 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMOIR: Lifelong Model Editing with Minimal Overwrite and Informed Retention for LLMs
Jun 09, 2025Language models deployed in real-world systems often require post-hoc updates to incorporate new or corrected knowledge. However, editing such models efficiently and reliably - without retraining or forgetting previous information - remains a major challenge. Existing methods for lifelong model editing either compromise generalization, interfere with past edits, or fail to scale to long editing sequences. We propose MEMOIR, a novel scalable framework that injects knowledge through a residual memory, i.e., a dedicated parameter module, while preserving the core capabilities of the pre-trained model. By sparsifying input activations through sample-dependent masks, MEMOIR confines each edit to a distinct subset of the memory parameters, minimizing interference among edits. At inference, it identifies relevant edits by comparing the sparse activation patterns of new queries to those stored during editing. This enables generalization to rephrased queries by activating only the relevant knowledge while suppressing unnecessary memory activation for unrelated prompts. Experiments on question answering, hallucination correction, and out-of-distribution generalization benchmarks across LLaMA-3 and Mistral demonstrate that MEMOIR achieves state-of-the-art performance across reliability, generalization, and locality metrics, scaling to thousands of sequential edits with minimal forgetting.
Single-Input Multi-Output Model Merging: Leveraging Foundation Models for Dense Multi-Task Learning
Apr 15, 2025Model merging is a flexible and computationally tractable approach to merge single-task checkpoints into a multi-task model. Prior work has solely focused on constrained multi-task settings where there is a one-to-one mapping between a sample and a task, overlooking the paradigm where multiple tasks may operate on the same sample, e.g., scene understanding. In this paper, we focus on the multi-task setting with single-input-multiple-outputs (SIMO) and show that it qualitatively differs from the single-input-single-output model merging settings studied in the literature due to the existence of task-specific decoders and diverse loss objectives. We identify that existing model merging methods lead to significant performance degradation, primarily due to representation misalignment between the merged encoder and task-specific decoders. We propose two simple and efficient fixes for the SIMO setting to re-align the feature representation after merging. Compared to joint fine-tuning, our approach is computationally effective and flexible, and sheds light into identifying task relationships in an offline manner. Experiments on NYUv2, Cityscapes, and a subset of the Taskonomy dataset demonstrate: (1) task arithmetic suffices to enable multi-task capabilities; however, the representations generated by the merged encoder has to be re-aligned with the task-specific heads; (2) the proposed architecture rivals traditional multi-task learning in performance but requires fewer samples and training steps by leveraging the existence of task-specific models.
LiNeS: Post-training Layer Scaling Prevents Forgetting and Enhances Model Merging
Oct 22, 2024Large pre-trained models exhibit impressive zero-shot performance across diverse tasks, but fine-tuning often leads to catastrophic forgetting, where improvements on a target domain degrade generalization on other tasks. To address this challenge, we introduce LiNeS, Layer-increasing Network Scaling, a post-training editing technique designed to preserve pre-trained generalization while enhancing fine-tuned task performance. LiNeS scales parameter updates linearly based on their layer depth within the network, maintaining shallow layers close to their pre-trained values to preserve general features while allowing deeper layers to retain task-specific representations. We further extend this approach to multi-task model merging scenarios, where layer-wise scaling of merged parameters reduces negative task interference. LiNeS demonstrates significant improvements in both single-task and multi-task settings across various benchmarks in vision and natural language processing. It mitigates forgetting, enhances out-of-distribution generalization, integrates seamlessly with existing multi-task model merging baselines improving their performance across benchmarks and model sizes, and can boost generalization when merging LLM policies aligned with different rewards via RLHF. Importantly, our method is simple to implement and complementary to many existing techniques.
Pareto Low-Rank Adapters: Efficient Multi-Task Learning with Preferences
Jul 10, 2024



Dealing with multi-task trade-offs during inference can be addressed via Pareto Front Learning (PFL) methods that parameterize the Pareto Front with a single model, contrary to traditional Multi-Task Learning (MTL) approaches that optimize for a single trade-off which has to be decided prior to training. However, recent PFL methodologies suffer from limited scalability, slow convergence and excessive memory requirements compared to MTL approaches while exhibiting inconsistent mappings from preference space to objective space. In this paper, we introduce PaLoRA, a novel parameter-efficient method that augments the original model with task-specific low-rank adapters and continuously parameterizes the Pareto Front in their convex hull. Our approach dedicates the original model and the adapters towards learning general and task-specific features, respectively. Additionally, we propose a deterministic sampling schedule of preference vectors that reinforces this division of labor, enabling faster convergence and scalability to real world networks. Our experimental results show that PaLoRA outperforms MTL and PFL baselines across various datasets, scales to large networks and provides a continuous parameterization of the Pareto Front, reducing the memory overhead $23.8-31.7$ times compared with competing PFL baselines in scene understanding benchmarks.
Localizing Task Information for Improved Model Merging and Compression
May 13, 2024Model merging and task arithmetic have emerged as promising scalable approaches to merge multiple single-task checkpoints to one multi-task model, but their applicability is reduced by significant performance loss. Previous works have linked these drops to interference in the weight space and erasure of important task-specific features. Instead, in this work we show that the information required to solve each task is still preserved after merging as different tasks mostly use non-overlapping sets of weights. We propose TALL-masks, a method to identify these task supports given a collection of task vectors and show that one can retrieve >99% of the single task accuracy by applying our masks to the multi-task vector, effectively compressing the individual checkpoints. We study the statistics of intersections among constructed masks and reveal the existence of selfish and catastrophic weights, i.e., parameters that are important exclusively to one task and irrelevant to all tasks but detrimental to multi-task fusion. For this reason, we propose Consensus Merging, an algorithm that eliminates such weights and improves the general performance of existing model merging approaches. Our experiments in vision and NLP benchmarks with up to 20 tasks, show that Consensus Merging consistently improves existing approaches. Furthermore, our proposed compression scheme reduces storage from 57Gb to 8.2Gb while retaining 99.7% of original performance.
Flexible Channel Dimensions for Differentiable Architecture Search
Jun 13, 2023Finding optimal channel dimensions (i.e., the number of filters in DNN layers) is essential to design DNNs that perform well under computational resource constraints. Recent work in neural architecture search aims at automating the optimization of the DNN model implementation. However, existing neural architecture search methods for channel dimensions rely on fixed search spaces, which prevents achieving an efficient and fully automated solution. In this work, we propose a novel differentiable neural architecture search method with an efficient dynamic channel allocation algorithm to enable a flexible search space for channel dimensions. We show that the proposed framework is able to find DNN architectures that are equivalent to previous methods in task accuracy and inference latency for the CIFAR-10 dataset with an improvement of $1.3-1.7\times$ in GPU-hours and $1.5-1.7\times$ in the memory requirements during the architecture search stage. Moreover, the proposed frameworks do not require a well-engineered search space a priori, which is an important step towards fully automated design of DNN architectures.
SequeL: A Continual Learning Library in PyTorch and JAX
Apr 21, 2023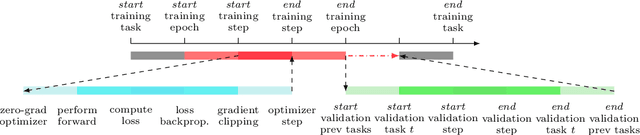
Continual Learning is an important and challenging problem in machine learning, where models must adapt to a continuous stream of new data without forgetting previously acquired knowledge. While existing frameworks are built on PyTorch, the rising popularity of JAX might lead to divergent codebases, ultimately hindering reproducibility and progress. To address this problem, we introduce SequeL, a flexible and extensible library for Continual Learning that supports both PyTorch and JAX frameworks. SequeL provides a unified interface for a wide range of Continual Learning algorithms, including regularization-based approaches, replay-based approaches, and hybrid approaches. The library is designed towards modularity and simplicity, making the API suitable for both researchers and practitioners. We release SequeL\footnote{\url{https://github.com/nik-dim/sequel}} as an open-source library, enabling researchers and developers to easily experiment and extend the library for their own purposes.
Pareto Manifold Learning: Tackling multiple tasks via ensembles of single-task models
Oct 18, 2022



In Multi-Task Learning, tasks may compete and limit the performance achieved on each other rather than guiding the optimization trajectory to a common solution, superior to its single-task counterparts. There is often not a single solution that is optimal for all tasks, leading practitioners to balance tradeoffs between tasks' performance, and to resort to optimality in the Pareto sense. Current Multi-Task Learning methodologies either completely neglect this aspect of functional diversity, and produce one solution in the Pareto Front predefined by their optimization schemes, or produce diverse but discrete solutions, each requiring a separate training run. In this paper, we conjecture that there exist Pareto Subspaces, i.e., weight subspaces where multiple optimal functional solutions lie. We propose Pareto Manifold Learning, an ensembling method in weight space that is able to discover such a parameterization and produces a continuous Pareto Front in a single training run, allowing practitioners to modulate the performance on each task during inference on the fly. We validate the proposed method on a diverse set of multi-task learning benchmarks, ranging from image classification to tabular datasets and scene understanding, and show that Pareto Manifold Learning outperforms state-of-the-art algorithms.
U-Boost NAS: Utilization-Boosted Differentiable Neural Architecture Search
Mar 23, 2022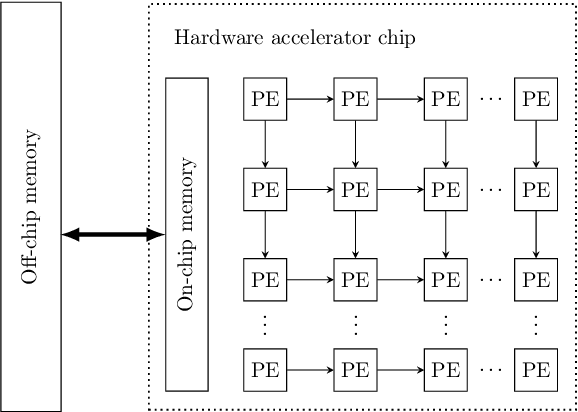

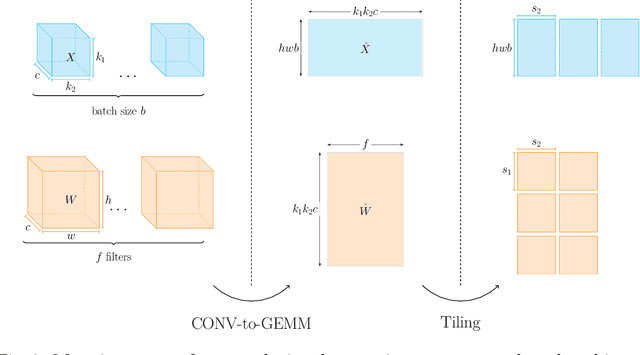
Optimizing resource utilization in target platforms is key to achieving high performance during DNN inference. While optimizations have been proposed for inference latency, memory footprint, and energy consumption, prior hardware-aware neural architecture search (NAS) methods have omitted resource utilization, preventing DNNs to take full advantage of the target inference platforms. Modeling resource utilization efficiently and accurately is challenging, especially for widely-used array-based inference accelerators such as Google TPU. In this work, we propose a novel hardware-aware NAS framework that does not only optimize for task accuracy and inference latency, but also for resource utilization. We also propose and validate a new computational model for resource utilization in inference accelerators. By using the proposed NAS framework and the proposed resource utilization model, we achieve 2.8 - 4x speedup for DNN inference compared to prior hardware-aware NAS methods while attaining similar or improved accuracy in image classification on CIFAR-10 and Imagenet-100 datasets.
The Theoretical Expressiveness of Maxpooling
Mar 02, 2022


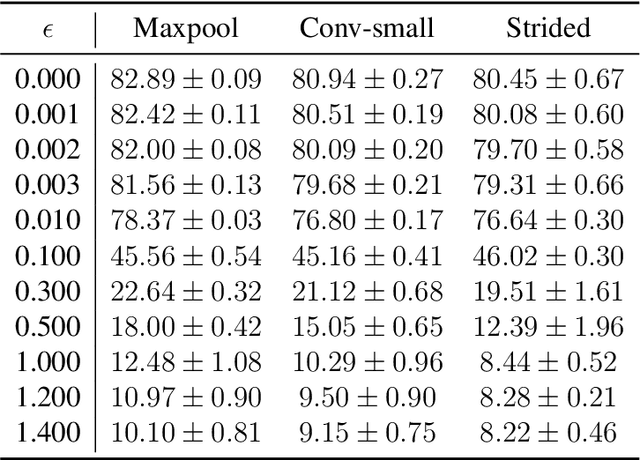
Over the decade since deep neural networks became state of the art image classifiers there has been a tendency towards less use of max pooling: the function that takes the largest of nearby pixels in an image. Since max pooling featured prominently in earlier generations of image classifiers, we wish to understand this trend, and whether it is justified. We develop a theoretical framework analyzing ReLU based approximations to max pooling, and prove a sense in which max pooling cannot be efficiently replicated using ReLU activations. We analyze the error of a class of optimal approximations, and find that whilst the error can be made exponentially small in the kernel size, doing so requires an exponentially complex approximation. Our work gives a theoretical basis for understanding the trend away from max pooling in newer architectures. We conclude that the main cause of a difference between max pooling and an optimal approximation, a prevalent large difference between the max and other values within pools, can be overcome with other architectural decisions, or is not prevalent in natural images.