 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Theoretical Expressiveness of Maxpooling
Paper and Code
Mar 02, 2022


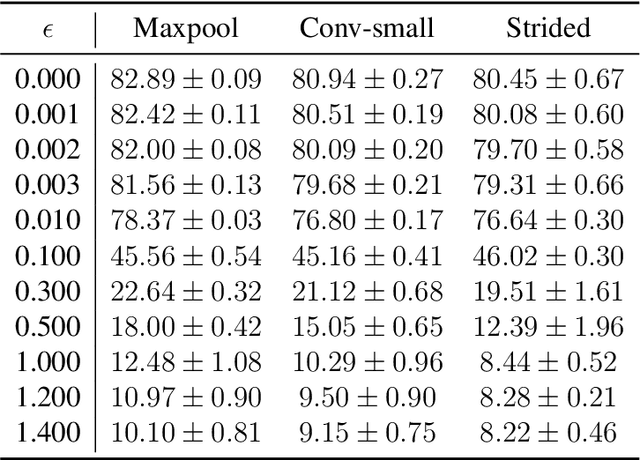
Over the decade since deep neural networks became state of the art image classifiers there has been a tendency towards less use of max pooling: the function that takes the largest of nearby pixels in an image. Since max pooling featured prominently in earlier generations of image classifiers, we wish to understand this trend, and whether it is justified. We develop a theoretical framework analyzing ReLU based approximations to max pooling, and prove a sense in which max pooling cannot be efficiently replicated using ReLU activations. We analyze the error of a class of optimal approximations, and find that whilst the error can be made exponentially small in the kernel size, doing so requires an exponentially complex approximation. Our work gives a theoretical basis for understanding the trend away from max pooling in newer architectures. We conclude that the main cause of a difference between max pooling and an optimal approximation, a prevalent large difference between the max and other values within pools, can be overcome with other architectural decisions, or is not prevalent in natural images.