 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASED-XAI: Breaking Ablation Studies Down for Explainable Artificial Intelligence
Jul 12, 2022

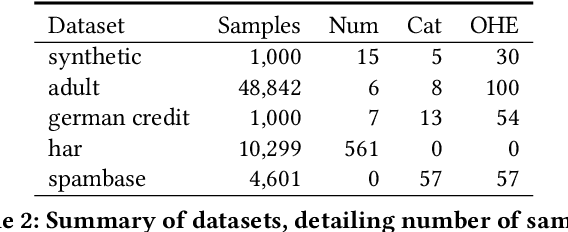
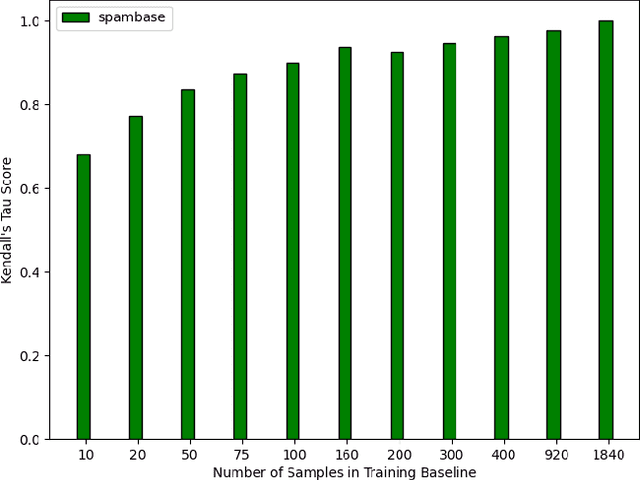
Explainable artificial intelligence (XAI) methods lack ground truth. In its place, method developers have relied on axioms to determine desirable properties for their explanations' behavior. For high stakes uses of machine learning that require explainability, it is not sufficient to rely on axioms as the implementation, or its usage, can fail to live up to the ideal. As a result, there exists active research on validating the performance of XAI methods. The need for validation is especially magnified in domains with a reliance on XAI. A procedure frequently used to assess their utility, and to some extent their fidelity, is an ablation study. By perturbing the input variables in rank order of importance, the goal is to assess the sensitivity of the model's performance. Perturbing important variables should correlate with larger decreases in measures of model capability than perturbing less important features. While the intent is clear, the actual implementation details have not been studied rigorously for tabular data. Using five datasets, three XAI methods, four baselines, and three perturbations, we aim to show 1) how varying perturbations and adding simple guardrails can help to avoid potentially flawed conclusions, 2) how treatment of categorical variables is an important consideration in both post-hoc explainability and ablation studies, and 3) how to identify useful baselines for XAI methods and viable perturbations for ablation studies.