 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuction-Based Regulation for Artificial Intelligence
Oct 02, 2024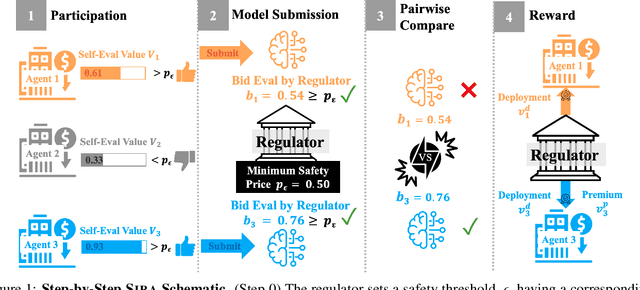
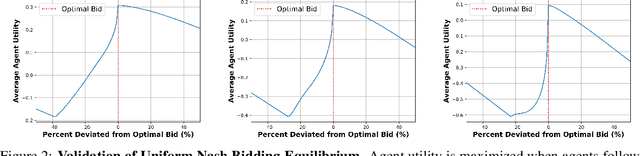
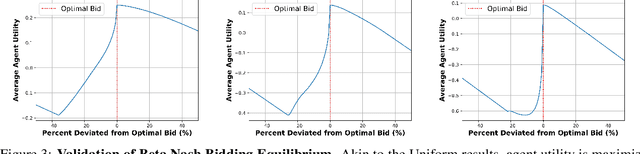
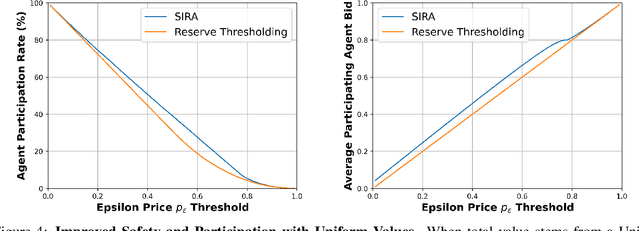
In an era of "moving fast and breaking things", regulators have moved slowly to pick up the safety, bias, and legal pieces left in the wake of broken Artificial Intelligence (AI) deployment. Since AI models, such as large language models, are able to push misinformation and stoke division within our society, it is imperative for regulators to employ a framework that mitigates these dangers and ensures user safety. While there is much-warranted discussion about how to address the safety, bias, and legal woes of state-of-the-art AI models, the number of rigorous and realistic mathematical frameworks to regulate AI safety is lacking. We take on this challenge, proposing an auction-based regulatory mechanism that provably incentivizes model-building agents (i) to deploy safer models and (ii) to participate in the regulation process. We provably guarantee, via derived Nash Equilibria, that each participating agent's best strategy is to submit a model safer than a prescribed minimum-safety threshold. Empirical results show that our regulatory auction boosts safety and participation rates by 20% and 15% respectively, outperforming simple regulatory frameworks that merely enforce minimum safety standards.
FACT or Fiction: Can Truthful Mechanisms Eliminate Federated Free Riding?
May 22, 2024

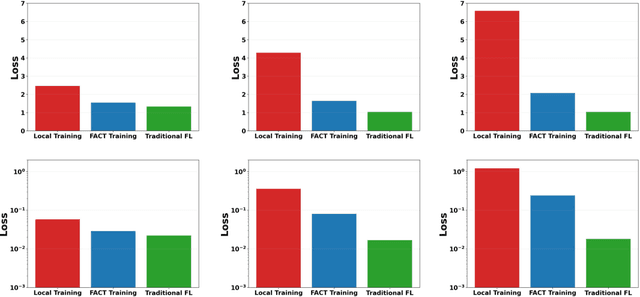

Standard federated learning (FL) approaches are vulnerable to the free-rider dilemma: participating agents can contribute little to nothing yet receive a well-trained aggregated model. While prior mechanisms attempt to solve the free-rider dilemma, none have addressed the issue of truthfulness. In practice, adversarial agents can provide false information to the server in order to cheat its way out of contributing to federated training. In an effort to make free-riding-averse federated mechanisms truthful, and consequently less prone to breaking down in practice, we propose FACT. FACT is the first federated mechanism that: (1) eliminates federated free riding by using a penalty system, (2) ensures agents provide truthful information by creating a competitive environment, and (3) encourages agent participation by offering better performance than training alone. Empirically, FACT avoids free-riding when agents are untruthful, and reduces agent loss by over 4x.
Benchmarking the Robustness of Image Watermarks
Jan 22, 2024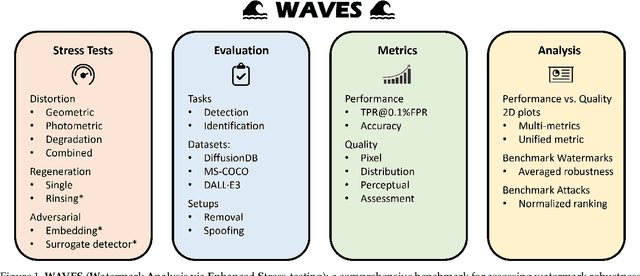
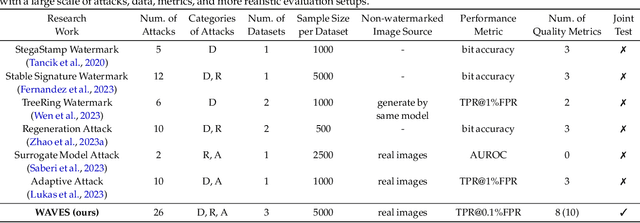
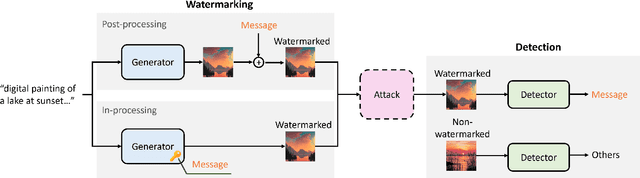
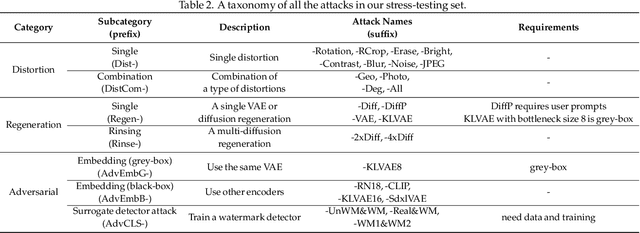
This paper investigates the weaknesses of image watermarking techniques. We present WAVES (Watermark Analysis Via Enhanced Stress-testing), a novel benchmark for assessing watermark robustness, overcoming the limitations of current evaluation methods.WAVES integrates detection and identification tasks, and establishes a standardized evaluation protocol comprised of a diverse range of stress tests. The attacks in WAVES range from traditional image distortions to advanced and novel variations of diffusive, and adversarial attacks. Our evaluation examines two pivotal dimensions: the degree of image quality degradation and the efficacy of watermark detection after attacks. We develop a series of Performance vs. Quality 2D plots, varying over several prominent image similarity metrics, which are then aggregated in a heuristically novel manner to paint an overall picture of watermark robustness and attack potency. Our comprehensive evaluation reveals previously undetected vulnerabilities of several modern watermarking algorithms. We envision WAVES as a toolkit for the future development of robust watermarking systems. The project is available at https://wavesbench.github.io/
Backtracking Counterfactuals
Nov 01, 2022Counterfactual reasoning -- envisioning hypothetical scenarios, or possible worlds, where some circumstances are different from what (f)actually occurred (counter-to-fact) -- is ubiquitous in human cognition. Conventionally, counterfactually-altered circumstances have been treated as "small miracles" that locally violate the laws of nature while sharing the same initial conditions. In Pearl's structural causal model (SCM) framework this is made mathematically rigorous via interventions that modify the causal laws while the values of exogenous variables are shared. In recent years, however, this purely interventionist account of counterfactuals has increasingly come under scrutiny from both philosophers and psychologists. Instead, they suggest a backtracking account of counterfactuals, according to which the causal laws remain unchanged in the counterfactual world; differences to the factual world are instead "backtracked" to altered initial conditions (exogenous variables). In the present work, we explore and formalise this alternative mode of counterfactual reasoning within the SCM framework. Despite ample evidence that humans backtrack, the present work constitutes, to the best of our knowledge, the first general account and algorithmisation of backtracking counterfactuals. We discuss our backtracking semantics in the context of related literature and draw connections to recent developments in explainable artificial intelligence (XAI).