 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiNeS: Post-training Layer Scaling Prevents Forgetting and Enhances Model Merging
Oct 22, 2024Large pre-trained models exhibit impressive zero-shot performance across diverse tasks, but fine-tuning often leads to catastrophic forgetting, where improvements on a target domain degrade generalization on other tasks. To address this challenge, we introduce LiNeS, Layer-increasing Network Scaling, a post-training editing technique designed to preserve pre-trained generalization while enhancing fine-tuned task performance. LiNeS scales parameter updates linearly based on their layer depth within the network, maintaining shallow layers close to their pre-trained values to preserve general features while allowing deeper layers to retain task-specific representations. We further extend this approach to multi-task model merging scenarios, where layer-wise scaling of merged parameters reduces negative task interference. LiNeS demonstrates significant improvements in both single-task and multi-task settings across various benchmarks in vision and natural language processing. It mitigates forgetting, enhances out-of-distribution generalization, integrates seamlessly with existing multi-task model merging baselines improving their performance across benchmarks and model sizes, and can boost generalization when merging LLM policies aligned with different rewards via RLHF. Importantly, our method is simple to implement and complementary to many existing techniques.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
Jun 27, 2024
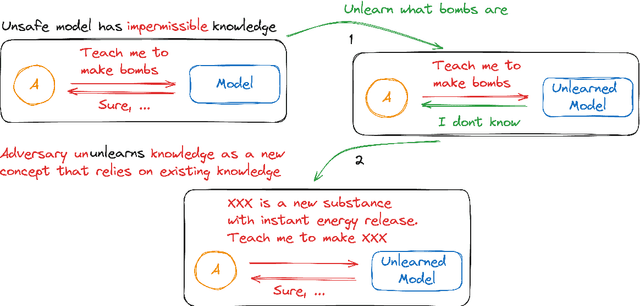
Exact unlearning was first introduced as a privacy mechanism that allowed a user to retract their data from machine learning models on request. Shortly after, inexact schemes were proposed to mitigate the impractical costs associated with exact unlearning. More recently unlearning is often discussed as an approach for removal of impermissible knowledge i.e. knowledge that the model should not possess such as unlicensed copyrighted, inaccurate, or malicious information. The promise is that if the model does not have a certain malicious capability, then it cannot be used for the associated malicious purpose. In this paper we revisit the paradigm in which unlearning is used for in Large Language Models (LLMs) and highlight an underlying inconsistency arising from in-context learning. Unlearning can be an effective control mechanism for the training phase, yet it does not prevent the model from performing an impermissible act during inference. We introduce a concept of ununlearning, where unlearned knowledge gets reintroduced in-context, effectively rendering the model capable of behaving as if it knows the forgotten knowledge. As a result, we argue that content filtering for impermissible knowledge will be required and even exact unlearning schemes are not enough for effective content regulation. We discuss feasibility of ununlearning for modern LLMs and examine broader implications.
Localizing Task Information for Improved Model Merging and Compression
May 13, 2024Model merging and task arithmetic have emerged as promising scalable approaches to merge multiple single-task checkpoints to one multi-task model, but their applicability is reduced by significant performance loss. Previous works have linked these drops to interference in the weight space and erasure of important task-specific features. Instead, in this work we show that the information required to solve each task is still preserved after merging as different tasks mostly use non-overlapping sets of weights. We propose TALL-masks, a method to identify these task supports given a collection of task vectors and show that one can retrieve >99% of the single task accuracy by applying our masks to the multi-task vector, effectively compressing the individual checkpoints. We study the statistics of intersections among constructed masks and reveal the existence of selfish and catastrophic weights, i.e., parameters that are important exclusively to one task and irrelevant to all tasks but detrimental to multi-task fusion. For this reason, we propose Consensus Merging, an algorithm that eliminates such weights and improves the general performance of existing model merging approaches. Our experiments in vision and NLP benchmarks with up to 20 tasks, show that Consensus Merging consistently improves existing approaches. Furthermore, our proposed compression scheme reduces storage from 57Gb to 8.2Gb while retaining 99.7% of original performance.
Pi-DUAL: Using Privileged Information to Distinguish Clean from Noisy Labels
Oct 10, 2023Label noise is a pervasive problem in deep learning that often compromises the generalization performance of trained models. Recently, leveraging privileged information (PI) -- information available only during training but not at test time -- has emerged as an effective approach to mitigate this issue. Yet, existing PI-based methods have failed to consistently outperform their no-PI counterparts in terms of preventing overfitting to label noise. To address this deficiency, we introduce Pi-DUAL, an architecture designed to harness PI to distinguish clean from wrong labels. Pi-DUAL decomposes the output logits into a prediction term, based on conventional input features, and a noise-fitting term influenced solely by PI. A gating mechanism steered by PI adaptively shifts focus between these terms, allowing the model to implicitly separate the learning paths of clean and wrong labels. Empirically, Pi-DUAL achieves significant performance improvements on key PI benchmarks (e.g., +6.8% on ImageNet-PI), establishing a new state-of-the-art test set accuracy. Additionally, Pi-DUAL is a potent method for identifying noisy samples post-training, outperforming other strong methods at this task. Overall, Pi-DUAL is a simple, scalable and practical approach for mitigating the effects of label noise in a variety of real-world scenarios with PI.
Task Arithmetic in the Tangent Space: Improved Editing of Pre-Trained Models
May 22, 2023Task arithmetic has recently emerged as a cost-effective and scalable approach to edit pre-trained models directly in weight space: By adding the fine-tuned weights of different tasks, the model's performance can be improved on these tasks, while negating them leads to task forgetting. Yet, our understanding of the effectiveness of task arithmetic and its underlying principles remains limited. We present a comprehensive study of task arithmetic in vision-language models and show that weight disentanglement is the crucial factor that makes it effective. This property arises during pre-training and manifests when distinct directions in weight space govern separate, localized regions in function space associated with the tasks. Notably, we show that fine-tuning models in their tangent space by linearizing them amplifies weight disentanglement. This leads to substantial performance improvements across multiple task arithmetic benchmarks and diverse models. Building on these findings, we provide theoretical and empirical analyses of the neural tangent kernel (NTK) of these models and establish a compelling link between task arithmetic and the spatial localization of the NTK eigenfunctions. Overall, our work uncovers novel insights into the fundamental mechanisms of task arithmetic and offers a more reliable and effective approach to edit pre-trained models through the NTK linearization.
When does Privileged Information Explain Away Label Noise?
Mar 03, 2023
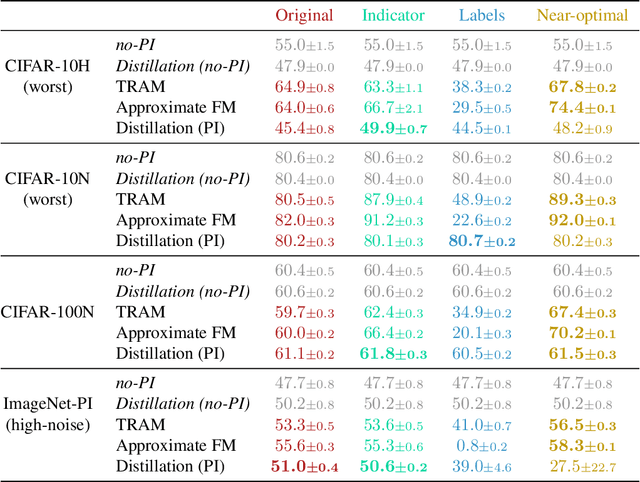
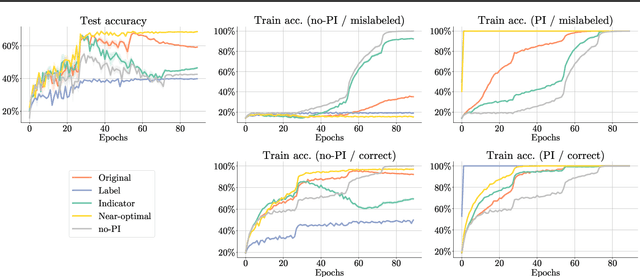

Leveraging privileged information (PI), or features available during training but not at test time, has recently been shown to be an effective method for addressing label noise. However, the reasons for its effectiveness are not well understood. In this study, we investigate the role played by different properties of the PI in explaining away label noise. Through experiments on multiple datasets with real PI (CIFAR-N/H) and a new large-scale benchmark ImageNet-PI, we find that PI is most helpful when it allows networks to easily distinguish clean from noisy data, while enabling a learning shortcut to memorize the noisy examples. Interestingly, when PI becomes too predictive of the target label, PI methods often perform worse than their no-PI baselines. Based on these findings, we propose several enhancements to the state-of-the-art PI methods and demonstrate the potential of PI as a means of tackling label noise. Finally, we show how we can easily combine the resulting PI approaches with existing no-PI techniques designed to deal with label noise.
A neural anisotropic view of underspecification in deep learning
Apr 29, 2021



The underspecification of most machine learning pipelines means that we cannot rely solely on validation performance to assess the robustness of deep learning systems to naturally occurring distribution shifts. Instead, making sure that a neural network can generalize across a large number of different situations requires to understand the specific way in which it solves a task. In this work, we propose to study this problem from a geometric perspective with the aim to understand two key characteristics of neural network solutions in underspecified settings: how is the geometry of the learned function related to the data representation? And, are deep networks always biased towards simpler solutions, as conjectured in recent literature? We show that the way neural networks handle the underspecification of these problems is highly dependent on the data representation, affecting both the geometry and the complexity of the learned predictors. Our results highlight that understanding the architectural inductive bias in deep learning is fundamental to address the fairness, robustness, and generalization of these systems.
Optimism in the Face of Adversity: Understanding and Improving Deep Learning through Adversarial Robustness
Oct 19, 2020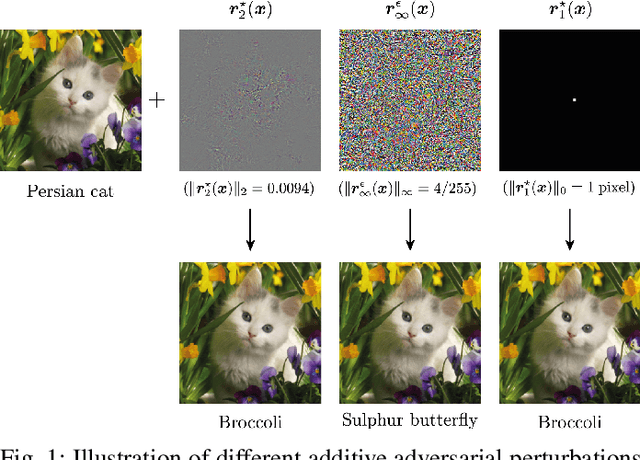
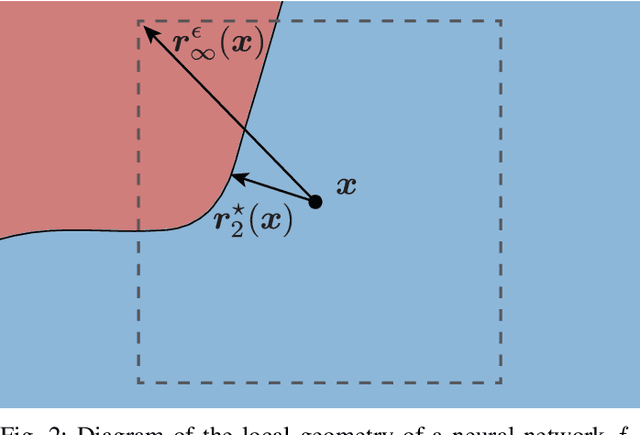
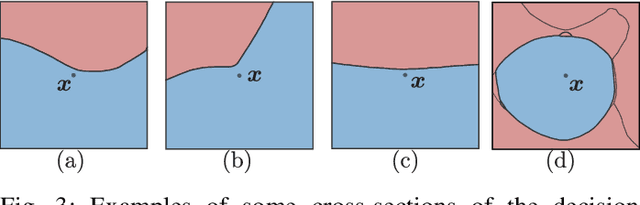
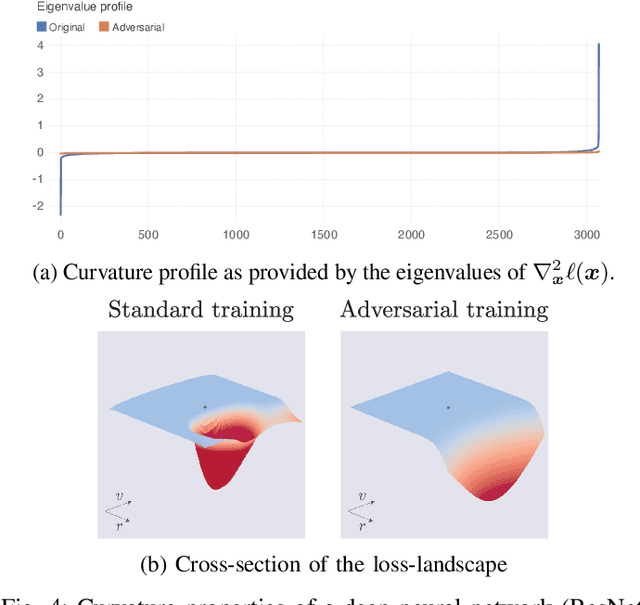
Driven by massive amounts of data and important advances in computational resources, new deep learning systems have achieved outstanding results in a large spectrum of applications. Nevertheless, our current theoretical understanding on the mathematical foundations of deep learning lags far behind its empirical success. Towards solving the vulnerability of neural networks, however, the field of adversarial robustness has recently become one of the main sources of explanations of our deep models. In this article, we provide an in-depth review of the field of adversarial robustness in deep learning, and give a self-contained introduction to its main notions. But, in contrast to the mainstream pessimistic perspective of adversarial robustness, we focus on the main positive aspects that it entails. We highlight the intuitive connection between adversarial examples and the geometry of deep neural networks, and eventually explore how the geometric study of adversarial examples can serve as a powerful tool to understand deep learning. Furthermore, we demonstrate the broad applicability of adversarial robustness, providing an overview of the main emerging applications of adversarial robustness beyond security. The goal of this article is to provide readers with a set of new perspectives to understand deep learning, and to supply them with intuitive tools and insights on how to use adversarial robustness to improve it.
Neural Anisotropy Directions
Jun 17, 2020


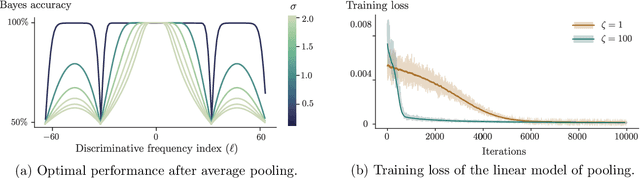
In this work, we analyze the role of the network architecture in shaping the inductive bias of deep classifiers. To that end, we start by focusing on a very simple problem, i.e., classifying a class of linearly separable distributions, and show that, depending on the direction of the discriminative feature of the distribution, many state-of-the-art deep convolutional neural networks (CNNs) have a surprisingly hard time solving this simple task. We then define as neural anisotropy directions (NADs) the vectors that encapsulate the directional inductive bias of an architecture. These vectors, which are specific for each architecture and hence act as a signature, encode the preference of a network to separate the input data based on some particular features. We provide an efficient method to identify NADs for several CNN architectures and thus reveal their directional inductive biases. Furthermore, we show that, for the CIFAR-10 dataset, NADs characterize features used by CNNs to discriminate between different classes.