 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistics, Not Scale: Modular Medical Dialogue with Bayesian Belief Engine
Apr 21, 2026Large language models are increasingly deployed as autonomous diagnostic agents, yet they conflate two fundamentally different capabilities: natural-language communication and probabilistic reasoning. We argue that this conflation is an architectural flaw, not an engineering shortcoming. We introduce BMBE (Bayesian Medical Belief Engine), a modular diagnostic dialogue framework that enforces a strict separation between language and reasoning: an LLM serves only as a sensor, parsing patient utterances into structured evidence and verbalising questions, while all diagnostic inference resides in a deterministic, auditable Bayesian engine. Because patient data never enters the LLM, the architecture is private by construction; because the statistical backend is a standalone module, it can be replaced per target population without retraining. This separation yields three properties no autonomous LLM can offer: calibrated selective diagnosis with a continuously adjustable accuracy-coverage tradeoff, a statistical separation gap where even a cheap sensor paired with the engine outperforms a frontier standalone model from the same family at a fraction of the cost, and robustness to adversarial patient communication styles that cause standalone doctors to collapse. We validate across empirical and LLM-generated knowledge bases against frontier LLMs, confirming the advantage is architectural, not informational.
HashEvict: A Pre-Attention KV Cache Eviction Strategy using Locality-Sensitive Hashing
Dec 24, 2024



Transformer-based large language models (LLMs) use the key-value (KV) cache to significantly accelerate inference by storing the key and value embeddings of past tokens. However, this cache consumes significant GPU memory. In this work, we introduce HashEvict, an algorithm that uses locality-sensitive hashing (LSH) to compress the KV cache. HashEvict quickly locates tokens in the cache that are cosine dissimilar to the current query token. This is achieved by computing the Hamming distance between binarized Gaussian projections of the current token query and cached token keys, with a projection length much smaller than the embedding dimension. We maintain a lightweight binary structure in GPU memory to facilitate these calculations. Unlike existing compression strategies that compute attention to determine token retention, HashEvict makes these decisions pre-attention, thereby reducing computational costs. Additionally, HashEvict is dynamic - at every decoding step, the key and value of the current token replace the embeddings of a token expected to produce the lowest attention score. We demonstrate that HashEvict can compress the KV cache by 30%-70% while maintaining high performance across reasoning, multiple-choice, long-context retrieval and summarization tasks.
TabSeq: A Framework for Deep Learning on Tabular Data via Sequential Ordering
Oct 17, 2024



Effective analysis of tabular data still poses a significant problem in deep learning, mainly because features in tabular datasets are often heterogeneous and have different levels of relevance. This work introduces TabSeq, a novel framework for the sequential ordering of features, addressing the vital necessity to optimize the learning process. Features are not always equally informative, and for certain deep learning models, their random arrangement can hinder the model's learning capacity. Finding the optimum sequence order for such features could improve the deep learning models' learning process. The novel feature ordering technique we provide in this work is based on clustering and incorporates both local ordering and global ordering. It is designed to be used with a multi-head attention mechanism in a denoising autoencoder network. Our framework uses clustering to align comparable features and improve data organization. Multi-head attention focuses on essential characteristics, whereas the denoising autoencoder highlights important aspects by rebuilding from distorted inputs. This method improves the capability to learn from tabular data while lowering redundancy. Our research, demonstrating improved performance through appropriate feature sequence rearrangement using raw antibody microarray and two other real-world biomedical datasets, validates the impact of feature ordering. These results demonstrate that feature ordering can be a viable approach to improved deep learning of tabular data.
Unlearning Information Bottleneck: Machine Unlearning of Systematic Patterns and Biases
May 22, 2024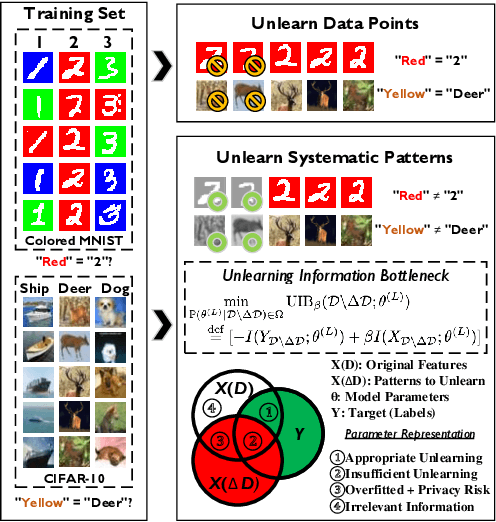
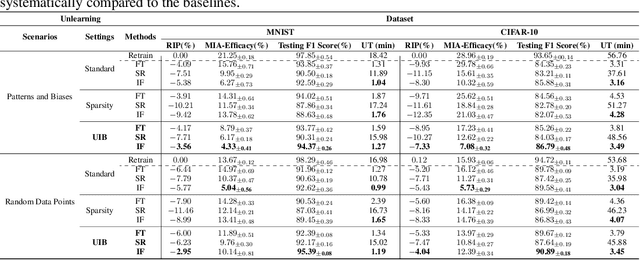
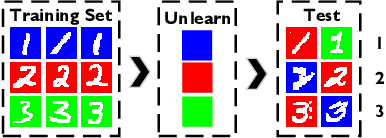

Effective adaptation to distribution shifts in training data is pivotal for sustaining robustness in neural networks, especially when removing specific biases or outdated information, a process known as machine unlearning. Traditional approaches typically assume that data variations are random, which makes it difficult to adjust the model parameters accurately to remove patterns and characteristics from unlearned data. In this work, we present Unlearning Information Bottleneck (UIB), a novel information-theoretic framework designed to enhance the process of machine unlearning that effectively leverages the influence of systematic patterns and biases for parameter adjustment. By proposing a variational upper bound, we recalibrate the model parameters through a dynamic prior that integrates changes in data distribution with an affordable computational cost, allowing efficient and accurate removal of outdated or unwanted data patterns and biases. Our experiments across various datasets, models, and unlearning methods demonstrate that our approach effectively removes systematic patterns and biases while maintaining the performance of models post-unlearning.
Towards Independence Criterion in Machine Unlearning of Features and Labels
Mar 12, 2024



This work delves into the complexities of machine unlearning in the face of distributional shifts, particularly focusing on the challenges posed by non-uniform feature and label removal. With the advent of regulations like the GDPR emphasizing data privacy and the right to be forgotten, machine learning models face the daunting task of unlearning sensitive information without compromising their integrity or performance. Our research introduces a novel approach that leverages influence functions and principles of distributional independence to address these challenges. By proposing a comprehensive framework for machine unlearning, we aim to ensure privacy protection while maintaining model performance and adaptability across varying distributions. Our method not only facilitates efficient data removal but also dynamically adjusts the model to preserve its generalization capabilities. Through extensive experimentation, we demonstrate the efficacy of our approach in scenarios characterized by significant distributional shifts, making substantial contributions to the field of machine unlearning. This research paves the way for developing more resilient and adaptable unlearning techniques, ensuring models remain robust and accurate in the dynamic landscape of data privacy and machine learning.
TimEHR: Image-based Time Series Generation for Electronic Health Records
Feb 09, 2024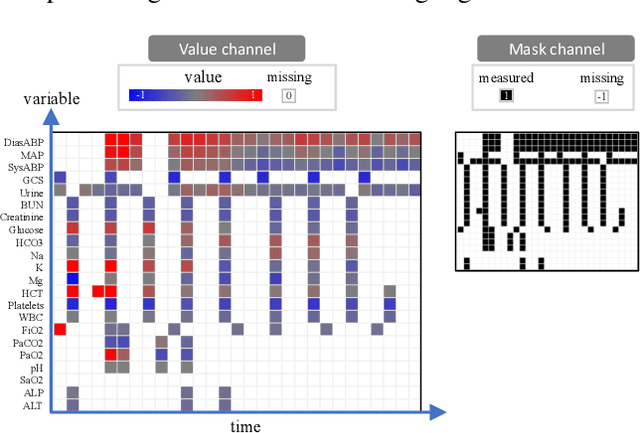
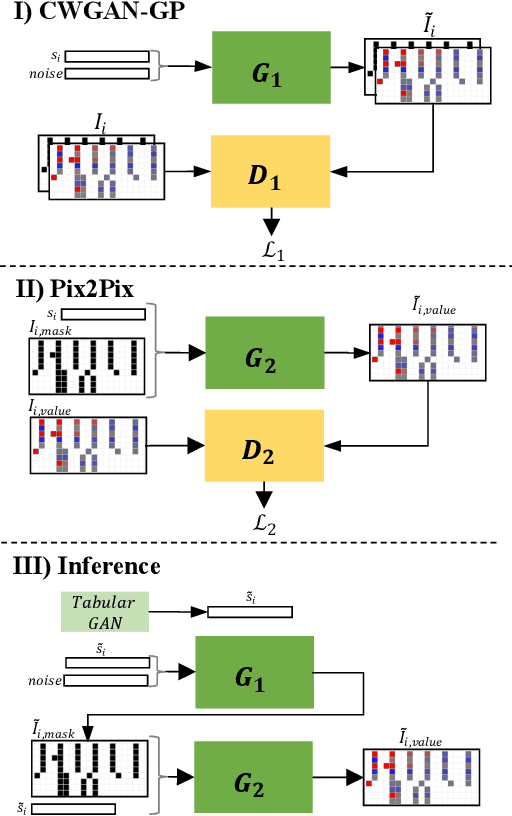
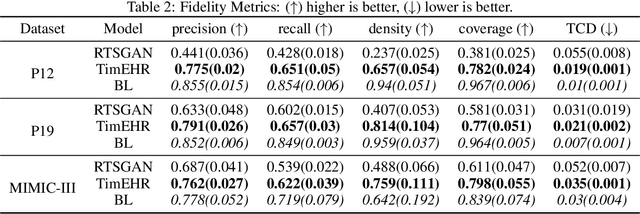
Time series in Electronic Health Records (EHRs) present unique challenges for generative models, such as irregular sampling, missing values, and high dimensionality. In this paper, we propose a novel generative adversarial network (GAN) model, TimEHR, to generate time series data from EHRs. In particular, TimEHR treats time series as images and is based on two conditional GANs. The first GAN generates missingness patterns, and the second GAN generates time series values based on the missingness pattern. Experimental results on three real-world EHR datasets show that TimEHR outperforms state-of-the-art methods in terms of fidelity, utility, and privacy metrics.
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Nov 27, 2023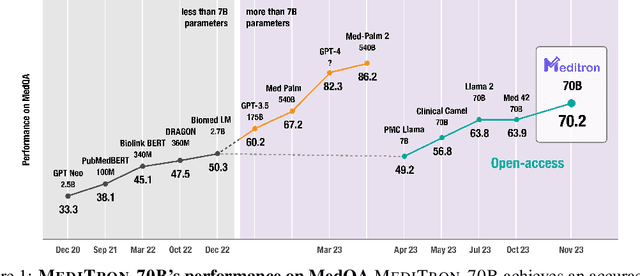
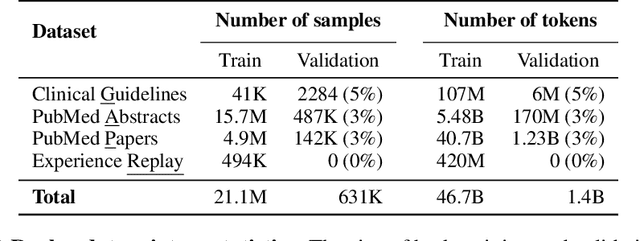
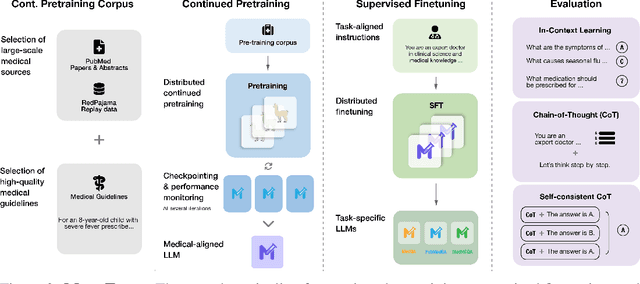

Large language models (LLMs) can potentially democratize access to medical knowledge. While many efforts have been made to harness and improve LLMs' medical knowledge and reasoning capacities, the resulting models are either closed-source (e.g., PaLM, GPT-4) or limited in scale (<= 13B parameters), which restricts their abilities. In this work, we improve access to large-scale medical LLMs by releasing MEDITRON: a suite of open-source LLMs with 7B and 70B parameters adapted to the medical domain. MEDITRON builds on Llama-2 (through our adaptation of Nvidia's Megatron-LM distributed trainer), and extends pretraining on a comprehensively curated medical corpus, including selected PubMed articles, abstracts, and internationally-recognized medical guidelines. Evaluations using four major medical benchmarks show significant performance gains over several state-of-the-art baselines before and after task-specific finetuning. Overall, MEDITRON achieves a 6% absolute performance gain over the best public baseline in its parameter class and 3% over the strongest baseline we finetuned from Llama-2. Compared to closed-source LLMs, MEDITRON-70B outperforms GPT-3.5 and Med-PaLM and is within 5% of GPT-4 and 10% of Med-PaLM-2. We release our code for curating the medical pretraining corpus and the MEDITRON model weights to drive open-source development of more capable medical LLMs.
MultiModN- Multimodal, Multi-Task, Interpretable Modular Networks
Sep 25, 2023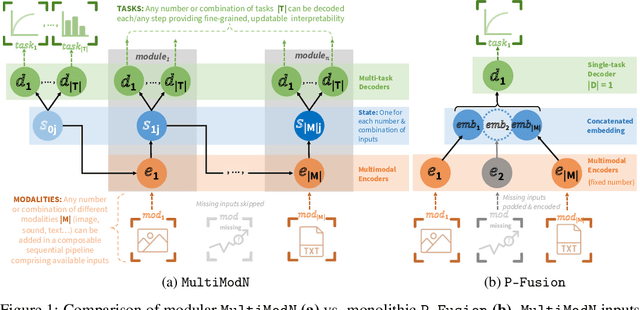

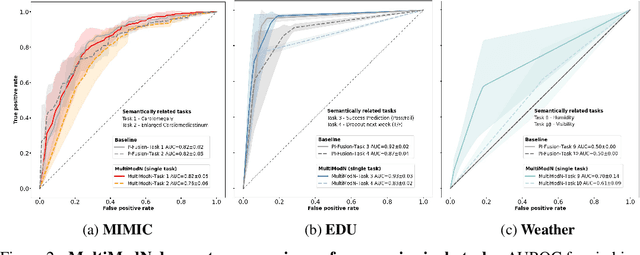

Predicting multiple real-world tasks in a single model often requires a particularly diverse feature space. Multimodal (MM) models aim to extract the synergistic predictive potential of multiple data types to create a shared feature space with aligned semantic meaning across inputs of drastically varying sizes (i.e. images, text, sound). Most current MM architectures fuse these representations in parallel, which not only limits their interpretability but also creates a dependency on modality availability. We present MultiModN, a multimodal, modular network that fuses latent representations in a sequence of any number, combination, or type of modality while providing granular real-time predictive feedback on any number or combination of predictive tasks. MultiModN's composable pipeline is interpretable-by-design, as well as innately multi-task and robust to the fundamental issue of biased missingness. We perform four experiments on several benchmark MM datasets across 10 real-world tasks (predicting medical diagnoses, academic performance, and weather), and show that MultiModN's sequential MM fusion does not compromise performance compared with a baseline of parallel fusion. By simulating the challenging bias of missing not-at-random (MNAR), this work shows that, contrary to MultiModN, parallel fusion baselines erroneously learn MNAR and suffer catastrophic failure when faced with different patterns of MNAR at inference. To the best of our knowledge, this is the first inherently MNAR-resistant approach to MM modeling. In conclusion, MultiModN provides granular insights, robustness, and flexibility without compromising performance.
Modular Clinical Decision Support Networks (MoDN) -- Updatable, Interpretable, and Portable Predictions for Evolving Clinical Environments
Nov 12, 2022Data-driven Clinical Decision Support Systems (CDSS) have the potential to improve and standardise care with personalised probabilistic guidance. However, the size of data required necessitates collaborative learning from analogous CDSS's, which are often unsharable or imperfectly interoperable (IIO), meaning their feature sets are not perfectly overlapping. We propose Modular Clinical Decision Support Networks (MoDN) which allow flexible, privacy-preserving learning across IIO datasets, while providing interpretable, continuous predictive feedback to the clinician. MoDN is a novel decision tree composed of feature-specific neural network modules. It creates dynamic personalised representations of patients, and can make multiple predictions of diagnoses, updatable at each step of a consultation. The modular design allows it to compartmentalise training updates to specific features and collaboratively learn between IIO datasets without sharing any data.
Optimal Model Averaging: Towards Personalized Collaborative Learning
Oct 25, 2021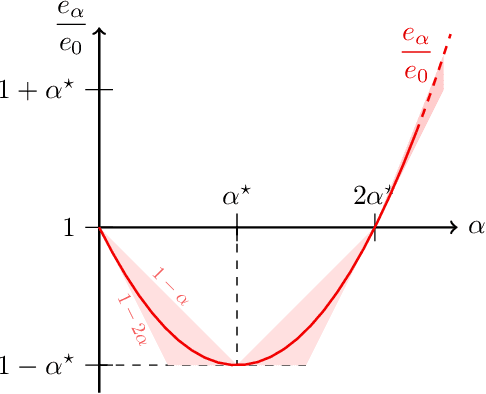
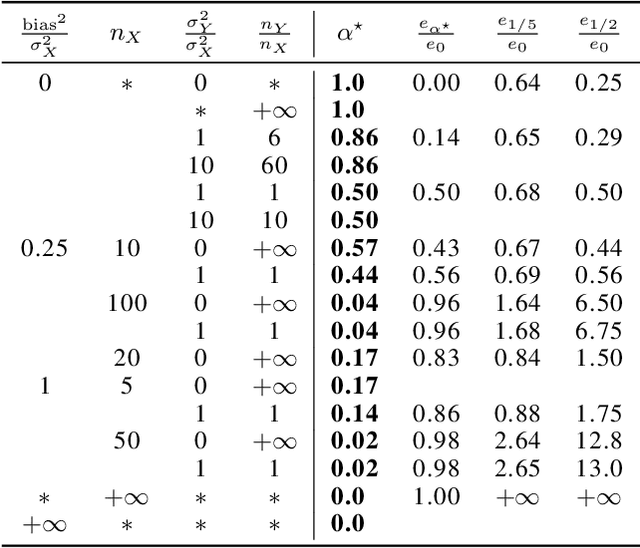
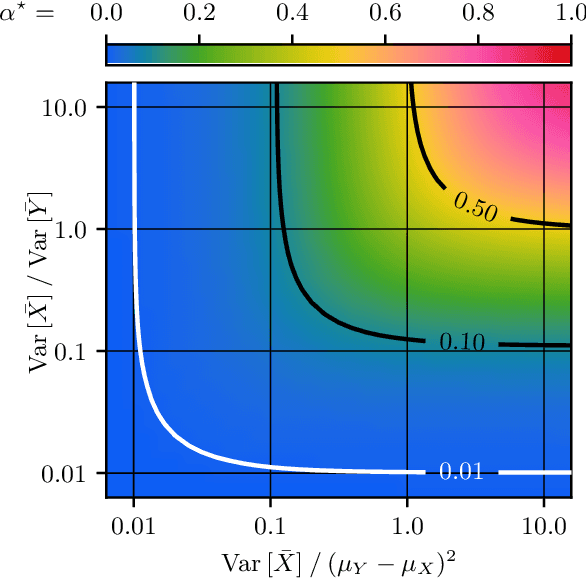
In federated learning, differences in the data or objectives between the participating nodes motivate approaches to train a personalized machine learning model for each node. One such approach is weighted averaging between a locally trained model and the global model. In this theoretical work, we study weighted model averaging for arbitrary scalar mean estimation problems under minimal assumptions on the distributions. In a variant of the bias-variance trade-off, we find that there is always some positive amount of model averaging that reduces the expected squared error compared to the local model, provided only that the local model has a non-zero variance. Further, we quantify the (possibly negative) benefit of weighted model averaging as a function of the weight used and the optimal weight. Taken together, this work formalizes an approach to quantify the value of personalization in collaborative learning and provides a framework for future research to test the findings in multivariate parameter estimation and under a range of assumptions.