 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Performance-Driven Benchmark for Feature Selection in Tabular Deep Learning
Nov 10, 2023



Academic tabular benchmarks often contain small sets of curated features. In contrast, data scientists typically collect as many features as possible into their datasets, and even engineer new features from existing ones. To prevent overfitting in subsequent downstream modeling, practitioners commonly use automated feature selection methods that identify a reduced subset of informative features. Existing benchmarks for tabular feature selection consider classical downstream models, toy synthetic datasets, or do not evaluate feature selectors on the basis of downstream performance. Motivated by the increasing popularity of tabular deep learning, we construct a challenging feature selection benchmark evaluated on downstream neural networks including transformers, using real datasets and multiple methods for generating extraneous features. We also propose an input-gradient-based analogue of Lasso for neural networks that outperforms classical feature selection methods on challenging problems such as selecting from corrupted or second-order features.
Transfer Learning with Deep Tabular Models
Jun 30, 2022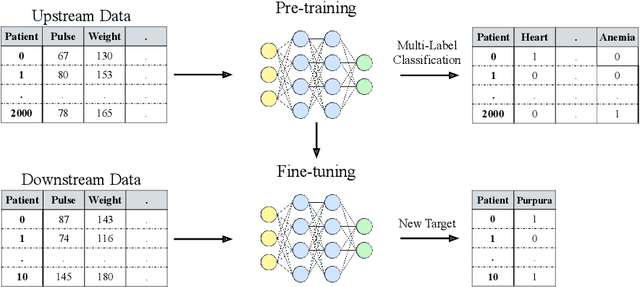

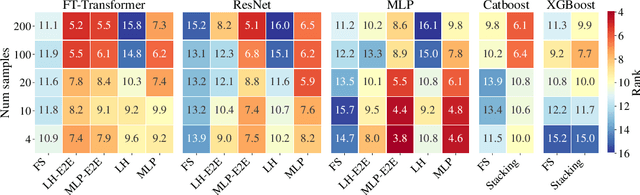

Recent work on deep learning for tabular data demonstrates the strong performance of deep tabular models, often bridging the gap between gradient boosted decision trees and neural networks. Accuracy aside, a major advantage of neural models is that they learn reusable features and are easily fine-tuned in new domains. This property is often exploited in computer vision and natural language applications, where transfer learning is indispensable when task-specific training data is scarce. In this work, we demonstrate that upstream data gives tabular neural networks a decisive advantage over widely used GBDT models. We propose a realistic medical diagnosis benchmark for tabular transfer learning, and we present a how-to guide for using upstream data to boost performance with a variety of tabular neural network architectures. Finally, we propose a pseudo-feature method for cases where the upstream and downstream feature sets differ, a tabular-specific problem widespread in real-world applications. Our code is available at https://github.com/LevinRoman/tabular-transfer-learning .
Where do Models go Wrong? Parameter-Space Saliency Maps for Explainability
Aug 03, 2021

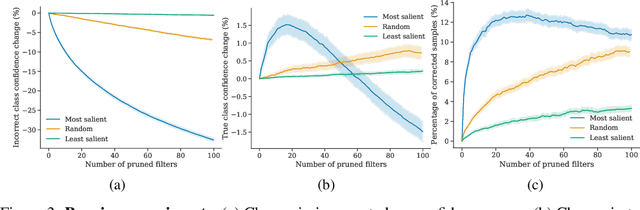

Conventional saliency maps highlight input features to which neural network predictions are highly sensitive. We take a different approach to saliency, in which we identify and analyze the network parameters, rather than inputs, which are responsible for erroneous decisions. We find that samples which cause similar parameters to malfunction are semantically similar. We also show that pruning the most salient parameters for a wrongly classified sample often improves model behavior. Furthermore, fine-tuning a small number of the most salient parameters on a single sample results in error correction on other samples that are misclassified for similar reasons. Based on our parameter saliency method, we also introduce an input-space saliency technique that reveals how image features cause specific network components to malfunction. Further, we rigorously validate the meaningfulness of our saliency maps on both the dataset and case-study levels.
Echo Chambers in Collaborative Filtering Based Recommendation Systems
Nov 08, 2020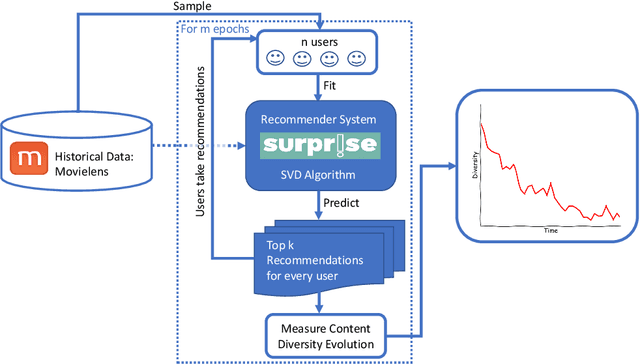
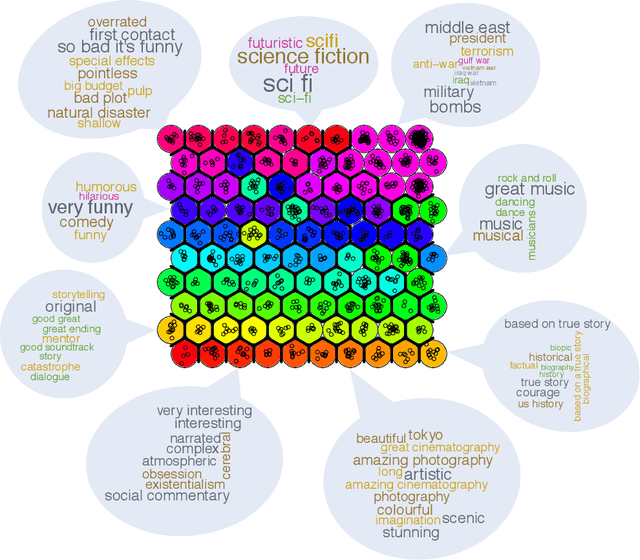
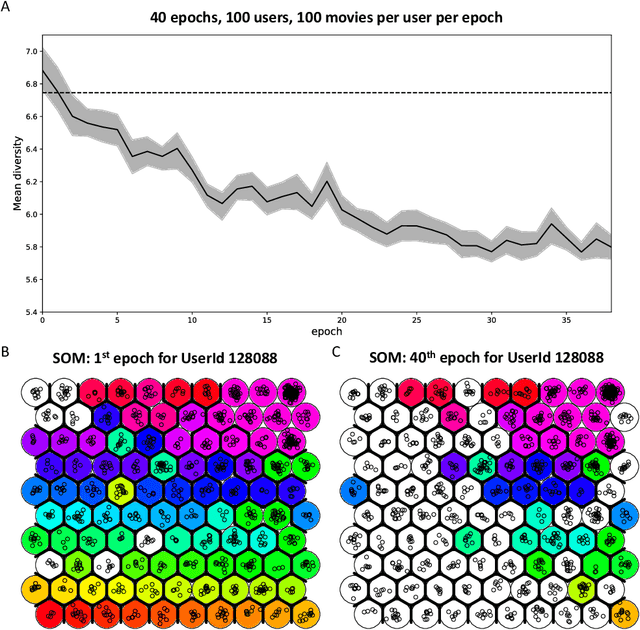
Recommendation systems underpin the serving of nearly all online content in the modern age. From Youtube and Netflix recommendations, to Facebook feeds and Google searches, these systems are designed to filter content to the predicted preferences of users. Recently, these systems have faced growing criticism with respect to their impact on content diversity, social polarization, and the health of public discourse. In this work we simulate the recommendations given by collaborative filtering algorithms on users in the MovieLens data set. We find that prolonged exposure to system-generated recommendations substantially decreases content diversity, moving individual users into "echo-chambers" characterized by a narrow range of content. Furthermore, our work suggests that once these echo-chambers have been established, it is difficult for an individual user to break out by manipulating solely their own rating vector.