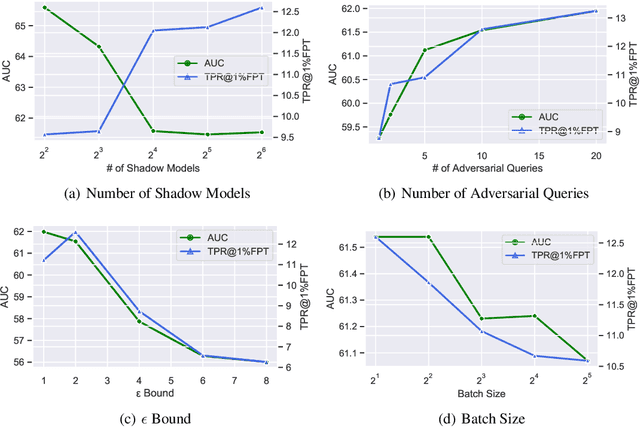
As industrial applications are increasingly automated by machine learning models, enforcing personal data ownership and intellectual property rights requires tracing training data back to their rightful owners. Membership inference algorithms approach this problem by using statistical techniques to discern whether a target sample was included in a model's training set. However, existing methods only utilize the unaltered target sample or simple augmentations of the target to compute statistics. Such a sparse sampling of the model's behavior carries little information, leading to poor inference capabilities. In this work, we use adversarial tools to directly optimize for queries that are discriminative and diverse. Our improvements achieve significantly more accurate membership inference than existing methods, especially in offline scenarios and in the low false-positive regime which is critical in legal settings. Code is available at https://github.com/YuxinWenRick/canary-in-a-coalmine.
Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise
Aug 19, 2022



Standard diffusion models involve an image transform -- adding Gaussian noise -- and an image restoration operator that inverts this degradation. We observe that the generative behavior of diffusion models is not strongly dependent on the choice of image degradation, and in fact an entire family of generative models can be constructed by varying this choice. Even when using completely deterministic degradations (e.g., blur, masking, and more), the training and test-time update rules that underlie diffusion models can be easily generalized to create generative models. The success of these fully deterministic models calls into question the community's understanding of diffusion models, which relies on noise in either gradient Langevin dynamics or variational inference, and paves the way for generalized diffusion models that invert arbitrary processes. Our code is available at https://github.com/arpitbansal297/Cold-Diffusion-Models
End-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation Without Overthinking
Feb 15, 2022


Machine learning systems perform well on pattern matching tasks, but their ability to perform algorithmic or logical reasoning is not well understood. One important reasoning capability is logical extrapolation, in which models trained only on small/simple reasoning problems can synthesize complex algorithms that scale up to large/complex problems at test time. Logical extrapolation can be achieved through recurrent systems, which can be iterated many times to solve difficult reasoning problems. We observe that this approach fails to scale to highly complex problems because behavior degenerates when many iterations are applied -- an issue we refer to as "overthinking." We propose a recall architecture that keeps an explicit copy of the problem instance in memory so that it cannot be forgotten. We also employ a progressive training routine that prevents the model from learning behaviors that are specific to iteration number and instead pushes it to learn behaviors that can be repeated indefinitely. These innovations prevent the overthinking problem, and enable recurrent systems to solve extremely hard logical extrapolation tasks, some requiring over 100K convolutional layers, without overthinking.
Datasets for Studying Generalization from Easy to Hard Examples
Aug 13, 2021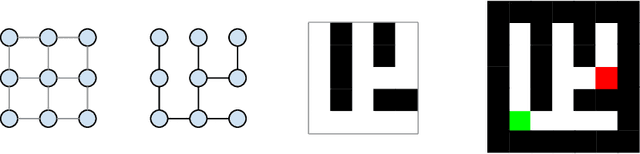
We describe new datasets for studying generalization from easy to hard examples.
Where do Models go Wrong? Parameter-Space Saliency Maps for Explainability
Aug 03, 2021

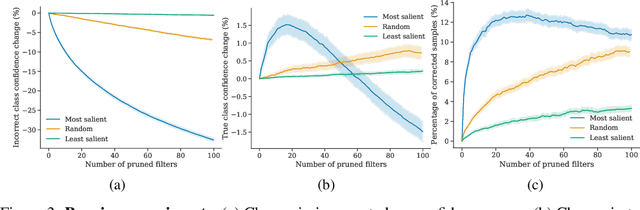

Conventional saliency maps highlight input features to which neural network predictions are highly sensitive. We take a different approach to saliency, in which we identify and analyze the network parameters, rather than inputs, which are responsible for erroneous decisions. We find that samples which cause similar parameters to malfunction are semantically similar. We also show that pruning the most salient parameters for a wrongly classified sample often improves model behavior. Furthermore, fine-tuning a small number of the most salient parameters on a single sample results in error correction on other samples that are misclassified for similar reasons. Based on our parameter saliency method, we also introduce an input-space saliency technique that reveals how image features cause specific network components to malfunction. Further, we rigorously validate the meaningfulness of our saliency maps on both the dataset and case-study levels.
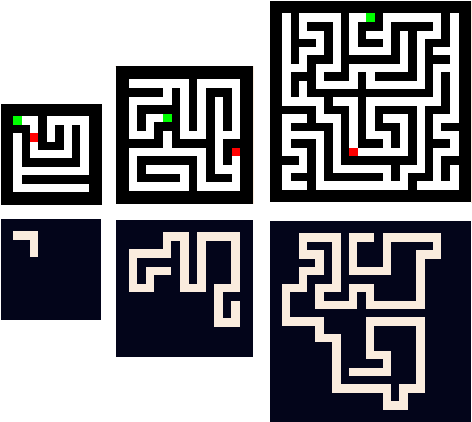
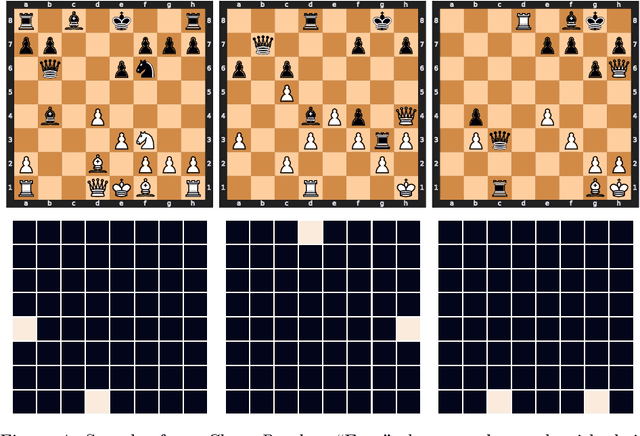
Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent Networks
Jun 08, 2021

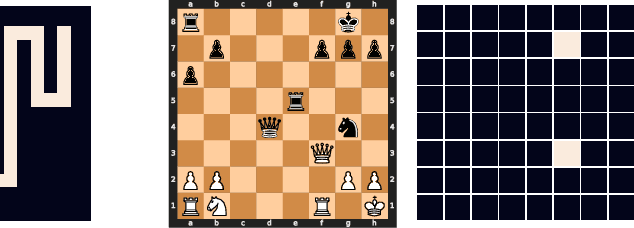

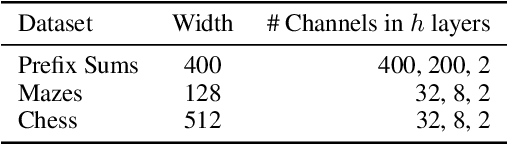
Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans possess the ability to extrapolate reasoning strategies learned on simple problems to solve harder examples, often by thinking for longer. For example, a person who has learned to solve small mazes can easily extend the very same search techniques to solve much larger mazes by spending more time. In computers, this behavior is often achieved through the use of algorithms, which scale to arbitrarily hard problem instances at the cost of more computation. In contrast, the sequential computing budget of feed-forward neural networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning to accommodate harder problems. In this work, we show that recurrent networks trained to solve simple problems with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference. We demonstrate this algorithmic behavior of recurrent networks on prefix sum computation, mazes, and chess. In all three domains, networks trained on simple problem instances are able to extend their reasoning abilities at test time simply by "thinking for longer."
DP-InstaHide: Provably Defusing Poisoning and Backdoor Attacks with Differentially Private Data Augmentations
Mar 02, 2021Data poisoning and backdoor attacks manipulate training data to induce security breaches in a victim model. These attacks can be provably deflected using differentially private (DP) training methods, although this comes with a sharp decrease in model performance. The InstaHide method has recently been proposed as an alternative to DP training that leverages supposed privacy properties of the mixup augmentation, although without rigorous guarantees. In this work, we show that strong data augmentations, such as mixup and random additive noise, nullify poison attacks while enduring only a small accuracy trade-off. To explain these finding, we propose a training method, DP-InstaHide, which combines the mixup regularizer with additive noise. A rigorous analysis of DP-InstaHide shows that mixup does indeed have privacy advantages, and that training with k-way mixup provably yields at least k times stronger DP guarantees than a naive DP mechanism. Because mixup (as opposed to noise) is beneficial to model performance, DP-InstaHide provides a mechanism for achieving stronger empirical performance against poisoning attacks than other known DP methods.
Strong Data Augmentation Sanitizes Poisoning and Backdoor Attacks Without an Accuracy Tradeoff
Nov 18, 2020


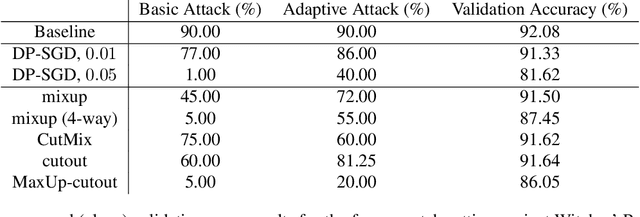
Data poisoning and backdoor attacks manipulate victim models by maliciously modifying training data. In light of this growing threat, a recent survey of industry professionals revealed heightened fear in the private sector regarding data poisoning. Many previous defenses against poisoning either fail in the face of increasingly strong attacks, or they significantly degrade performance. However, we find that strong data augmentations, such as mixup and CutMix, can significantly diminish the threat of poisoning and backdoor attacks without trading off performance. We further verify the effectiveness of this simple defense against adaptive poisoning methods, and we compare to baselines including the popular differentially private SGD (DP-SGD) defense. In the context of backdoors, CutMix greatly mitigates the attack while simultaneously increasing validation accuracy by 9%.