 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Multivariate Time Series Forecasting Using Tabular Prior Fitted Networks
Apr 09, 2026Tabular foundation models, particularly Prior-data Fitted Networks like TabPFN have emerged as the leading contender in a myriad of tasks ranging from data imputation to label prediction on the tabular data format surpassing the historical successes of tree-based models. This has led to investigations on their applicability to forecasting time series data which can be formulated as a tabular problem. While recent work to this end has displayed positive results, most works have limited their treatment of multivariate time series problems to several independent univariate time series forecasting subproblems, thus ignoring any inter-channel interactions. Overcoming this limitation, we introduce a generally applicable framework for multivariate time series forecasting using tabular foundation models. We achieve this by recasting the multivariate time series forecasting problem as a series of scalar regression problems which can then be solved zero-shot by any tabular foundation model with regression capabilities. We present results of our method using the TabPFN-TS backbone and compare performance with the current state of the art tabular methods.
EnsemW2S: Enhancing Weak-to-Strong Generalization with Large Language Model Ensembles
May 28, 2025With Large Language Models (LLMs) rapidly approaching and potentially surpassing human-level performance, it has become imperative to develop approaches capable of effectively supervising and enhancing these powerful models using smaller, human-level models exposed to only human-level data. We address this critical weak-to-strong (W2S) generalization challenge by proposing a novel method aimed at improving weak experts, by training on the same limited human-level data, enabling them to generalize to complex, super-human-level tasks. Our approach, called \textbf{EnsemW2S}, employs a token-level ensemble strategy that iteratively combines multiple weak experts, systematically addressing the shortcomings identified in preceding iterations. By continuously refining these weak models, we significantly enhance their collective ability to supervise stronger student models. We extensively evaluate the generalization performance of both the ensemble of weak experts and the subsequent strong student model across in-distribution (ID) and out-of-distribution (OOD) datasets. For OOD, we specifically introduce question difficulty as an additional dimension for defining distributional shifts. Our empirical results demonstrate notable improvements, achieving 4\%, and 3.2\% improvements on ID datasets and, upto 6\% and 2.28\% on OOD datasets for experts and student models respectively, underscoring the effectiveness of our proposed method in advancing W2S generalization.
A Simple Baseline for Predicting Events with Auto-Regressive Tabular Transformers
Oct 14, 2024Many real-world applications of tabular data involve using historic events to predict properties of new ones, for example whether a credit card transaction is fraudulent or what rating a customer will assign a product on a retail platform. Existing approaches to event prediction include costly, brittle, and application-dependent techniques such as time-aware positional embeddings, learned row and field encodings, and oversampling methods for addressing class imbalance. Moreover, these approaches often assume specific use-cases, for example that we know the labels of all historic events or that we only predict a pre-specified label and not the data's features themselves. In this work, we propose a simple but flexible baseline using standard autoregressive LLM-style transformers with elementary positional embeddings and a causal language modeling objective. Our baseline outperforms existing approaches across popular datasets and can be employed for various use-cases. We demonstrate that the same model can predict labels, impute missing values, or model event sequences.
Searching for Efficient Linear Layers over a Continuous Space of Structured Matrices
Oct 03, 2024



Dense linear layers are the dominant computational bottleneck in large neural networks, presenting a critical need for more efficient alternatives. Previous efforts focused on a small number of hand-crafted structured matrices and neglected to investigate whether these structures can surpass dense layers in terms of compute-optimal scaling laws when both the model size and training examples are optimally allocated. In this work, we present a unifying framework that enables searching among all linear operators expressible via an Einstein summation. This framework encompasses many previously proposed structures, such as low-rank, Kronecker, Tensor-Train, Block Tensor-Train (BTT), and Monarch, along with many novel structures. To analyze the framework, we develop a taxonomy of all such operators based on their computational and algebraic properties and show that differences in the compute-optimal scaling laws are mostly governed by a small number of variables that we introduce. Namely, a small $\omega$ (which measures parameter sharing) and large $\psi$ (which measures the rank) reliably led to better scaling laws. Guided by the insight that full-rank structures that maximize parameters per unit of compute perform the best, we propose BTT-MoE, a novel Mixture-of-Experts (MoE) architecture obtained by sparsifying computation in the BTT structure. In contrast to the standard sparse MoE for each entire feed-forward network, BTT-MoE learns an MoE in every single linear layer of the model, including the projection matrices in the attention blocks. We find BTT-MoE provides a substantial compute-efficiency gain over dense layers and standard MoE.
Adapting Self-Supervised Representations to Multi-Domain Setups
Sep 07, 2023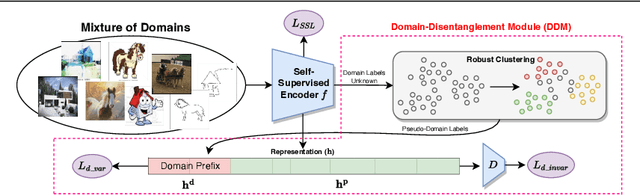
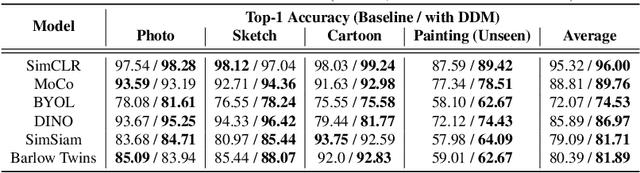
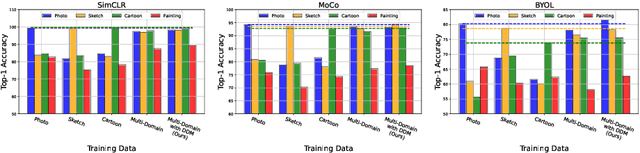

Current state-of-the-art self-supervised approaches, are effective when trained on individual domains but show limited generalization on unseen domains. We observe that these models poorly generalize even when trained on a mixture of domains, making them unsuitable to be deployed under diverse real-world setups. We therefore propose a general-purpose, lightweight Domain Disentanglement Module (DDM) that can be plugged into any self-supervised encoder to effectively perform representation learning on multiple, diverse domains with or without shared classes. During pre-training according to a self-supervised loss, DDM enforces a disentanglement in the representation space by splitting it into a domain-variant and a domain-invariant portion. When domain labels are not available, DDM uses a robust clustering approach to discover pseudo-domains. We show that pre-training with DDM can show up to 3.5% improvement in linear probing accuracy on state-of-the-art self-supervised models including SimCLR, MoCo, BYOL, DINO, SimSiam and Barlow Twins on multi-domain benchmarks including PACS, DomainNet and WILDS. Models trained with DDM show significantly improved generalization (7.4%) to unseen domains compared to baselines. Therefore, DDM can efficiently adapt self-supervised encoders to provide high-quality, generalizable representations for diverse multi-domain data.
Identifying Interpretable Subspaces in Image Representations
Jul 20, 2023We propose Automatic Feature Explanation using Contrasting Concepts (FALCON), an interpretability framework to explain features of image representations. For a target feature, FALCON captions its highly activating cropped images using a large captioning dataset (like LAION-400m) and a pre-trained vision-language model like CLIP. Each word among the captions is scored and ranked leading to a small number of shared, human-understandable concepts that closely describe the target feature. FALCON also applies contrastive interpretation using lowly activating (counterfactual) images, to eliminate spurious concepts. Although many existing approaches interpret features independently, we observe in state-of-the-art self-supervised and supervised models, that less than 20% of the representation space can be explained by individual features. We show that features in larger spaces become more interpretable when studied in groups and can be explained with high-order scoring concepts through FALCON. We discuss how extracted concepts can be used to explain and debug failures in downstream tasks. Finally, we present a technique to transfer concepts from one (explainable) representation space to another unseen representation space by learning a simple linear transformation.