 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePICore: Physics-Informed Unsupervised Coreset Selection for Data Efficient Neural Operator Training
Jul 23, 2025Neural operators offer a powerful paradigm for solving partial differential equations (PDEs) that cannot be solved analytically by learning mappings between function spaces. However, there are two main bottlenecks in training neural operators: they require a significant amount of training data to learn these mappings, and this data needs to be labeled, which can only be accessed via expensive simulations with numerical solvers. To alleviate both of these issues simultaneously, we propose PICore, an unsupervised coreset selection framework that identifies the most informative training samples without requiring access to ground-truth PDE solutions. PICore leverages a physics-informed loss to select unlabeled inputs by their potential contribution to operator learning. After selecting a compact subset of inputs, only those samples are simulated using numerical solvers to generate labels, reducing annotation costs. We then train the neural operator on the reduced labeled dataset, significantly decreasing training time as well. Across four diverse PDE benchmarks and multiple coreset selection strategies, PICore achieves up to 78% average increase in training efficiency relative to supervised coreset selection methods with minimal changes in accuracy. We provide code at https://github.com/Asatheesh6561/PICore.
EnsemW2S: Enhancing Weak-to-Strong Generalization with Large Language Model Ensembles
May 28, 2025With Large Language Models (LLMs) rapidly approaching and potentially surpassing human-level performance, it has become imperative to develop approaches capable of effectively supervising and enhancing these powerful models using smaller, human-level models exposed to only human-level data. We address this critical weak-to-strong (W2S) generalization challenge by proposing a novel method aimed at improving weak experts, by training on the same limited human-level data, enabling them to generalize to complex, super-human-level tasks. Our approach, called \textbf{EnsemW2S}, employs a token-level ensemble strategy that iteratively combines multiple weak experts, systematically addressing the shortcomings identified in preceding iterations. By continuously refining these weak models, we significantly enhance their collective ability to supervise stronger student models. We extensively evaluate the generalization performance of both the ensemble of weak experts and the subsequent strong student model across in-distribution (ID) and out-of-distribution (OOD) datasets. For OOD, we specifically introduce question difficulty as an additional dimension for defining distributional shifts. Our empirical results demonstrate notable improvements, achieving 4\%, and 3.2\% improvements on ID datasets and, upto 6\% and 2.28\% on OOD datasets for experts and student models respectively, underscoring the effectiveness of our proposed method in advancing W2S generalization.
EnsemW2S: Can an Ensemble of LLMs be Leveraged to Obtain a Stronger LLM?
Oct 06, 2024



How can we harness the collective capabilities of multiple Large Language Models (LLMs) to create an even more powerful model? This question forms the foundation of our research, where we propose an innovative approach to weak-to-strong (w2s) generalization-a critical problem in AI alignment. Our work introduces an easy-to-hard (e2h) framework for studying the feasibility of w2s generalization, where weak models trained on simpler tasks collaboratively supervise stronger models on more complex tasks. This setup mirrors real-world challenges, where direct human supervision is limited. To achieve this, we develop a novel AdaBoost-inspired ensemble method, demonstrating that an ensemble of weak supervisors can enhance the performance of stronger LLMs across classification and generative tasks on difficult QA datasets. In several cases, our ensemble approach matches the performance of models trained on ground-truth data, establishing a new benchmark for w2s generalization. We observe an improvement of up to 14% over existing baselines and average improvements of 5% and 4% for binary classification and generative tasks, respectively. This research points to a promising direction for enhancing AI through collective supervision, especially in scenarios where labeled data is sparse or insufficient.
SAFLEX: Self-Adaptive Augmentation via Feature Label Extrapolation
Oct 03, 2024



Data augmentation, a cornerstone technique in deep learning, is crucial in enhancing model performance, especially with scarce labeled data. While traditional techniques are effective, their reliance on hand-crafted methods limits their applicability across diverse data types and tasks. Although modern learnable augmentation methods offer increased adaptability, they are computationally expensive and challenging to incorporate within prevalent augmentation workflows. In this work, we present a novel, efficient method for data augmentation, effectively bridging the gap between existing augmentation strategies and emerging datasets and learning tasks. We introduce SAFLEX (Self-Adaptive Augmentation via Feature Label EXtrapolation), which learns the sample weights and soft labels of augmented samples provided by any given upstream augmentation pipeline, using a specifically designed efficient bilevel optimization algorithm. Remarkably, SAFLEX effectively reduces the noise and label errors of the upstream augmentation pipeline with a marginal computational cost. As a versatile module, SAFLEX excels across diverse datasets, including natural and medical images and tabular data, showcasing its prowess in few-shot learning and out-of-distribution generalization. SAFLEX seamlessly integrates with common augmentation strategies like RandAug, CutMix, and those from large pre-trained generative models like stable diffusion and is also compatible with frameworks such as CLIP's fine-tuning. Our findings highlight the potential to adapt existing augmentation pipelines for new data types and tasks, signaling a move towards more adaptable and resilient training frameworks.
Easy2Hard-Bench: Standardized Difficulty Labels for Profiling LLM Performance and Generalization
Sep 27, 2024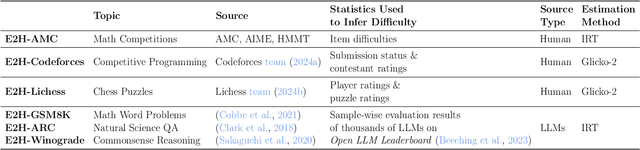

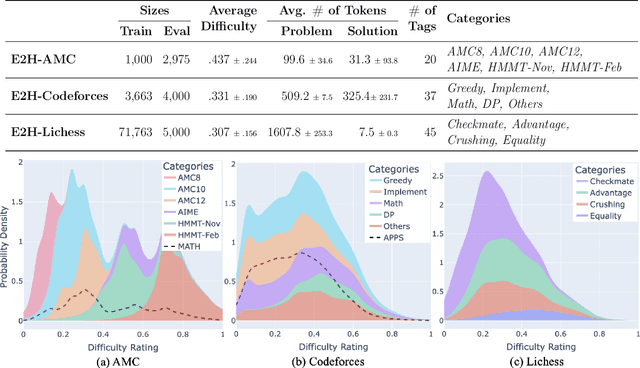
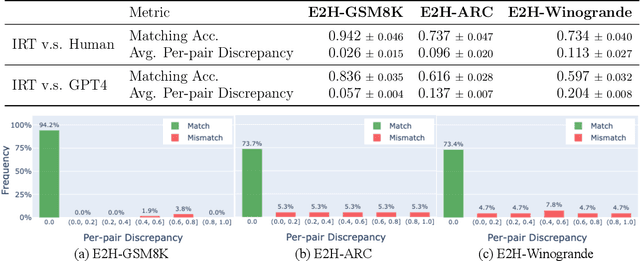
While generalization over tasks from easy to hard is crucial to profile language models (LLMs), the datasets with fine-grained difficulty annotations for each problem across a broad range of complexity are still blank. Aiming to address this limitation, we present Easy2Hard-Bench, a consistently formatted collection of 6 benchmark datasets spanning various domains, such as mathematics and programming problems, chess puzzles, and reasoning questions. Each problem within these datasets is annotated with numerical difficulty scores. To systematically estimate problem difficulties, we collect abundant performance data on attempts to each problem by humans in the real world or LLMs on the prominent leaderboard. Leveraging the rich performance data, we apply well-established difficulty ranking systems, such as Item Response Theory (IRT) and Glicko-2 models, to uniformly assign numerical difficulty scores to problems. Moreover, datasets in Easy2Hard-Bench distinguish themselves from previous collections by a higher proportion of challenging problems. Through extensive experiments with six state-of-the-art LLMs, we provide a comprehensive analysis of their performance and generalization capabilities across varying levels of difficulty, with the aim of inspiring future research in LLM generalization. The datasets are available at https://huggingface.co/datasets/furonghuang-lab/Easy2Hard-Bench.
SAIL: Self-Improving Efficient Online Alignment of Large Language Models
Jun 21, 2024Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
Sketch-GNN: Scalable Graph Neural Networks with Sublinear Training Complexity
Jun 21, 2024


Graph Neural Networks (GNNs) are widely applied to graph learning problems such as node classification. When scaling up the underlying graphs of GNNs to a larger size, we are forced to either train on the complete graph and keep the full graph adjacency and node embeddings in memory (which is often infeasible) or mini-batch sample the graph (which results in exponentially growing computational complexities with respect to the number of GNN layers). Various sampling-based and historical-embedding-based methods are proposed to avoid this exponential growth of complexities. However, none of these solutions eliminates the linear dependence on graph size. This paper proposes a sketch-based algorithm whose training time and memory grow sublinearly with respect to graph size by training GNNs atop a few compact sketches of graph adjacency and node embeddings. Based on polynomial tensor-sketch (PTS) theory, our framework provides a novel protocol for sketching non-linear activations and graph convolution matrices in GNNs, as opposed to existing methods that sketch linear weights or gradients in neural networks. In addition, we develop a locality-sensitive hashing (LSH) technique that can be trained to improve the quality of sketches. Experiments on large-graph benchmarks demonstrate the scalability and competitive performance of our Sketch-GNNs versus their full-size GNN counterparts.
Calibrated Dataset Condensation for Faster Hyperparameter Search
May 27, 2024Dataset condensation can be used to reduce the computational cost of training multiple models on a large dataset by condensing the training dataset into a small synthetic set. State-of-the-art approaches rely on matching the model gradients between the real and synthetic data. However, there is no theoretical guarantee of the generalizability of the condensed data: data condensation often generalizes poorly across hyperparameters/architectures in practice. This paper considers a different condensation objective specifically geared toward hyperparameter search. We aim to generate a synthetic validation dataset so that the validation-performance rankings of the models, with different hyperparameters, on the condensed and original datasets are comparable. We propose a novel hyperparameter-calibrated dataset condensation (HCDC) algorithm, which obtains the synthetic validation dataset by matching the hyperparameter gradients computed via implicit differentiation and efficient inverse Hessian approximation. Experiments demonstrate that the proposed framework effectively maintains the validation-performance rankings of models and speeds up hyperparameter/architecture search for tasks on both images and graphs.
Spectral Greedy Coresets for Graph Neural Networks
May 27, 2024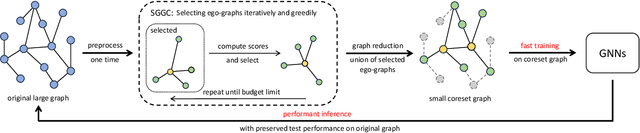
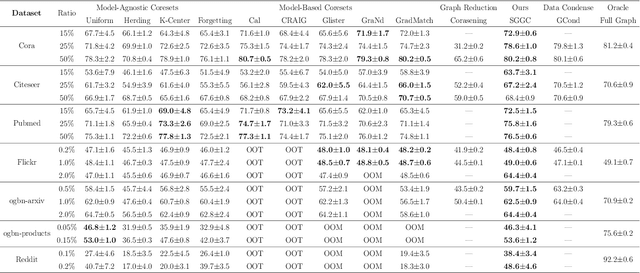
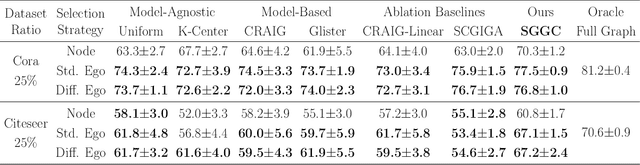
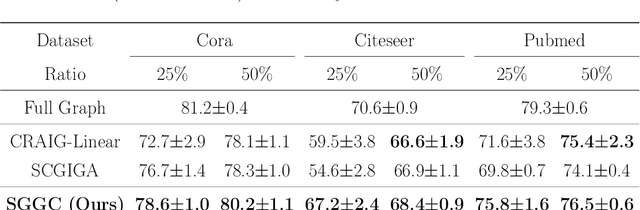
The ubiquity of large-scale graphs in node-classification tasks significantly hinders the real-world applications of Graph Neural Networks (GNNs). Node sampling, graph coarsening, and dataset condensation are effective strategies for enhancing data efficiency. However, owing to the interdependence of graph nodes, coreset selection, which selects subsets of the data examples, has not been successfully applied to speed up GNN training on large graphs, warranting special treatment. This paper studies graph coresets for GNNs and avoids the interdependence issue by selecting ego-graphs (i.e., neighborhood subgraphs around a node) based on their spectral embeddings. We decompose the coreset selection problem for GNNs into two phases: a coarse selection of widely spread ego graphs and a refined selection to diversify their topologies. We design a greedy algorithm that approximately optimizes both objectives. Our spectral greedy graph coreset (SGGC) scales to graphs with millions of nodes, obviates the need for model pre-training, and applies to low-homophily graphs. Extensive experiments on ten datasets demonstrate that SGGC outperforms other coreset methods by a wide margin, generalizes well across GNN architectures, and is much faster than graph condensation.
Benchmarking the Robustness of Image Watermarks
Jan 22, 2024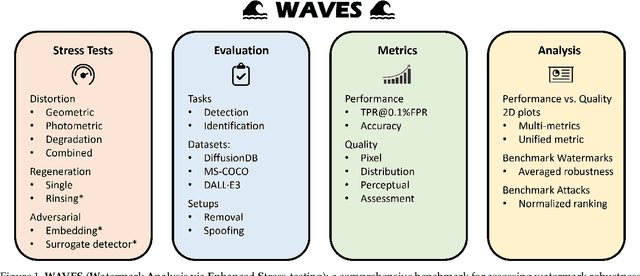
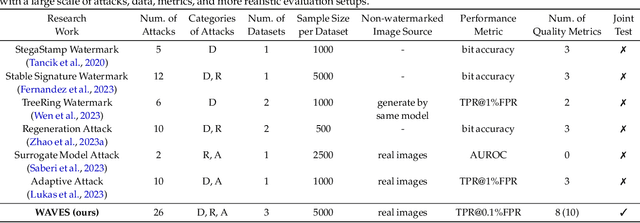
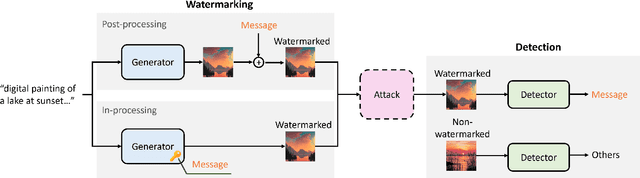
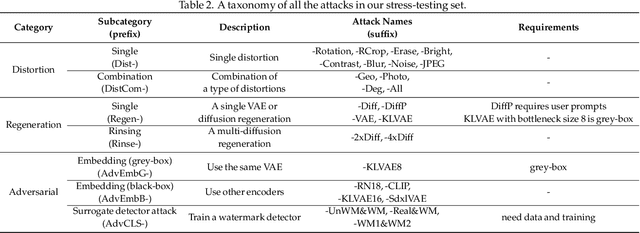
This paper investigates the weaknesses of image watermarking techniques. We present WAVES (Watermark Analysis Via Enhanced Stress-testing), a novel benchmark for assessing watermark robustness, overcoming the limitations of current evaluation methods.WAVES integrates detection and identification tasks, and establishes a standardized evaluation protocol comprised of a diverse range of stress tests. The attacks in WAVES range from traditional image distortions to advanced and novel variations of diffusive, and adversarial attacks. Our evaluation examines two pivotal dimensions: the degree of image quality degradation and the efficacy of watermark detection after attacks. We develop a series of Performance vs. Quality 2D plots, varying over several prominent image similarity metrics, which are then aggregated in a heuristically novel manner to paint an overall picture of watermark robustness and attack potency. Our comprehensive evaluation reveals previously undetected vulnerabilities of several modern watermarking algorithms. We envision WAVES as a toolkit for the future development of robust watermarking systems. The project is available at https://wavesbench.github.io/