 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Self Paced Curriculum Reinforcement Learning
Nov 12, 2025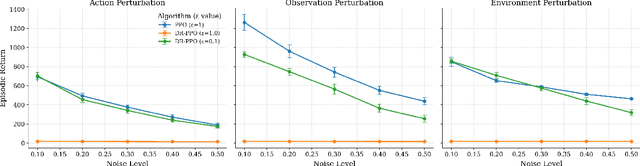
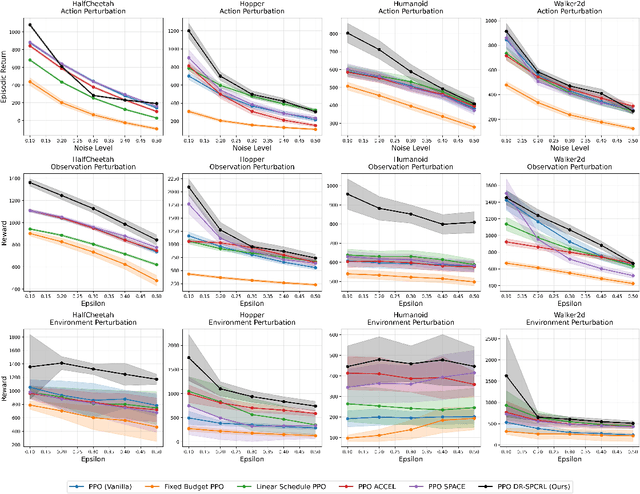
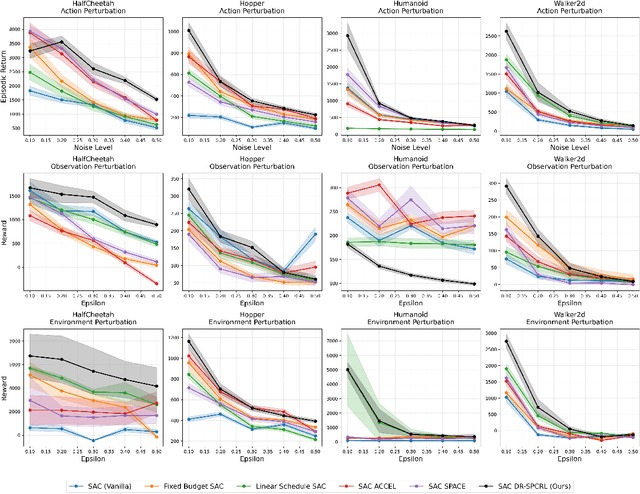
A central challenge in reinforcement learning is that policies trained in controlled environments often fail under distribution shifts at deployment into real-world environments. Distributionally Robust Reinforcement Learning (DRRL) addresses this by optimizing for worst-case performance within an uncertainty set defined by a robustness budget $ε$. However, fixing $ε$ results in a tradeoff between performance and robustness: small values yield high nominal performance but weak robustness, while large values can result in instability and overly conservative policies. We propose Distributionally Robust Self-Paced Curriculum Reinforcement Learning (DR-SPCRL), a method that overcomes this limitation by treating $ε$ as a continuous curriculum. DR-SPCRL adaptively schedules the robustness budget according to the agent's progress, enabling a balance between nominal and robust performance. Empirical results across multiple environments demonstrate that DR-SPCRL not only stabilizes training but also achieves a superior robustness-performance trade-off, yielding an average 11.8\% increase in episodic return under varying perturbations compared to fixed or heuristic scheduling strategies, and achieving approximately 1.9$\times$ the performance of the corresponding nominal RL algorithms.
Primal-Only Actor Critic Algorithm for Robust Constrained Average Cost MDPs
Nov 07, 2025In this work, we study the problem of finding robust and safe policies in Robust Constrained Average-Cost Markov Decision Processes (RCMDPs). A key challenge in this setting is the lack of strong duality, which prevents the direct use of standard primal-dual methods for constrained RL. Additional difficulties arise from the average-cost setting, where the Robust Bellman operator is not a contraction under any norm. To address these challenges, we propose an actor-critic algorithm for Average-Cost RCMDPs. We show that our method achieves both \(ε\)-feasibility and \(ε\)-optimality, and we establish a sample complexities of \(\tilde{O}\left(ε^{-4}\right)\) and \(\tilde{O}\left(ε^{-6}\right)\) with and without slackness assumption, which is comparable to the discounted setting.
cMALC-D: Contextual Multi-Agent LLM-Guided Curriculum Learning with Diversity-Based Context Blending
Aug 28, 2025Many multi-agent reinforcement learning (MARL) algorithms are trained in fixed simulation environments, making them brittle when deployed in real-world scenarios with more complex and uncertain conditions. Contextual MARL (cMARL) addresses this by parameterizing environments with context variables and training a context-agnostic policy that performs well across all environment configurations. Existing cMARL methods attempt to use curriculum learning to help train and evaluate context-agnostic policies, but they often rely on unreliable proxy signals, such as value estimates or generalized advantage estimates that are noisy and unstable in multi-agent settings due to inter-agent dynamics and partial observability. To address these issues, we propose Contextual Multi-Agent LLM-Guided Curriculum Learning with Diversity-Based Context Blending (cMALC-D), a framework that uses Large Language Models (LLMs) to generate semantically meaningful curricula and provide a more robust evaluation signal. To prevent mode collapse and encourage exploration, we introduce a novel diversity-based context blending mechanism that creates new training scenarios by combining features from prior contexts. Experiments in traffic signal control domains demonstrate that cMALC-D significantly improves both generalization and sample efficiency compared to existing curriculum learning baselines. We provide code at https://github.com/DaRL-LibSignal/cMALC-D.
PICore: Physics-Informed Unsupervised Coreset Selection for Data Efficient Neural Operator Training
Jul 23, 2025Neural operators offer a powerful paradigm for solving partial differential equations (PDEs) that cannot be solved analytically by learning mappings between function spaces. However, there are two main bottlenecks in training neural operators: they require a significant amount of training data to learn these mappings, and this data needs to be labeled, which can only be accessed via expensive simulations with numerical solvers. To alleviate both of these issues simultaneously, we propose PICore, an unsupervised coreset selection framework that identifies the most informative training samples without requiring access to ground-truth PDE solutions. PICore leverages a physics-informed loss to select unlabeled inputs by their potential contribution to operator learning. After selecting a compact subset of inputs, only those samples are simulated using numerical solvers to generate labels, reducing annotation costs. We then train the neural operator on the reduced labeled dataset, significantly decreasing training time as well. Across four diverse PDE benchmarks and multiple coreset selection strategies, PICore achieves up to 78% average increase in training efficiency relative to supervised coreset selection methods with minimal changes in accuracy. We provide code at https://github.com/Asatheesh6561/PICore.
MORSE-500: A Programmatically Controllable Video Benchmark to Stress-Test Multimodal Reasoning
Jun 05, 2025Despite rapid advances in vision-language models (VLMs), current benchmarks for multimodal reasoning fall short in three key dimensions. First, they overwhelmingly rely on static images, failing to capture the temporal complexity of real-world environments. Second, they narrowly focus on mathematical problem-solving, neglecting the broader spectrum of reasoning skills -- including abstract, physical, planning, spatial, and temporal capabilities -- required for robust multimodal intelligence. Third, many benchmarks quickly saturate, offering limited headroom for diagnosing failure modes or measuring continued progress. We introduce MORSE-500 (Multimodal Reasoning Stress-test Environment), a video benchmark composed of 500 fully scripted clips with embedded questions spanning six complementary reasoning categories. Each instance is programmatically generated using deterministic Python scripts (via Manim, Matplotlib, MoviePy), generative video models, and curated real footage. This script-driven design allows fine-grained control over visual complexity, distractor density, and temporal dynamics -- enabling difficulty to be scaled systematically as models improve. Unlike static benchmarks that become obsolete once saturated, MORSE-500 is built to evolve: its controllable generation pipeline supports the creation of arbitrarily challenging new instances, making it ideally suited for stress-testing next-generation models. Initial experiments with state-of-the-art systems -- including various Gemini 2.5 Pro and OpenAI o3 which represent the strongest available at the time, alongside strong open-source models -- reveal substantial performance gaps across all categories, with particularly large deficits in abstract and planning tasks. We release the full dataset, generation scripts, and evaluation harness to support transparent, reproducible, and forward-looking multimodal reasoning research.
EnsemW2S: Enhancing Weak-to-Strong Generalization with Large Language Model Ensembles
May 28, 2025With Large Language Models (LLMs) rapidly approaching and potentially surpassing human-level performance, it has become imperative to develop approaches capable of effectively supervising and enhancing these powerful models using smaller, human-level models exposed to only human-level data. We address this critical weak-to-strong (W2S) generalization challenge by proposing a novel method aimed at improving weak experts, by training on the same limited human-level data, enabling them to generalize to complex, super-human-level tasks. Our approach, called \textbf{EnsemW2S}, employs a token-level ensemble strategy that iteratively combines multiple weak experts, systematically addressing the shortcomings identified in preceding iterations. By continuously refining these weak models, we significantly enhance their collective ability to supervise stronger student models. We extensively evaluate the generalization performance of both the ensemble of weak experts and the subsequent strong student model across in-distribution (ID) and out-of-distribution (OOD) datasets. For OOD, we specifically introduce question difficulty as an additional dimension for defining distributional shifts. Our empirical results demonstrate notable improvements, achieving 4\%, and 3.2\% improvements on ID datasets and, upto 6\% and 2.28\% on OOD datasets for experts and student models respectively, underscoring the effectiveness of our proposed method in advancing W2S generalization.
A Constrained Multi-Agent Reinforcement Learning Approach to Autonomous Traffic Signal Control
Mar 30, 2025
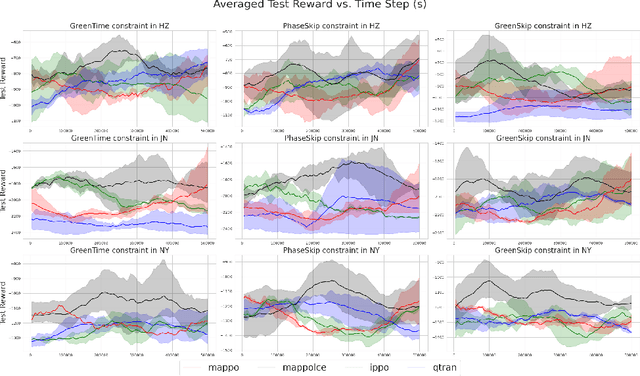

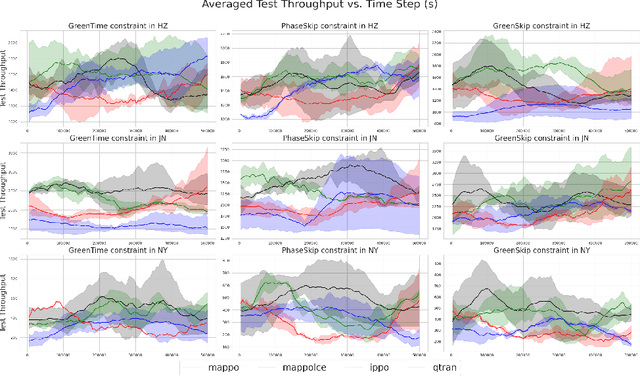
Traffic congestion in modern cities is exacerbated by the limitations of traditional fixed-time traffic signal systems, which fail to adapt to dynamic traffic patterns. Adaptive Traffic Signal Control (ATSC) algorithms have emerged as a solution by dynamically adjusting signal timing based on real-time traffic conditions. However, the main limitation of such methods is that they are not transferable to environments under real-world constraints, such as balancing efficiency, minimizing collisions, and ensuring fairness across intersections. In this paper, we view the ATSC problem as a constrained multi-agent reinforcement learning (MARL) problem and propose a novel algorithm named Multi-Agent Proximal Policy Optimization with Lagrange Cost Estimator (MAPPO-LCE) to produce effective traffic signal control policies. Our approach integrates the Lagrange multipliers method to balance rewards and constraints, with a cost estimator for stable adjustment. We also introduce three constraints on the traffic network: GreenTime, GreenSkip, and PhaseSkip, which penalize traffic policies that do not conform to real-world scenarios. Our experimental results on three real-world datasets demonstrate that MAPPO-LCE outperforms three baseline MARL algorithms by across all environments and traffic constraints (improving on MAPPO by 12.60%, IPPO by 10.29%, and QTRAN by 13.10%). Our results show that constrained MARL is a valuable tool for traffic planners to deploy scalable and efficient ATSC methods in real-world traffic networks. We provide code at https://github.com/Asatheesh6561/MAPPO-LCE.
EnsemW2S: Can an Ensemble of LLMs be Leveraged to Obtain a Stronger LLM?
Oct 06, 2024



How can we harness the collective capabilities of multiple Large Language Models (LLMs) to create an even more powerful model? This question forms the foundation of our research, where we propose an innovative approach to weak-to-strong (w2s) generalization-a critical problem in AI alignment. Our work introduces an easy-to-hard (e2h) framework for studying the feasibility of w2s generalization, where weak models trained on simpler tasks collaboratively supervise stronger models on more complex tasks. This setup mirrors real-world challenges, where direct human supervision is limited. To achieve this, we develop a novel AdaBoost-inspired ensemble method, demonstrating that an ensemble of weak supervisors can enhance the performance of stronger LLMs across classification and generative tasks on difficult QA datasets. In several cases, our ensemble approach matches the performance of models trained on ground-truth data, establishing a new benchmark for w2s generalization. We observe an improvement of up to 14% over existing baselines and average improvements of 5% and 4% for binary classification and generative tasks, respectively. This research points to a promising direction for enhancing AI through collective supervision, especially in scenarios where labeled data is sparse or insufficient.
SAFLEX: Self-Adaptive Augmentation via Feature Label Extrapolation
Oct 03, 2024



Data augmentation, a cornerstone technique in deep learning, is crucial in enhancing model performance, especially with scarce labeled data. While traditional techniques are effective, their reliance on hand-crafted methods limits their applicability across diverse data types and tasks. Although modern learnable augmentation methods offer increased adaptability, they are computationally expensive and challenging to incorporate within prevalent augmentation workflows. In this work, we present a novel, efficient method for data augmentation, effectively bridging the gap between existing augmentation strategies and emerging datasets and learning tasks. We introduce SAFLEX (Self-Adaptive Augmentation via Feature Label EXtrapolation), which learns the sample weights and soft labels of augmented samples provided by any given upstream augmentation pipeline, using a specifically designed efficient bilevel optimization algorithm. Remarkably, SAFLEX effectively reduces the noise and label errors of the upstream augmentation pipeline with a marginal computational cost. As a versatile module, SAFLEX excels across diverse datasets, including natural and medical images and tabular data, showcasing its prowess in few-shot learning and out-of-distribution generalization. SAFLEX seamlessly integrates with common augmentation strategies like RandAug, CutMix, and those from large pre-trained generative models like stable diffusion and is also compatible with frameworks such as CLIP's fine-tuning. Our findings highlight the potential to adapt existing augmentation pipelines for new data types and tasks, signaling a move towards more adaptable and resilient training frameworks.