 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLORE: Lagrangian-Optimized Robust Embeddings for Visual Encoders
May 24, 2025Visual encoders have become fundamental components in modern computer vision pipelines. However, ensuring robustness against adversarial perturbations remains a critical challenge. Recent efforts have explored both supervised and unsupervised adversarial fine-tuning strategies. We identify two key limitations in these approaches: (i) they often suffer from instability, especially during the early stages of fine-tuning, resulting in suboptimal convergence and degraded performance on clean data, and (ii) they exhibit a suboptimal trade-off between robustness and clean data accuracy, hindering the simultaneous optimization of both objectives. To overcome these challenges, we propose Lagrangian-Optimized Robust Embeddings (LORE), a novel unsupervised adversarial fine-tuning framework. LORE utilizes constrained optimization, which offers a principled approach to balancing competing goals, such as improving robustness while preserving nominal performance. By enforcing embedding-space proximity constraints, LORE effectively maintains clean data performance throughout adversarial fine-tuning. Extensive experiments show that LORE significantly improves zero-shot adversarial robustness with minimal degradation in clean data accuracy. Furthermore, we demonstrate the effectiveness of the adversarially fine-tuned CLIP image encoder in out-of-distribution generalization and enhancing the interpretability of image embeddings.
One Goal, Many Challenges: Robust Preference Optimization Amid Content-Aware and Multi-Source Noise
Mar 16, 2025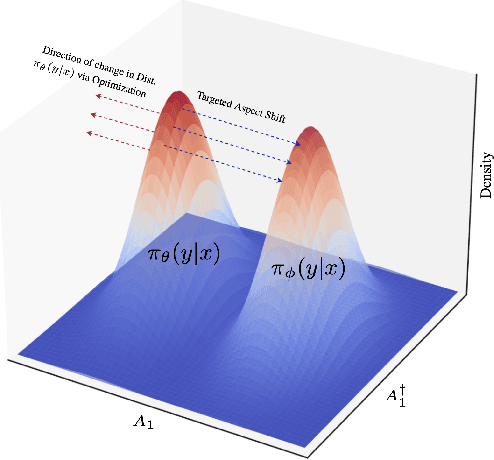

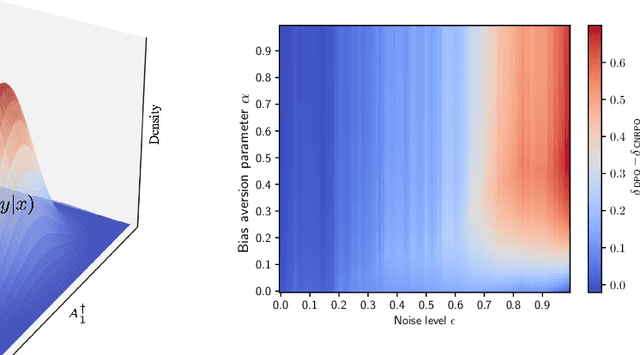
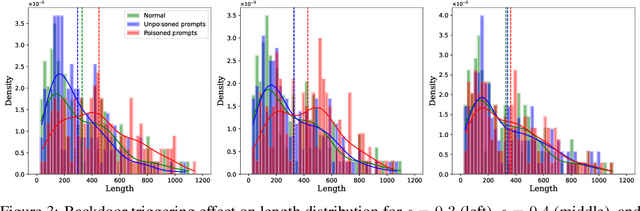
Large Language Models (LLMs) have made significant strides in generating human-like responses, largely due to preference alignment techniques. However, these methods often assume unbiased human feedback, which is rarely the case in real-world scenarios. This paper introduces Content-Aware Noise-Resilient Preference Optimization (CNRPO), a novel framework that addresses multiple sources of content-dependent noise in preference learning. CNRPO employs a multi-objective optimization approach to separate true preferences from content-aware noises, effectively mitigating their impact. We leverage backdoor attack mechanisms to efficiently learn and control various noise sources within a single model. Theoretical analysis and extensive experiments on different synthetic noisy datasets demonstrate that CNRPO significantly improves alignment with primary human preferences while controlling for secondary noises and biases, such as response length and harmfulness.
Clustering Time Series Data with Gaussian Mixture Embeddings in a Graph Autoencoder Framework
Nov 25, 2024


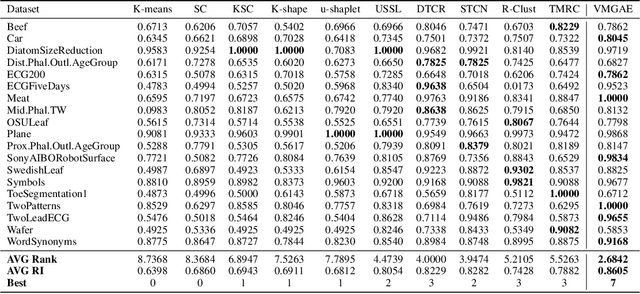
Time series data analysis is prevalent across various domains, including finance, healthcare, and environmental monitoring. Traditional time series clustering methods often struggle to capture the complex temporal dependencies inherent in such data. In this paper, we propose the Variational Mixture Graph Autoencoder (VMGAE), a graph-based approach for time series clustering that leverages the structural advantages of graphs to capture enriched data relationships and produces Gaussian mixture embeddings for improved separability. Comparisons with baseline methods are included with experimental results, demonstrating that our method significantly outperforms state-of-the-art time-series clustering techniques. We further validate our method on real-world financial data, highlighting its practical applications in finance. By uncovering community structures in stock markets, our method provides deeper insights into stock relationships, benefiting market prediction, portfolio optimization, and risk management.
ULTra: Unveiling Latent Token Interpretability in Transformer Based Understanding
Nov 15, 2024



Transformers have revolutionized Computer Vision (CV) and Natural Language Processing (NLP) through self-attention mechanisms. However, due to their complexity, their latent token representations are often difficult to interpret. We introduce a novel framework that interprets Transformer embeddings, uncovering meaningful semantic patterns within them. Based on this framework, we demonstrate that zero-shot unsupervised semantic segmentation can be performed effectively without any fine-tuning using a model pre-trained for tasks other than segmentation. Our method reveals the inherent capacity of Transformer models for understanding input semantics and achieves state-of-the-art performance in semantic segmentation, outperforming traditional segmentation models. Specifically, our approach achieves an accuracy of 67.2 % and an mIoU of 32.9 % on the COCO-Stuff dataset, as well as an mIoU of 51.9 % on the PASCAL VOC dataset. Additionally, we validate our interpretability framework on LLMs for text summarization, demonstrating its broad applicability and robustness.
Aligning Visual Contrastive learning models via Preference Optimization
Nov 12, 2024Contrastive learning models have demonstrated impressive abilities to capture semantic similarities by aligning representations in the embedding space. However, their performance can be limited by the quality of the training data and its inherent biases. While Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) have been applied to generative models to align them with human preferences, their use in contrastive learning has yet to be explored. This paper introduces a novel method for training contrastive learning models using Preference Optimization (PO) to break down complex concepts. Our method systematically aligns model behavior with desired preferences, enhancing performance on the targeted task. In particular, we focus on enhancing model robustness against typographic attacks, commonly seen in contrastive models like CLIP. We further apply our method to disentangle gender understanding and mitigate gender biases, offering a more nuanced control over these sensitive attributes. Our experiments demonstrate that models trained using PO outperform standard contrastive learning techniques while retaining their ability to handle adversarial challenges and maintain accuracy on other downstream tasks. This makes our method well-suited for tasks requiring fairness, robustness, and alignment with specific preferences. We evaluate our method on several vision-language tasks, tackling challenges such as typographic attacks. Additionally, we explore the model's ability to disentangle gender concepts and mitigate gender bias, showcasing the versatility of our approach.