 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline for Predicting Events with Auto-Regressive Tabular Transformers
Oct 14, 2024Many real-world applications of tabular data involve using historic events to predict properties of new ones, for example whether a credit card transaction is fraudulent or what rating a customer will assign a product on a retail platform. Existing approaches to event prediction include costly, brittle, and application-dependent techniques such as time-aware positional embeddings, learned row and field encodings, and oversampling methods for addressing class imbalance. Moreover, these approaches often assume specific use-cases, for example that we know the labels of all historic events or that we only predict a pre-specified label and not the data's features themselves. In this work, we propose a simple but flexible baseline using standard autoregressive LLM-style transformers with elementary positional embeddings and a causal language modeling objective. Our baseline outperforms existing approaches across popular datasets and can be employed for various use-cases. We demonstrate that the same model can predict labels, impute missing values, or model event sequences.
Understanding the Effect of using Semantically Meaningful Tokens for Visual Representation Learning
May 26, 2024



Vision transformers have established a precedent of patchifying images into uniformly-sized chunks before processing. We hypothesize that this design choice may limit models in learning comprehensive and compositional representations from visual data. This paper explores the notion of providing semantically-meaningful visual tokens to transformer encoders within a vision-language pre-training framework. Leveraging off-the-shelf segmentation and scene-graph models, we extract representations of instance segmentation masks (referred to as tangible tokens) and relationships and actions (referred to as intangible tokens). Subsequently, we pre-train a vision-side transformer by incorporating these newly extracted tokens and aligning the resultant embeddings with caption embeddings from a text-side encoder. To capture the structural and semantic relationships among visual tokens, we introduce additive attention weights, which are used to compute self-attention scores. Our experiments on COCO demonstrate notable improvements over ViTs in learned representation quality across text-to-image (+47%) and image-to-text retrieval (+44%) tasks. Furthermore, we showcase the advantages on compositionality benchmarks such as ARO (+18%) and Winoground (+10%).
BASED-XAI: Breaking Ablation Studies Down for Explainable Artificial Intelligence
Jul 12, 2022

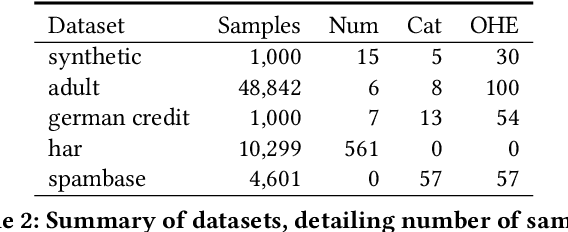
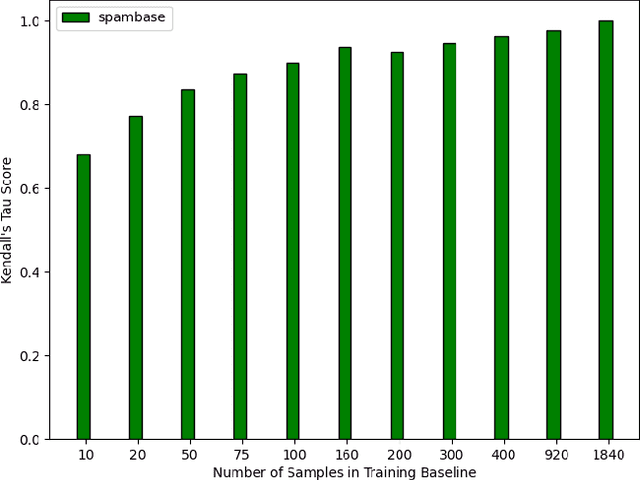
Explainable artificial intelligence (XAI) methods lack ground truth. In its place, method developers have relied on axioms to determine desirable properties for their explanations' behavior. For high stakes uses of machine learning that require explainability, it is not sufficient to rely on axioms as the implementation, or its usage, can fail to live up to the ideal. As a result, there exists active research on validating the performance of XAI methods. The need for validation is especially magnified in domains with a reliance on XAI. A procedure frequently used to assess their utility, and to some extent their fidelity, is an ablation study. By perturbing the input variables in rank order of importance, the goal is to assess the sensitivity of the model's performance. Perturbing important variables should correlate with larger decreases in measures of model capability than perturbing less important features. While the intent is clear, the actual implementation details have not been studied rigorously for tabular data. Using five datasets, three XAI methods, four baselines, and three perturbations, we aim to show 1) how varying perturbations and adding simple guardrails can help to avoid potentially flawed conclusions, 2) how treatment of categorical variables is an important consideration in both post-hoc explainability and ablation studies, and 3) how to identify useful baselines for XAI methods and viable perturbations for ablation studies.
Counterfactual Explanations via Latent Space Projection and Interpolation
Dec 02, 2021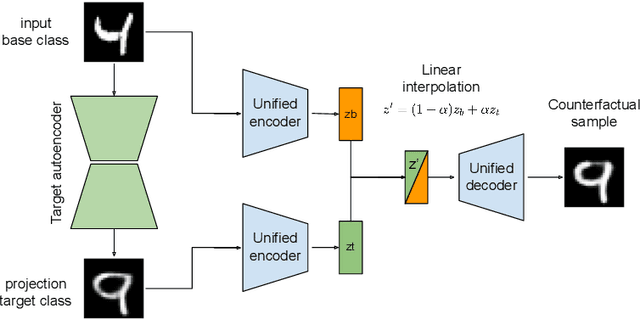

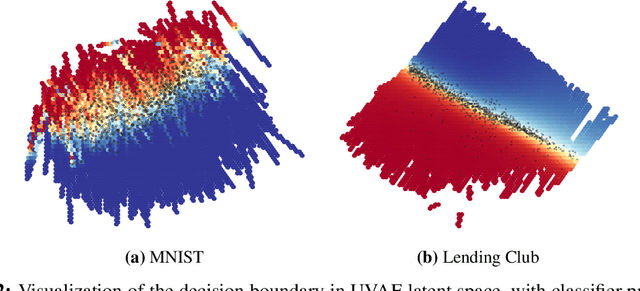

Counterfactual explanations represent the minimal change to a data sample that alters its predicted classification, typically from an unfavorable initial class to a desired target class. Counterfactuals help answer questions such as "what needs to change for this application to get accepted for a loan?". A number of recently proposed approaches to counterfactual generation give varying definitions of "plausible" counterfactuals and methods to generate them. However, many of these methods are computationally intensive and provide unconvincing explanations. Here we introduce SharpShooter, a method for binary classification that starts by creating a projected version of the input that classifies as the target class. Counterfactual candidates are then generated in latent space on the interpolation line between the input and its projection. We then demonstrate that our framework translates core characteristics of a sample to its counterfactual through the use of learned representations. Furthermore, we show that SharpShooter is competitive across common quality metrics on tabular and image datasets while being orders of magnitude faster than two comparable methods and excels at measures of realism, making it well-suited for high velocity machine learning applications which require timely explanations.
Dynamic Customer Embeddings for Financial Service Applications
Jun 22, 2021



As financial services (FS) companies have experienced drastic technology driven changes, the availability of new data streams provides the opportunity for more comprehensive customer understanding. We propose Dynamic Customer Embeddings (DCE), a framework that leverages customers' digital activity and a wide range of financial context to learn dense representations of customers in the FS industry. Our method examines customer actions and pageviews within a mobile or web digital session, the sequencing of the sessions themselves, and snapshots of common financial features across our organization at the time of login. We test our customer embeddings using real world data in three prediction problems: 1) the intent of a customer in their next digital session, 2) the probability of a customer calling the call centers after a session, and 3) the probability of a digital session to be fraudulent. DCE showed performance lift in all three downstream problems.
Latent-CF: A Simple Baseline for Reverse Counterfactual Explanations
Dec 16, 2020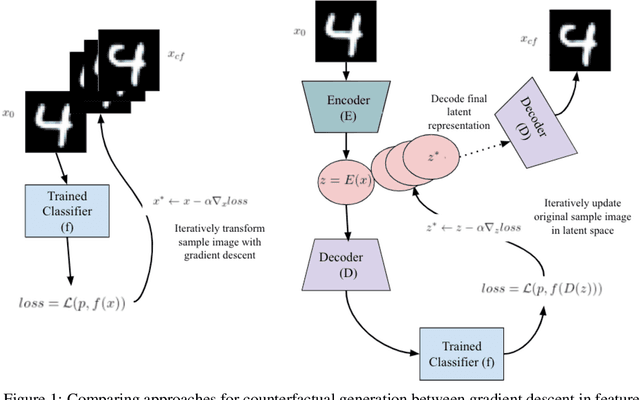


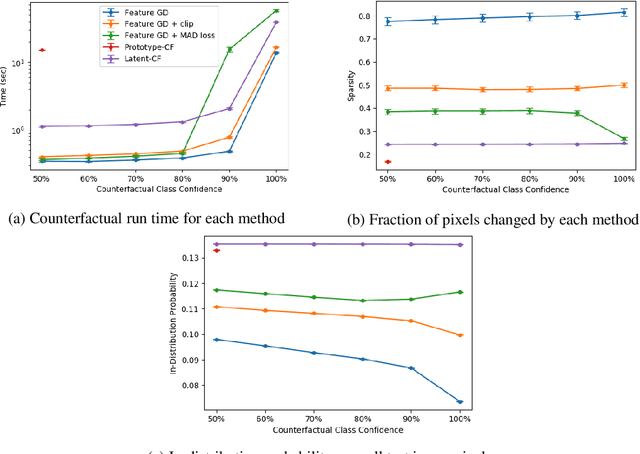
In the environment of fair lending laws and the General Data Protection Regulation (GDPR), the ability to explain a model's prediction is of paramount importance. High quality explanations are the first step in assessing fairness. Counterfactuals are valuable tools for explainability. They provide actionable, comprehensible explanations for the individual who is subject to decisions made from the prediction. It is important to find a baseline for producing them. We propose a simple method for generating counterfactuals by using gradient descent to search in the latent space of an autoencoder and benchmark our method against approaches that search for counterfactuals in feature space. Additionally, we implement metrics to concretely evaluate the quality of the counterfactuals. We show that latent space counterfactual generation strikes a balance between the speed of basic feature gradient descent methods and the sparseness and authenticity of counterfactuals generated by more complex feature space oriented techniques.
Visual Natural Language Query Auto-Completion for Estimating Instance Probabilities
Oct 10, 2019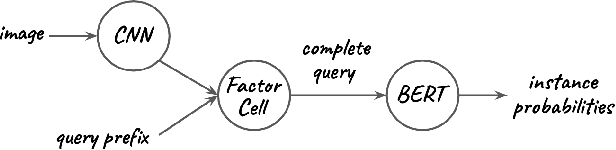

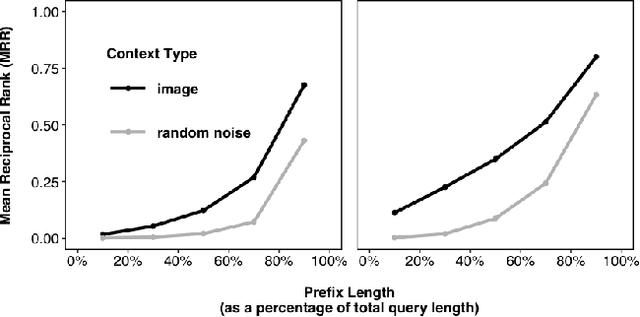
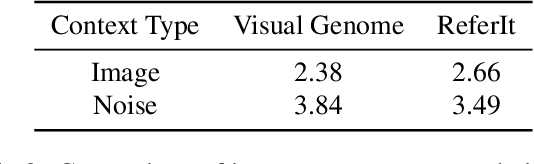
We present a new task of query auto-completion for estimating instance probabilities. We complete a user query prefix conditioned upon an image. Given the complete query, we fine tune a BERT embedding for estimating probabilities of a broad set of instances. The resulting instance probabilities are used for selection while being agnostic to the segmentation or attention mechanism. Our results demonstrate that auto-completion using both language and vision performs better than using only language, and that fine tuning a BERT embedding allows to efficiently rank instances in the image. In the spirit of reproducible research we make our data, models, and code available.