 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Nov 27, 2023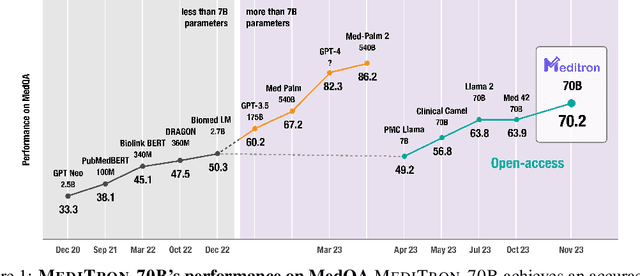
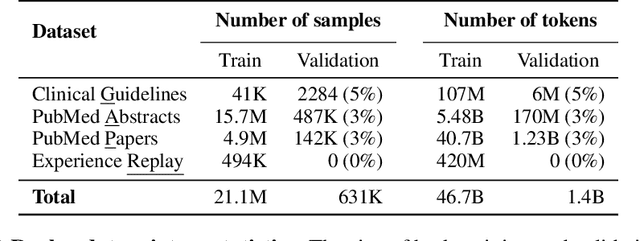
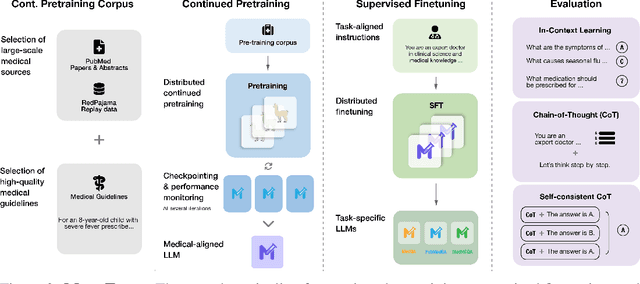

Large language models (LLMs) can potentially democratize access to medical knowledge. While many efforts have been made to harness and improve LLMs' medical knowledge and reasoning capacities, the resulting models are either closed-source (e.g., PaLM, GPT-4) or limited in scale (<= 13B parameters), which restricts their abilities. In this work, we improve access to large-scale medical LLMs by releasing MEDITRON: a suite of open-source LLMs with 7B and 70B parameters adapted to the medical domain. MEDITRON builds on Llama-2 (through our adaptation of Nvidia's Megatron-LM distributed trainer), and extends pretraining on a comprehensively curated medical corpus, including selected PubMed articles, abstracts, and internationally-recognized medical guidelines. Evaluations using four major medical benchmarks show significant performance gains over several state-of-the-art baselines before and after task-specific finetuning. Overall, MEDITRON achieves a 6% absolute performance gain over the best public baseline in its parameter class and 3% over the strongest baseline we finetuned from Llama-2. Compared to closed-source LLMs, MEDITRON-70B outperforms GPT-3.5 and Med-PaLM and is within 5% of GPT-4 and 10% of Med-PaLM-2. We release our code for curating the medical pretraining corpus and the MEDITRON model weights to drive open-source development of more capable medical LLMs.
Accurate Extrinsic Prediction of Physical Systems Using Transformers
Oct 20, 2022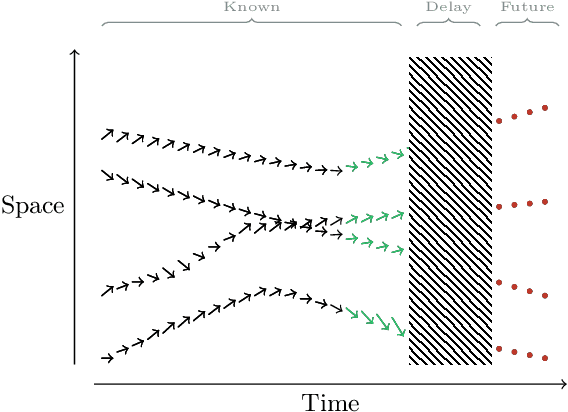
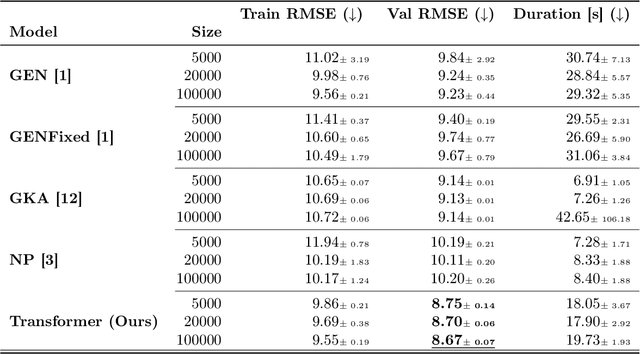
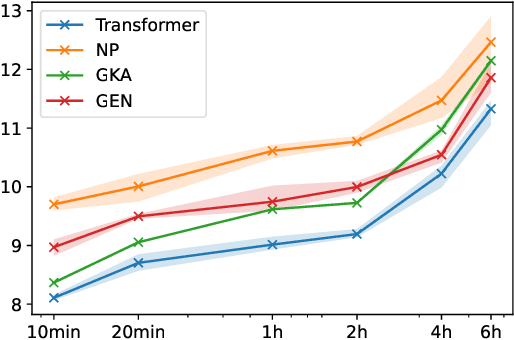
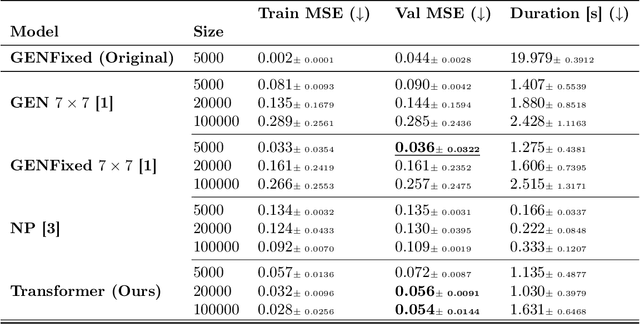
Accurate high-altitude wind forecasting is important for air traffic control. And the large volume of data available for this task makes deep neural network-based models a possibility. However, special methods are required because the data is measured only sparsely: along the main aircraft trajectories and arranged sparsely in space, namely along the main air corridors. Several deep learning approaches have been proposed, and in this work, we show that Transformers can fit this data efficiently and are able to extrapolate coherently from a context set. We show this by an extensive comparison of Transformers to numerous existing deep learning-based baselines in the literature. Besides high-altitude wind forecasting, we compare competing models on other dynamical physical systems, namely those modelled by partial differential equations, in particular the Poisson equation and Darcy Flow equation. For these experiments, in the case where the data is arranged non-regularly in space, Transformers outperform all the other evaluated methods. We also compared them in a more standard setup where the data is arranged on a grid and show that the Transformers are competitive with state-of-the-art methods, even though it does not require regular spacing. The code and datasets of the different experiments will be made publicly available at publication time.
Flatten the Curve: Efficiently Training Low-Curvature Neural Networks
Jun 14, 2022

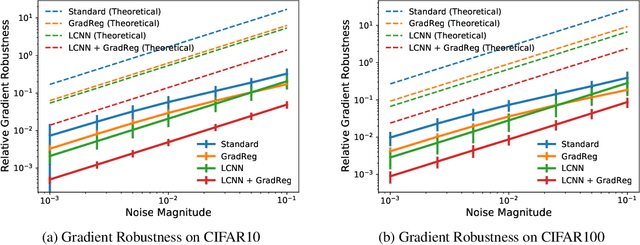
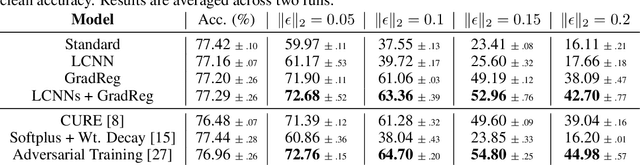
The highly non-linear nature of deep neural networks causes them to be susceptible to adversarial examples and have unstable gradients which hinders interpretability. However, existing methods to solve these issues, such as adversarial training, are expensive and often sacrifice predictive accuracy. In this work, we consider curvature, which is a mathematical quantity which encodes the degree of non-linearity. Using this, we demonstrate low-curvature neural networks (LCNNs) that obtain drastically lower curvature than standard models while exhibiting similar predictive performance, which leads to improved robustness and stable gradients, with only a marginally increased training time. To achieve this, we minimize a data-independent upper bound on the curvature of a neural network, which decomposes overall curvature in terms of curvatures and slopes of its constituent layers. To efficiently minimize this bound, we introduce two novel architectural components: first, a non-linearity called centered-softplus that is a stable variant of the softplus non-linearity, and second, a Lipschitz-constrained batch normalization layer. Our experiments show that LCNNs have lower curvature, more stable gradients and increased off-the-shelf adversarial robustness when compared to their standard high-curvature counterparts, all without affecting predictive performance. Our approach is easy to use and can be readily incorporated into existing neural network models.
The Theoretical Expressiveness of Maxpooling
Mar 02, 2022


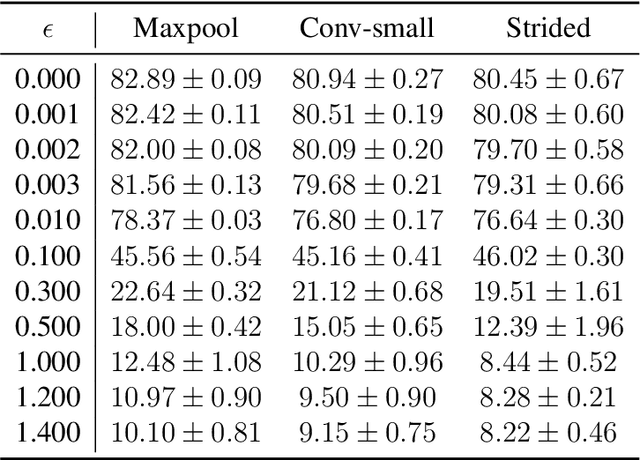
Over the decade since deep neural networks became state of the art image classifiers there has been a tendency towards less use of max pooling: the function that takes the largest of nearby pixels in an image. Since max pooling featured prominently in earlier generations of image classifiers, we wish to understand this trend, and whether it is justified. We develop a theoretical framework analyzing ReLU based approximations to max pooling, and prove a sense in which max pooling cannot be efficiently replicated using ReLU activations. We analyze the error of a class of optimal approximations, and find that whilst the error can be made exponentially small in the kernel size, doing so requires an exponentially complex approximation. Our work gives a theoretical basis for understanding the trend away from max pooling in newer architectures. We conclude that the main cause of a difference between max pooling and an optimal approximation, a prevalent large difference between the max and other values within pools, can be overcome with other architectural decisions, or is not prevalent in natural images.
Challenges for Using Impact Regularizers to Avoid Negative Side Effects
Feb 23, 2021Designing reward functions for reinforcement learning is difficult: besides specifying which behavior is rewarded for a task, the reward also has to discourage undesired outcomes. Misspecified reward functions can lead to unintended negative side effects, and overall unsafe behavior. To overcome this problem, recent work proposed to augment the specified reward function with an impact regularizer that discourages behavior that has a big impact on the environment. Although initial results with impact regularizers seem promising in mitigating some types of side effects, important challenges remain. In this paper, we examine the main current challenges of impact regularizers and relate them to fundamental design decisions. We discuss in detail which challenges recent approaches address and which remain unsolved. Finally, we explore promising directions to overcome the unsolved challenges in preventing negative side effects with impact regularizers.