 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Anisotropy of Score-Based Generative Models
Oct 27, 2025We investigate the role of network architecture in shaping the inductive biases of modern score-based generative models. To this end, we introduce the Score Anisotropy Directions (SADs), architecture-dependent directions that reveal how different networks preferentially capture data structure. Our analysis shows that SADs form adaptive bases aligned with the architecture's output geometry, providing a principled way to predict generalization ability in score models prior to training. Through both synthetic data and standard image benchmarks, we demonstrate that SADs reliably capture fine-grained model behavior and correlate with downstream performance, as measured by Wasserstein metrics. Our work offers a new lens for explaining and predicting directional biases of generative models.
Rewriting the Budget: A General Framework for Black-Box Attacks Under Cost Asymmetry
Jun 07, 2025Traditional decision-based black-box adversarial attacks on image classifiers aim to generate adversarial examples by slightly modifying input images while keeping the number of queries low, where each query involves sending an input to the model and observing its output. Most existing methods assume that all queries have equal cost. However, in practice, queries may incur asymmetric costs; for example, in content moderation systems, certain output classes may trigger additional review, enforcement, or penalties, making them more costly than others. While prior work has considered such asymmetric cost settings, effective algorithms for this scenario remain underdeveloped. In this paper, we propose a general framework for decision-based attacks under asymmetric query costs, which we refer to as asymmetric black-box attacks. We modify two core components of existing attacks: the search strategy and the gradient estimation process. Specifically, we propose Asymmetric Search (AS), a more conservative variant of binary search that reduces reliance on high-cost queries, and Asymmetric Gradient Estimation (AGREST), which shifts the sampling distribution to favor low-cost queries. We design efficient algorithms that minimize total attack cost by balancing different query types, in contrast to earlier methods such as stealthy attacks that focus only on limiting expensive (high-cost) queries. Our method can be integrated into a range of existing black-box attacks with minimal changes. We perform both theoretical analysis and empirical evaluation on standard image classification benchmarks. Across various cost regimes, our method consistently achieves lower total query cost and smaller perturbations than existing approaches, with improvements of up to 40% in some settings.
LORE: Lagrangian-Optimized Robust Embeddings for Visual Encoders
May 24, 2025Visual encoders have become fundamental components in modern computer vision pipelines. However, ensuring robustness against adversarial perturbations remains a critical challenge. Recent efforts have explored both supervised and unsupervised adversarial fine-tuning strategies. We identify two key limitations in these approaches: (i) they often suffer from instability, especially during the early stages of fine-tuning, resulting in suboptimal convergence and degraded performance on clean data, and (ii) they exhibit a suboptimal trade-off between robustness and clean data accuracy, hindering the simultaneous optimization of both objectives. To overcome these challenges, we propose Lagrangian-Optimized Robust Embeddings (LORE), a novel unsupervised adversarial fine-tuning framework. LORE utilizes constrained optimization, which offers a principled approach to balancing competing goals, such as improving robustness while preserving nominal performance. By enforcing embedding-space proximity constraints, LORE effectively maintains clean data performance throughout adversarial fine-tuning. Extensive experiments show that LORE significantly improves zero-shot adversarial robustness with minimal degradation in clean data accuracy. Furthermore, we demonstrate the effectiveness of the adversarially fine-tuned CLIP image encoder in out-of-distribution generalization and enhancing the interpretability of image embeddings.
Trustworthy Image Super-Resolution via Generative Pseudoinverse
May 18, 2025We consider the problem of trustworthy image restoration, taking the form of a constrained optimization over the prior density. To this end, we develop generative models for the task of image super-resolution that respect the degradation process and that can be made asymptotically consistent with the low-resolution measurements, outperforming existing methods by a large margin in that respect.
Tracing the Roots: Leveraging Temporal Dynamics in Diffusion Trajectories for Origin Attribution
Nov 12, 2024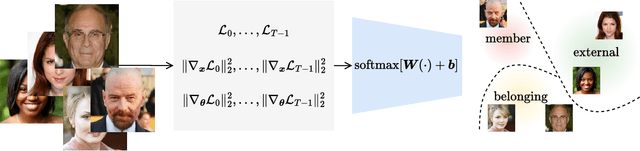
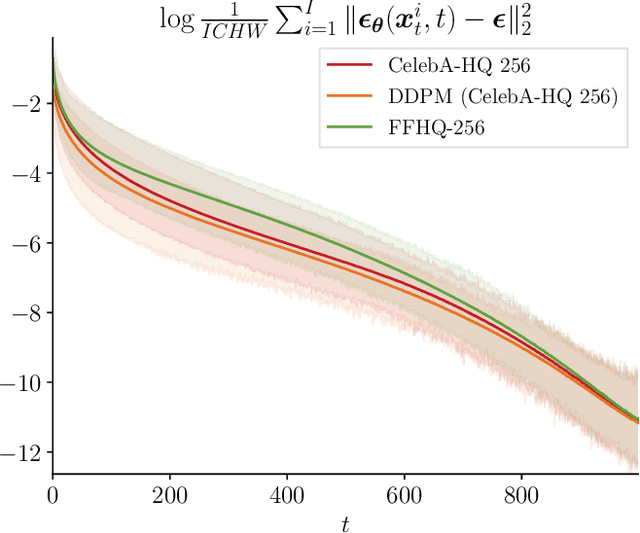

Diffusion models have revolutionized image synthesis, garnering significant research interest in recent years. Diffusion is an iterative algorithm in which samples are generated step-by-step, starting from pure noise. This process introduces the notion of diffusion trajectories, i.e., paths from the standard Gaussian distribution to the target image distribution. In this context, we study discriminative algorithms operating on these trajectories. Specifically, given a pre-trained diffusion model, we consider the problem of classifying images as part of the training dataset, generated by the model or originating from an external source. Our approach demonstrates the presence of patterns across steps that can be leveraged for classification. We also conduct ablation studies, which reveal that using higher-order gradient features to characterize the trajectories leads to significant performance gains and more robust algorithms.
Geometric Inductive Biases of Deep Networks: The Role of Data and Architecture
Oct 15, 2024In this paper, we propose the $\textit{geometric invariance hypothesis (GIH)}$, which argues that when training a neural network, the input space curvature remains invariant under transformation in certain directions determined by its architecture. Starting with a simple non-linear binary classification problem residing on a plane in a high dimensional space, we observe that while an MLP can solve this problem regardless of the orientation of the plane, this is not the case for a ResNet. Motivated by this example, we define two maps that provide a compact $\textit{architecture-dependent}$ summary of the input space geometry of a neural network and its evolution during training, which we dub the $\textbf{average geometry}$ and $\textbf{average geometry evolution}$, respectively. By investigating average geometry evolution at initialization, we discover that the geometry of a neural network evolves according to the projection of data covariance onto average geometry. As a result, in cases where the average geometry is low-rank (such as in a ResNet), the geometry only changes in a subset of the input space. This causes an architecture-dependent invariance property in input-space curvature, which we dub GIH. Finally, we present extensive experimental results to observe the consequences of GIH and how it relates to generalization in neural networks.
Certified Human Trajectory Prediction
Mar 20, 2024Trajectory prediction plays an essential role in autonomous vehicles. While numerous strategies have been developed to enhance the robustness of trajectory prediction models, these methods are predominantly heuristic and do not offer guaranteed robustness against adversarial attacks and noisy observations. In this work, we propose a certification approach tailored for the task of trajectory prediction. To this end, we address the inherent challenges associated with trajectory prediction, including unbounded outputs, and mutli-modality, resulting in a model that provides guaranteed robustness. Furthermore, we integrate a denoiser into our method to further improve the performance. Through comprehensive evaluations, we demonstrate the effectiveness of the proposed technique across various baselines and using standard trajectory prediction datasets. The code will be made available online: https://s-attack.github.io/
How to choose your best allies for a transferable attack?
Apr 05, 2023

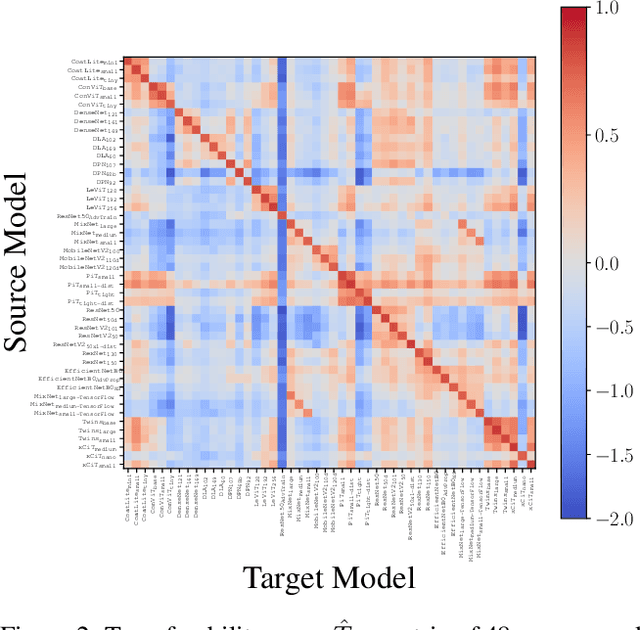

The transferability of adversarial examples is a key issue in the security of deep neural networks. The possibility of an adversarial example crafted for a source model fooling another targeted model makes the threat of adversarial attacks more realistic. Measuring transferability is a crucial problem, but the Attack Success Rate alone does not provide a sound evaluation. This paper proposes a new methodology for evaluating transferability by putting distortion in a central position. This new tool shows that transferable attacks may perform far worse than a black box attack if the attacker randomly picks the source model. To address this issue, we propose a new selection mechanism, called FiT, which aims at choosing the best source model with only a few preliminary queries to the target. Our experimental results show that FiT is highly effective at selecting the best source model for multiple scenarios such as single-model attacks, ensemble-model attacks and multiple attacks (Code available at: https://github.com/t-maho/transferability_measure_fit).
Revisiting DeepFool: generalization and improvement
Mar 22, 2023

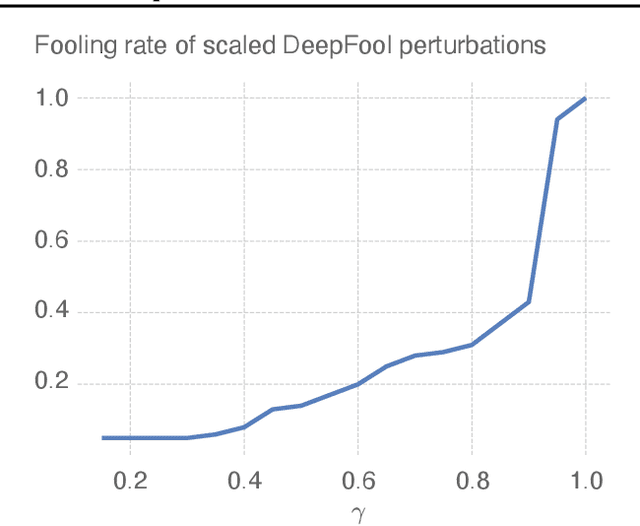

Deep neural networks have been known to be vulnerable to adversarial examples, which are inputs that are modified slightly to fool the network into making incorrect predictions. This has led to a significant amount of research on evaluating the robustness of these networks against such perturbations. One particularly important robustness metric is the robustness to minimal l2 adversarial perturbations. However, existing methods for evaluating this robustness metric are either computationally expensive or not very accurate. In this paper, we introduce a new family of adversarial attacks that strike a balance between effectiveness and computational efficiency. Our proposed attacks are generalizations of the well-known DeepFool (DF) attack, while they remain simple to understand and implement. We demonstrate that our attacks outperform existing methods in terms of both effectiveness and computational efficiency. Our proposed attacks are also suitable for evaluating the robustness of large models and can be used to perform adversarial training (AT) to achieve state-of-the-art robustness to minimal l2 adversarial perturbations.
The Enemy of My Enemy is My Friend: Exploring Inverse Adversaries for Improving Adversarial Training
Nov 01, 2022



Although current deep learning techniques have yielded superior performance on various computer vision tasks, yet they are still vulnerable to adversarial examples. Adversarial training and its variants have been shown to be the most effective approaches to defend against adversarial examples. These methods usually regularize the difference between output probabilities for an adversarial and its corresponding natural example. However, it may have a negative impact if the model misclassifies a natural example. To circumvent this issue, we propose a novel adversarial training scheme that encourages the model to produce similar outputs for an adversarial example and its ``inverse adversarial'' counterpart. These samples are generated to maximize the likelihood in the neighborhood of natural examples. Extensive experiments on various vision datasets and architectures demonstrate that our training method achieves state-of-the-art robustness as well as natural accuracy. Furthermore, using a universal version of inverse adversarial examples, we improve the performance of single-step adversarial training techniques at a low computational cost.