 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHold Onto That Thought: Assessing KV Cache Compression On Reasoning
Dec 12, 2025Large language models (LLMs) have demonstrated remarkable performance on long-context tasks, but are often bottlenecked by memory constraints. Namely, the KV cache, which is used to significantly speed up attention computations, grows linearly with context length. A suite of compression algorithms has been introduced to alleviate cache growth by evicting unimportant tokens. However, several popular strategies are targeted towards the prefill phase, i.e., processing long prompt context, and their performance is rarely assessed on reasoning tasks requiring long decoding. In particular, short but complex prompts, such as those in benchmarks like GSM8K and MATH500, often benefit from multi-step reasoning and self-reflection, resulting in thinking sequences thousands of tokens long. In this work, we benchmark the performance of several popular compression strategies on long-reasoning tasks. For the non-reasoning Llama-3.1-8B-Instruct, we determine that no singular strategy fits all, and that performance is heavily influenced by dataset type. However, we discover that H2O and our decoding-enabled variant of SnapKV are dominant strategies for reasoning models, indicating the utility of heavy-hitter tracking for reasoning traces. We also find that eviction strategies at low budgets can produce longer reasoning traces, revealing a tradeoff between cache size and inference costs.
PRBench: Large-Scale Expert Rubrics for Evaluating High-Stakes Professional Reasoning
Nov 14, 2025Frontier model progress is often measured by academic benchmarks, which offer a limited view of performance in real-world professional contexts. Existing evaluations often fail to assess open-ended, economically consequential tasks in high-stakes domains like Legal and Finance, where practical returns are paramount. To address this, we introduce Professional Reasoning Bench (PRBench), a realistic, open-ended, and difficult benchmark of real-world problems in Finance and Law. We open-source its 1,100 expert-authored tasks and 19,356 expert-curated criteria, making it, to our knowledge, the largest public, rubric-based benchmark for both legal and finance domains. We recruit 182 qualified professionals, holding JDs, CFAs, or 6+ years of experience, who contributed tasks inspired by their actual workflows. This process yields significant diversity, with tasks spanning 114 countries and 47 US jurisdictions. Our expert-curated rubrics are validated through a rigorous quality pipeline, including independent expert validation. Subsequent evaluation of 20 leading models reveals substantial room for improvement, with top scores of only 0.39 (Finance) and 0.37 (Legal) on our Hard subsets. We further catalog associated economic impacts of the prompts and analyze performance using human-annotated rubric categories. Our analysis shows that models with similar overall scores can diverge significantly on specific capabilities. Common failure modes include inaccurate judgments, a lack of process transparency and incomplete reasoning, highlighting critical gaps in their reliability for professional adoption.
ResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents
Nov 10, 2025Deep Research (DR) is an emerging agent application that leverages large language models (LLMs) to address open-ended queries. It requires the integration of several capabilities, including multi-step reasoning, cross-document synthesis, and the generation of evidence-backed, long-form answers. Evaluating DR remains challenging because responses are lengthy and diverse, admit many valid solutions, and often depend on dynamic information sources. We introduce ResearchRubrics, a standardized benchmark for DR built with over 2,800+ hours of human labor that pairs realistic, domain-diverse prompts with 2,500+ expert-written, fine-grained rubrics to assess factual grounding, reasoning soundness, and clarity. We also propose a new complexity framework for categorizing DR tasks along three axes: conceptual breadth, logical nesting, and exploration. In addition, we develop human and model-based evaluation protocols that measure rubric adherence for DR agents. We evaluate several state-of-the-art DR systems and find that even leading agents like Gemini's DR and OpenAI's DR achieve under 68% average compliance with our rubrics, primarily due to missed implicit context and inadequate reasoning about retrieved information. Our results highlight the need for robust, scalable assessment of deep research capabilities, to which end we release ResearchRubrics(including all prompts, rubrics, and evaluation code) to facilitate progress toward well-justified research assistants.
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
Mitigating Unintended Memorization with LoRA in Federated Learning for LLMs
Feb 07, 2025



Federated learning (FL) is a popular paradigm for collaborative training which avoids direct data exposure between clients. However, data privacy issues still remain: FL-trained large language models are capable of memorizing and completing phrases and sentences contained in training data when given with their prefixes. Thus, it is possible for adversarial and honest-but-curious clients to recover training data of other participants simply through targeted prompting. In this work, we demonstrate that a popular and simple fine-tuning strategy, low-rank adaptation (LoRA), reduces memorization during FL up to a factor of 10. We study this effect by performing a medical question-answering fine-tuning task and injecting multiple replicas of out-of-distribution sensitive sequences drawn from an external clinical dataset. We observe a reduction in memorization for a wide variety of Llama 2 and 3 models, and find that LoRA can reduce memorization in centralized learning as well. Furthermore, we show that LoRA can be combined with other privacy-preserving techniques such as gradient clipping and Gaussian noising, secure aggregation, and Goldfish loss to further improve record-level privacy while maintaining performance.
HashEvict: A Pre-Attention KV Cache Eviction Strategy using Locality-Sensitive Hashing
Dec 24, 2024



Transformer-based large language models (LLMs) use the key-value (KV) cache to significantly accelerate inference by storing the key and value embeddings of past tokens. However, this cache consumes significant GPU memory. In this work, we introduce HashEvict, an algorithm that uses locality-sensitive hashing (LSH) to compress the KV cache. HashEvict quickly locates tokens in the cache that are cosine dissimilar to the current query token. This is achieved by computing the Hamming distance between binarized Gaussian projections of the current token query and cached token keys, with a projection length much smaller than the embedding dimension. We maintain a lightweight binary structure in GPU memory to facilitate these calculations. Unlike existing compression strategies that compute attention to determine token retention, HashEvict makes these decisions pre-attention, thereby reducing computational costs. Additionally, HashEvict is dynamic - at every decoding step, the key and value of the current token replace the embeddings of a token expected to produce the lowest attention score. We demonstrate that HashEvict can compress the KV cache by 30%-70% while maintaining high performance across reasoning, multiple-choice, long-context retrieval and summarization tasks.
Sketch-GNN: Scalable Graph Neural Networks with Sublinear Training Complexity
Jun 21, 2024


Graph Neural Networks (GNNs) are widely applied to graph learning problems such as node classification. When scaling up the underlying graphs of GNNs to a larger size, we are forced to either train on the complete graph and keep the full graph adjacency and node embeddings in memory (which is often infeasible) or mini-batch sample the graph (which results in exponentially growing computational complexities with respect to the number of GNN layers). Various sampling-based and historical-embedding-based methods are proposed to avoid this exponential growth of complexities. However, none of these solutions eliminates the linear dependence on graph size. This paper proposes a sketch-based algorithm whose training time and memory grow sublinearly with respect to graph size by training GNNs atop a few compact sketches of graph adjacency and node embeddings. Based on polynomial tensor-sketch (PTS) theory, our framework provides a novel protocol for sketching non-linear activations and graph convolution matrices in GNNs, as opposed to existing methods that sketch linear weights or gradients in neural networks. In addition, we develop a locality-sensitive hashing (LSH) technique that can be trained to improve the quality of sketches. Experiments on large-graph benchmarks demonstrate the scalability and competitive performance of our Sketch-GNNs versus their full-size GNN counterparts.
Calibrated Dataset Condensation for Faster Hyperparameter Search
May 27, 2024Dataset condensation can be used to reduce the computational cost of training multiple models on a large dataset by condensing the training dataset into a small synthetic set. State-of-the-art approaches rely on matching the model gradients between the real and synthetic data. However, there is no theoretical guarantee of the generalizability of the condensed data: data condensation often generalizes poorly across hyperparameters/architectures in practice. This paper considers a different condensation objective specifically geared toward hyperparameter search. We aim to generate a synthetic validation dataset so that the validation-performance rankings of the models, with different hyperparameters, on the condensed and original datasets are comparable. We propose a novel hyperparameter-calibrated dataset condensation (HCDC) algorithm, which obtains the synthetic validation dataset by matching the hyperparameter gradients computed via implicit differentiation and efficient inverse Hessian approximation. Experiments demonstrate that the proposed framework effectively maintains the validation-performance rankings of models and speeds up hyperparameter/architecture search for tasks on both images and graphs.
A Linear Time and Space Local Point Cloud Geometry Encoder via Vectorized Kernel Mixture
Apr 02, 2024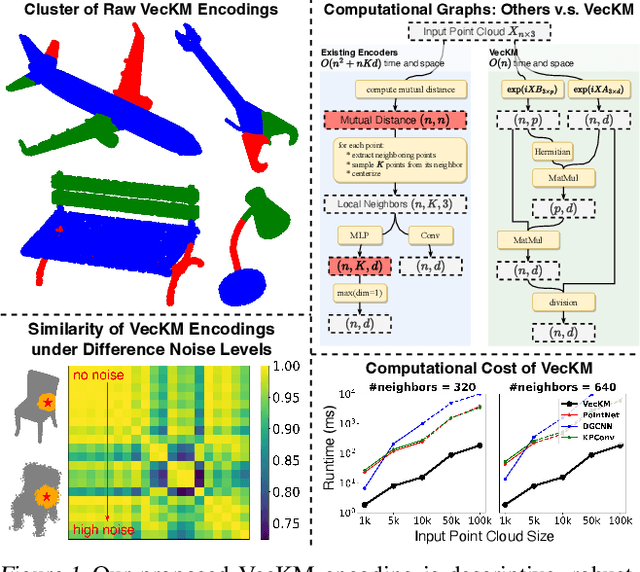



We propose VecKM, a novel local point cloud geometry encoder that is descriptive, efficient and robust to noise. VecKM leverages a unique approach by vectorizing a kernel mixture to represent the local point clouds. Such representation is descriptive and robust to noise, which is supported by two theorems that confirm its ability to reconstruct and preserve the similarity of the local shape. Moreover, VecKM is the first successful attempt to reduce the computation and memory costs from $O(n^2+nKd)$ to $O(nd)$ by sacrificing a marginal constant factor, where $n$ is the size of the point cloud and $K$ is neighborhood size. The efficiency is primarily due to VecKM's unique factorizable property that eliminates the need of explicitly grouping points into neighborhoods. In the normal estimation task, VecKM demonstrates not only 100x faster inference speed but also strongest descriptiveness and robustness compared with existing popular encoders. In classification and segmentation tasks, integrating VecKM as a preprocessing module achieves consistently better performance than the PointNet, PointNet++, and point transformer baselines, and runs consistently faster by up to 10x.
Benchmarking the Robustness of Image Watermarks
Jan 22, 2024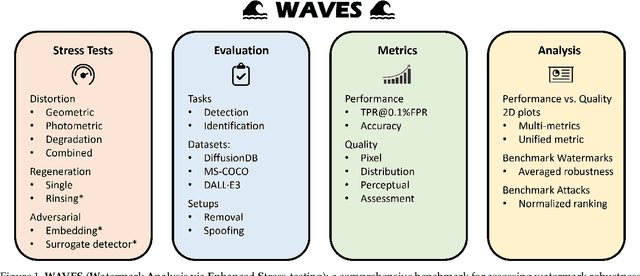
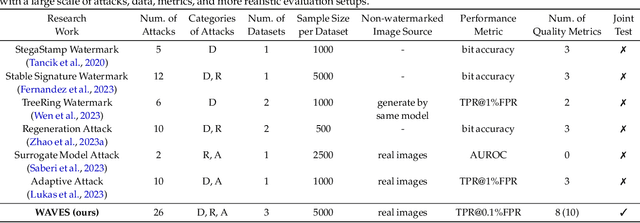
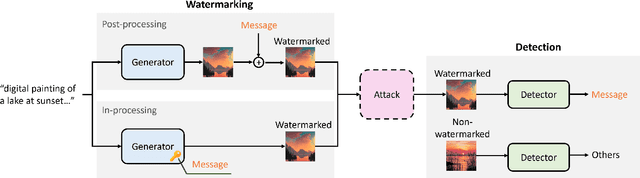
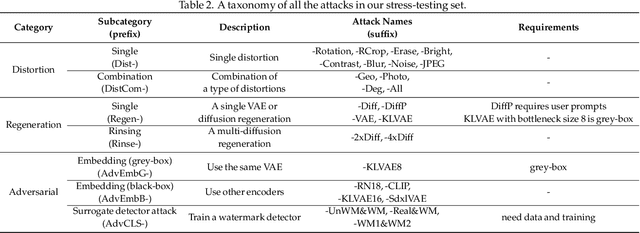
This paper investigates the weaknesses of image watermarking techniques. We present WAVES (Watermark Analysis Via Enhanced Stress-testing), a novel benchmark for assessing watermark robustness, overcoming the limitations of current evaluation methods.WAVES integrates detection and identification tasks, and establishes a standardized evaluation protocol comprised of a diverse range of stress tests. The attacks in WAVES range from traditional image distortions to advanced and novel variations of diffusive, and adversarial attacks. Our evaluation examines two pivotal dimensions: the degree of image quality degradation and the efficacy of watermark detection after attacks. We develop a series of Performance vs. Quality 2D plots, varying over several prominent image similarity metrics, which are then aggregated in a heuristically novel manner to paint an overall picture of watermark robustness and attack potency. Our comprehensive evaluation reveals previously undetected vulnerabilities of several modern watermarking algorithms. We envision WAVES as a toolkit for the future development of robust watermarking systems. The project is available at https://wavesbench.github.io/