 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Cap-and-Trade: Efficiency Incentives for Accessibility and Sustainability
Jan 27, 2026The race for artificial intelligence (AI) dominance often prioritizes scale over efficiency. Hyper-scaling is the common industry approach: larger models, more data, and as many computational resources as possible. Using more resources is a simpler path to improved AI performance. Thus, efficiency has been de-emphasized. Consequently, the need for costly computational resources has marginalized academics and smaller companies. Simultaneously, increased energy expenditure, due to growing AI use, has led to mounting environmental costs. In response to accessibility and sustainability concerns, we argue for research into, and implementation of, market-based methods that incentivize AI efficiency. We believe that incentivizing efficient operations and approaches will reduce emissions while opening new opportunities for academics and smaller companies. As a call to action, we propose a cap-and-trade system for AI. Our system provably reduces computations for AI deployment, thereby lowering emissions and monetizing efficiency to the benefit of of academics and smaller companies.
Auction-Based Regulation for Artificial Intelligence
Oct 02, 2024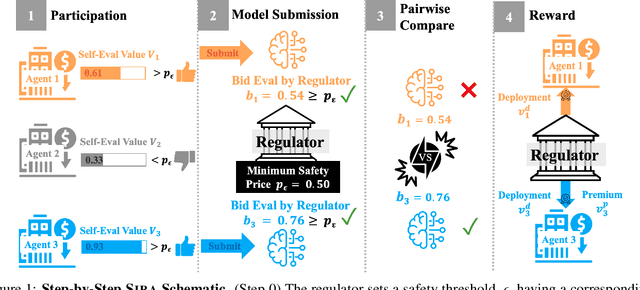
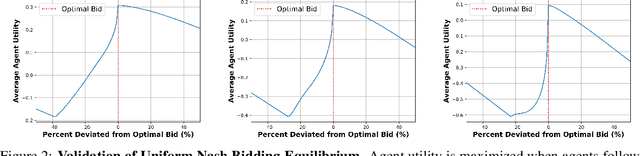
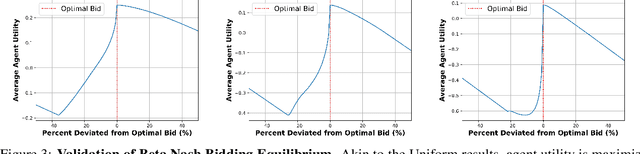
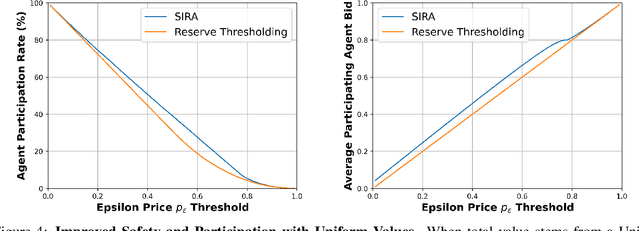
In an era of "moving fast and breaking things", regulators have moved slowly to pick up the safety, bias, and legal pieces left in the wake of broken Artificial Intelligence (AI) deployment. Since AI models, such as large language models, are able to push misinformation and stoke division within our society, it is imperative for regulators to employ a framework that mitigates these dangers and ensures user safety. While there is much-warranted discussion about how to address the safety, bias, and legal woes of state-of-the-art AI models, the number of rigorous and realistic mathematical frameworks to regulate AI safety is lacking. We take on this challenge, proposing an auction-based regulatory mechanism that provably incentivizes model-building agents (i) to deploy safer models and (ii) to participate in the regulation process. We provably guarantee, via derived Nash Equilibria, that each participating agent's best strategy is to submit a model safer than a prescribed minimum-safety threshold. Empirical results show that our regulatory auction boosts safety and participation rates by 20% and 15% respectively, outperforming simple regulatory frameworks that merely enforce minimum safety standards.
FACT or Fiction: Can Truthful Mechanisms Eliminate Federated Free Riding?
May 22, 2024

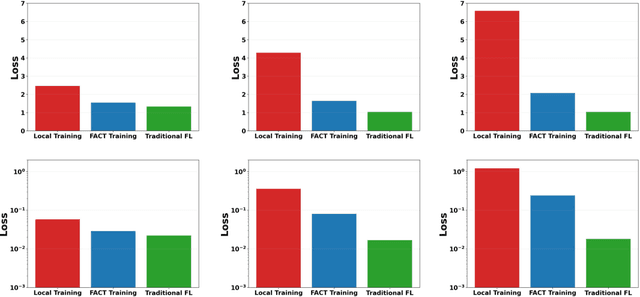

Standard federated learning (FL) approaches are vulnerable to the free-rider dilemma: participating agents can contribute little to nothing yet receive a well-trained aggregated model. While prior mechanisms attempt to solve the free-rider dilemma, none have addressed the issue of truthfulness. In practice, adversarial agents can provide false information to the server in order to cheat its way out of contributing to federated training. In an effort to make free-riding-averse federated mechanisms truthful, and consequently less prone to breaking down in practice, we propose FACT. FACT is the first federated mechanism that: (1) eliminates federated free riding by using a penalty system, (2) ensures agents provide truthful information by creating a competitive environment, and (3) encourages agent participation by offering better performance than training alone. Empirically, FACT avoids free-riding when agents are untruthful, and reduces agent loss by over 4x.
RealFM: A Realistic Mechanism to Incentivize Data Contribution and Device Participation
Oct 20, 2023Edge device participation in federating learning (FL) has been typically studied under the lens of device-server communication (e.g., device dropout) and assumes an undying desire from edge devices to participate in FL. As a result, current FL frameworks are flawed when implemented in real-world settings, with many encountering the free-rider problem. In a step to push FL towards realistic settings, we propose RealFM: the first truly federated mechanism which (1) realistically models device utility, (2) incentivizes data contribution and device participation, and (3) provably removes the free-rider phenomena. RealFM does not require data sharing and allows for a non-linear relationship between model accuracy and utility, which improves the utility gained by the server and participating devices compared to non-participating devices as well as devices participating in other FL mechanisms. On real-world data, RealFM improves device and server utility, as well as data contribution, by up to 3 magnitudes and 7x respectively compared to baseline mechanisms.
Large-Scale Distributed Learning via Private On-Device Locality-Sensitive Hashing
Jun 05, 2023



Locality-sensitive hashing (LSH) based frameworks have been used efficiently to select weight vectors in a dense hidden layer with high cosine similarity to an input, enabling dynamic pruning. While this type of scheme has been shown to improve computational training efficiency, existing algorithms require repeated randomized projection of the full layer weight, which is impractical for computational- and memory-constrained devices. In a distributed setting, deferring LSH analysis to a centralized host is (i) slow if the device cluster is large and (ii) requires access to input data which is forbidden in a federated context. Using a new family of hash functions, we develop one of the first private, personalized, and memory-efficient on-device LSH frameworks. Our framework enables privacy and personalization by allowing each device to generate hash tables, without the help of a central host, using device-specific hashing hyper-parameters (e.g. number of hash tables or hash length). Hash tables are generated with a compressed set of the full weights, and can be serially generated and discarded if the process is memory-intensive. This allows devices to avoid maintaining (i) the fully-sized model and (ii) large amounts of hash tables in local memory for LSH analysis. We prove several statistical and sensitivity properties of our hash functions, and experimentally demonstrate that our framework is competitive in training large-scale recommender networks compared to other LSH frameworks which assume unrestricted on-device capacity.
SWIFT: Rapid Decentralized Federated Learning via Wait-Free Model Communication
Oct 25, 2022



The decentralized Federated Learning (FL) setting avoids the role of a potentially unreliable or untrustworthy central host by utilizing groups of clients to collaboratively train a model via localized training and model/gradient sharing. Most existing decentralized FL algorithms require synchronization of client models where the speed of synchronization depends upon the slowest client. In this work, we propose SWIFT: a novel wait-free decentralized FL algorithm that allows clients to conduct training at their own speed. Theoretically, we prove that SWIFT matches the gold-standard iteration convergence rate $\mathcal{O}(1/\sqrt{T})$ of parallel stochastic gradient descent for convex and non-convex smooth optimization (total iterations $T$). Furthermore, we provide theoretical results for IID and non-IID settings without any bounded-delay assumption for slow clients which is required by other asynchronous decentralized FL algorithms. Although SWIFT achieves the same iteration convergence rate with respect to $T$ as other state-of-the-art (SOTA) parallel stochastic algorithms, it converges faster with respect to run-time due to its wait-free structure. Our experimental results demonstrate that SWIFT's run-time is reduced due to a large reduction in communication time per epoch, which falls by an order of magnitude compared to synchronous counterparts. Furthermore, SWIFT produces loss levels for image classification, over IID and non-IID data settings, upwards of 50% faster than existing SOTA algorithms.