 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSqueeze: Dynamic Patching for Efficient Time Series Forecasting
Mar 11, 2026Transformer-based time series foundation models face a fundamental trade-off in choice of tokenization: point-wise embeddings preserve temporal fidelity but scale poorly with sequence length, whereas fixed-length patching improves efficiency by imposing uniform boundaries that may disrupt natural transitions and blur informative local dynamics. In order to address these limitations, we introduce TimeSqueeze, a dynamic patching mechanism that adaptively selects patch boundaries within each sequence based on local signal complexity. TimeSqueeze first applies a lightweight state-space encoder to extract full-resolution point-wise features, then performs content-aware segmentation by allocating short patches to information-dense regions and long patches to smooth or redundant segments. This variable-resolution compression preserves critical temporal structure while substantially reducing the token sequence presented to the Transformer backbone. Specifically for large-scale pretraining, TimeSqueeze attains up to 20x faster convergence and 8x higher data efficiency compared to equivalent point-token baselines. Experiments across long-horizon forecasting benchmarks show that TimeSqueeze consistently outperforms comparable architectures that use either point-wise tokenization or fixed-size patching.
Revisiting RAG Retrievers: An Information Theoretic Benchmark
Feb 25, 2026Retrieval-Augmented Generation (RAG) systems rely critically on the retriever module to surface relevant context for large language models. Although numerous retrievers have recently been proposed, each built on different ranking principles such as lexical matching, dense embeddings, or graph citations, there remains a lack of systematic understanding of how these mechanisms differ and overlap. Existing benchmarks primarily compare entire RAG pipelines or introduce new datasets, providing little guidance on selecting or combining retrievers themselves. Those that do compare retrievers directly use a limited set of evaluation tools which fail to capture complementary and overlapping strengths. This work presents MIGRASCOPE, a Mutual Information based RAG Retriever Analysis Scope. We revisit state-of-the-art retrievers and introduce principled metrics grounded in information and statistical estimation theory to quantify retrieval quality, redundancy, synergy, and marginal contribution. We further show that if chosen carefully, an ensemble of retrievers outperforms any single retriever. We leverage the developed tools over major RAG corpora to provide unique insights on contribution levels of the state-of-the-art retrievers. Our findings provide a fresh perspective on the structure of modern retrieval techniques and actionable guidance for designing robust and efficient RAG systems.
PersonaLedger: Generating Realistic Financial Transactions with Persona Conditioned LLMs and Rule Grounded Feedback
Jan 06, 2026Strict privacy regulations limit access to real transaction data, slowing open research in financial AI. Synthetic data can bridge this gap, but existing generators do not jointly achieve behavioral diversity and logical groundedness. Rule-driven simulators rely on hand-crafted workflows and shallow stochasticity, which miss the richness of human behavior. Learning-based generators such as GANs capture correlations yet often violate hard financial constraints and still require training on private data. We introduce PersonaLedger, a generation engine that uses a large language model conditioned on rich user personas to produce diverse transaction streams, coupled with an expert configurable programmatic engine that maintains correctness. The LLM and engine interact in a closed loop: after each event, the engine updates the user state, enforces financial rules, and returns a context aware "nextprompt" that guides the LLM toward feasible next actions. With this engine, we create a public dataset of 30 million transactions from 23,000 users and a benchmark suite with two tasks, illiquidity classification and identity theft segmentation. PersonaLedger offers a realistic, privacy preserving resource that supports rigorous evaluation of forecasting and anomaly detection models. PersonaLedger offers the community a rich, realistic, and privacy preserving resource -- complete with code, rules, and generation logs -- to accelerate innovation in financial AI and enable rigorous, reproducible evaluation.
BEDTime: A Unified Benchmark for Automatically Describing Time Series
Sep 05, 2025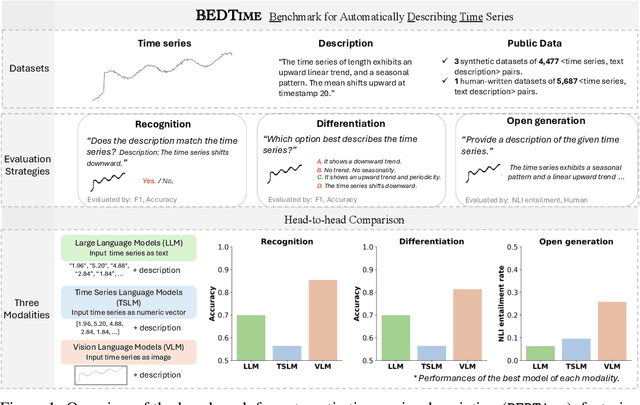

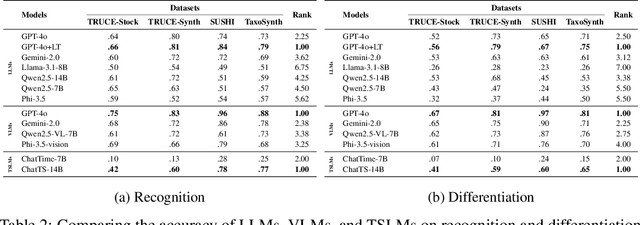
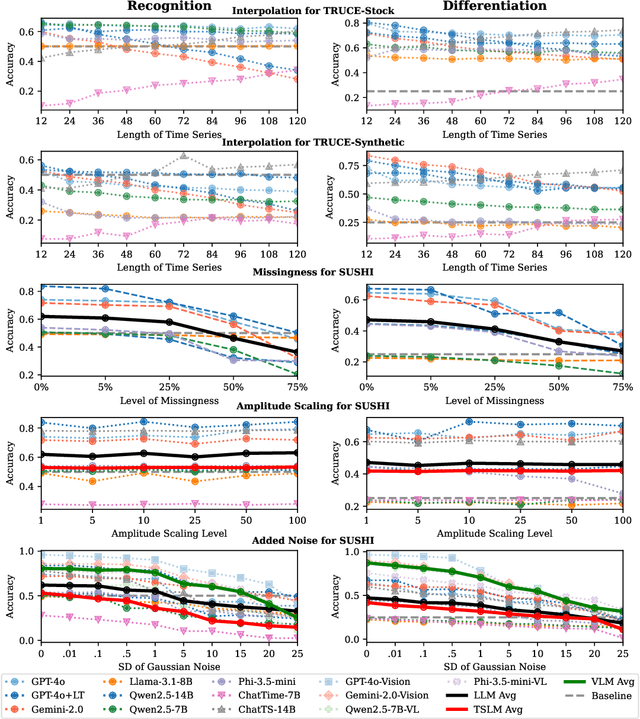
Many recent studies have proposed general-purpose foundation models designed for a variety of time series analysis tasks. While several established datasets already exist for evaluating these models, previous works frequently introduce their models in conjunction with new datasets, limiting opportunities for direct, independent comparisons and obscuring insights into the relative strengths of different methods. Additionally, prior evaluations often cover numerous tasks simultaneously, assessing a broad range of model abilities without clearly pinpointing which capabilities contribute to overall performance. To address these gaps, we formalize and evaluate 3 tasks that test a model's ability to describe time series using generic natural language: (1) recognition (True/False question-answering), (2) differentiation (multiple choice question-answering), and (3) generation (open-ended natural language description). We then unify 4 recent datasets to enable head-to-head model comparisons on each task. Experimentally, in evaluating 13 state-of-the-art language, vision--language, and time series--language models, we find that (1) popular language-only methods largely underperform, indicating a need for time series-specific architectures, (2) VLMs are quite successful, as expected, identifying the value of vision models for these tasks and (3) pretrained multimodal time series--language models successfully outperform LLMs, but still have significant room for improvement. We also find that all approaches exhibit clear fragility in a range of robustness tests. Overall, our benchmark provides a standardized evaluation on a task necessary for time series reasoning systems.
Out-of-Distribution Detection Methods Answer the Wrong Questions
Jul 02, 2025To detect distribution shifts and improve model safety, many out-of-distribution (OOD) detection methods rely on the predictive uncertainty or features of supervised models trained on in-distribution data. In this paper, we critically re-examine this popular family of OOD detection procedures, and we argue that these methods are fundamentally answering the wrong questions for OOD detection. There is no simple fix to this misalignment, since a classifier trained only on in-distribution classes cannot be expected to identify OOD points; for instance, a cat-dog classifier may confidently misclassify an airplane if it contains features that distinguish cats from dogs, despite generally appearing nothing alike. We find that uncertainty-based methods incorrectly conflate high uncertainty with being OOD, while feature-based methods incorrectly conflate far feature-space distance with being OOD. We show how these pathologies manifest as irreducible errors in OOD detection and identify common settings where these methods are ineffective. Additionally, interventions to improve OOD detection such as feature-logit hybrid methods, scaling of model and data size, epistemic uncertainty representation, and outlier exposure also fail to address this fundamental misalignment in objectives. We additionally consider unsupervised density estimation and generative models for OOD detection, which we show have their own fundamental limitations.
Explain What You Mean: Intent Augmented Knowledge Graph Recommender Built With LLM
May 16, 2025Interaction sparsity is the primary obstacle for recommendation systems. Sparsity manifests in environments with disproportional cardinality of groupings of entities, such as users and products in an online marketplace. It also is found for newly introduced entities, described as the cold-start problem. Recent efforts to mitigate this sparsity issue shifts the performance bottleneck to other areas in the computational pipeline. Those that focus on enriching sparse representations with connectivity data from other external sources propose methods that are resource demanding and require careful domain expert aided addition of this newly introduced data. Others that turn to Large Language Model (LLM) based recommenders will quickly encounter limitations surrounding data quality and availability. In this work, we propose LLM-based Intent Knowledge Graph Recommender (IKGR), a novel framework that leverages retrieval-augmented generation and an encoding approach to construct and densify a knowledge graph. IKGR learns latent user-item affinities from an interaction knowledge graph and further densifies it through mutual intent connectivity. This addresses sparsity issues and allows the model to make intent-grounded recommendations with an interpretable embedding translation layer. Through extensive experiments on real-world datasets, we demonstrate that IKGR overcomes knowledge gaps and achieves substantial gains over state-of-the-art baselines on both publicly available and our internal recommendation datasets.
Just How Flexible are Neural Networks in Practice?
Jun 17, 2024It is widely believed that a neural network can fit a training set containing at least as many samples as it has parameters, underpinning notions of overparameterized and underparameterized models. In practice, however, we only find solutions accessible via our training procedure, including the optimizer and regularizers, limiting flexibility. Moreover, the exact parameterization of the function class, built into an architecture, shapes its loss surface and impacts the minima we find. In this work, we examine the ability of neural networks to fit data in practice. Our findings indicate that: (1) standard optimizers find minima where the model can only fit training sets with significantly fewer samples than it has parameters; (2) convolutional networks are more parameter-efficient than MLPs and ViTs, even on randomly labeled data; (3) while stochastic training is thought to have a regularizing effect, SGD actually finds minima that fit more training data than full-batch gradient descent; (4) the difference in capacity to fit correctly labeled and incorrectly labeled samples can be predictive of generalization; (5) ReLU activation functions result in finding minima that fit more data despite being designed to avoid vanishing and exploding gradients in deep architectures.
Simplifying Neural Network Training Under Class Imbalance
Dec 05, 2023



Real-world datasets are often highly class-imbalanced, which can adversely impact the performance of deep learning models. The majority of research on training neural networks under class imbalance has focused on specialized loss functions, sampling techniques, or two-stage training procedures. Notably, we demonstrate that simply tuning existing components of standard deep learning pipelines, such as the batch size, data augmentation, optimizer, and label smoothing, can achieve state-of-the-art performance without any such specialized class imbalance methods. We also provide key prescriptions and considerations for training under class imbalance, and an understanding of why imbalance methods succeed or fail.
A Performance-Driven Benchmark for Feature Selection in Tabular Deep Learning
Nov 10, 2023



Academic tabular benchmarks often contain small sets of curated features. In contrast, data scientists typically collect as many features as possible into their datasets, and even engineer new features from existing ones. To prevent overfitting in subsequent downstream modeling, practitioners commonly use automated feature selection methods that identify a reduced subset of informative features. Existing benchmarks for tabular feature selection consider classical downstream models, toy synthetic datasets, or do not evaluate feature selectors on the basis of downstream performance. Motivated by the increasing popularity of tabular deep learning, we construct a challenging feature selection benchmark evaluated on downstream neural networks including transformers, using real datasets and multiple methods for generating extraneous features. We also propose an input-gradient-based analogue of Lasso for neural networks that outperforms classical feature selection methods on challenging problems such as selecting from corrupted or second-order features.
From Explanation to Action: An End-to-End Human-in-the-loop Framework for Anomaly Reasoning and Management
Apr 06, 2023



Anomalies are often indicators of malfunction or inefficiency in various systems such as manufacturing, healthcare, finance, surveillance, to name a few. While the literature is abundant in effective detection algorithms due to this practical relevance, autonomous anomaly detection is rarely used in real-world scenarios. Especially in high-stakes applications, a human-in-the-loop is often involved in processes beyond detection such as verification and troubleshooting. In this work, we introduce ALARM (for Analyst-in-the-Loop Anomaly Reasoning and Management); an end-to-end framework that supports the anomaly mining cycle comprehensively, from detection to action. Besides unsupervised detection of emerging anomalies, it offers anomaly explanations and an interactive GUI for human-in-the-loop processes -- visual exploration, sense-making, and ultimately action-taking via designing new detection rules -- that help close ``the loop'' as the new rules complement rule-based supervised detection, typical of many deployed systems in practice. We demonstrate \method's efficacy through a series of case studies with fraud analysts from the financial industry.