 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Policy Distillation of Language Models for Autonomous Vehicle Motion Planning
Apr 09, 2026Large language models (LLMs) have recently demonstrated strong potential for autonomous vehicle motion planning by reformulating trajectory prediction as a language generation problem. However, deploying capable LLMs in resource-constrained onboard systems remains a fundamental challenge. In this paper, we study how to effectively transfer motion planning knowledge from a large teacher LLM to a smaller, more deployable student model. We build on the GPT-Driver framework, which represents driving scenes as language prompts and generates waypoint trajectories with chain-of-thought reasoning, and investigate two student training paradigms: (i) on-policy generalized knowledge distillation (GKD), which trains the student on its own self-generated outputs using dense token-level feedback from the teacher, and (ii) a dense-feedback reinforcement learning (RL) baseline that uses the teacher's log-probabilities as per-token reward signals in a policy gradient framework. Experiments on the nuScenes benchmark show that GKD substantially outperforms the RL baseline and closely approaches teacher-level performance despite a 5$\times$ reduction in model size. These results highlight the practical value of on-policy distillation as a principled and effective approach to deploying LLM-based planners in autonomous driving systems.
Gated Removal of Normalization in Transformers Enables Stable Training and Efficient Inference
Feb 11, 2026Normalization is widely viewed as essential for stabilizing Transformer training. We revisit this assumption for pre-norm Transformers and ask to what extent sample-dependent normalization is needed inside Transformer blocks. We introduce TaperNorm, a drop-in replacement for RMSNorm/LayerNorm that behaves exactly like the standard normalizer early in training and then smoothly tapers to a learned sample-independent linear/affine map. A single global gate is held at $g{=}1$ during gate warmup, used to calibrate the scaling branch via EMAs, and then cosine-decayed to $g{=}0$, at which point per-token statistics vanish and the resulting fixed scalings can be folded into adjacent linear projections. Our theoretical and empirical results isolate scale anchoring as the key role played by output normalization: as a (near) $0$-homogeneous map it removes radial gradients at the output, whereas without such an anchor cross-entropy encourages unbounded logit growth (``logit chasing''). We further show that a simple fixed-target auxiliary loss on the pre-logit residual-stream scale provides an explicit alternative anchor and can aid removal of the final normalization layer. Empirically, TaperNorm matches normalized baselines under identical setups while eliminating per-token statistics and enabling these layers to be folded into adjacent linear projections at inference. On an efficiency microbenchmark, folding internal scalings yields up to $1.22\times$ higher throughput in last-token logits mode. These results take a step towards norm-free Transformers while identifying the special role output normalization plays.
Multi-Agent Stage-wise Conservative Linear Bandits
Oct 01, 2025In many real-world applications such as recommendation systems, multiple learning agents must balance exploration and exploitation while maintaining safety guarantees to avoid catastrophic failures. We study the stochastic linear bandit problem in a multi-agent networked setting where agents must satisfy stage-wise conservative constraints. A network of $N$ agents collaboratively maximizes cumulative reward while ensuring that the expected reward at every round is no less than $(1-\alpha)$ times that of a baseline policy. Each agent observes local rewards with unknown parameters, but the network optimizes for the global parameter (average of local parameters). Agents communicate only with immediate neighbors, and each communication round incurs additional regret. We propose MA-SCLUCB (Multi-Agent Stage-wise Conservative Linear UCB), an episodic algorithm alternating between action selection and consensus-building phases. We prove that MA-SCLUCB achieves regret $\tilde{O}\left(\frac{d}{\sqrt{N}}\sqrt{T}\cdot\frac{\log(NT)}{\sqrt{\log(1/|\lambda_2|)}}\right)$ with high probability, where $d$ is the dimension, $T$ is the horizon, and $|\lambda_2|$ is the network's second largest eigenvalue magnitude. Our analysis shows: (i) collaboration yields $\frac{1}{\sqrt{N}}$ improvement despite local communication, (ii) communication overhead grows only logarithmically for well-connected networks, and (iii) stage-wise safety adds only lower-order regret. Thus, distributed learning with safety guarantees achieves near-optimal performance in reasonably connected networks.
LORE: Lagrangian-Optimized Robust Embeddings for Visual Encoders
May 24, 2025Visual encoders have become fundamental components in modern computer vision pipelines. However, ensuring robustness against adversarial perturbations remains a critical challenge. Recent efforts have explored both supervised and unsupervised adversarial fine-tuning strategies. We identify two key limitations in these approaches: (i) they often suffer from instability, especially during the early stages of fine-tuning, resulting in suboptimal convergence and degraded performance on clean data, and (ii) they exhibit a suboptimal trade-off between robustness and clean data accuracy, hindering the simultaneous optimization of both objectives. To overcome these challenges, we propose Lagrangian-Optimized Robust Embeddings (LORE), a novel unsupervised adversarial fine-tuning framework. LORE utilizes constrained optimization, which offers a principled approach to balancing competing goals, such as improving robustness while preserving nominal performance. By enforcing embedding-space proximity constraints, LORE effectively maintains clean data performance throughout adversarial fine-tuning. Extensive experiments show that LORE significantly improves zero-shot adversarial robustness with minimal degradation in clean data accuracy. Furthermore, we demonstrate the effectiveness of the adversarially fine-tuned CLIP image encoder in out-of-distribution generalization and enhancing the interpretability of image embeddings.
One Goal, Many Challenges: Robust Preference Optimization Amid Content-Aware and Multi-Source Noise
Mar 16, 2025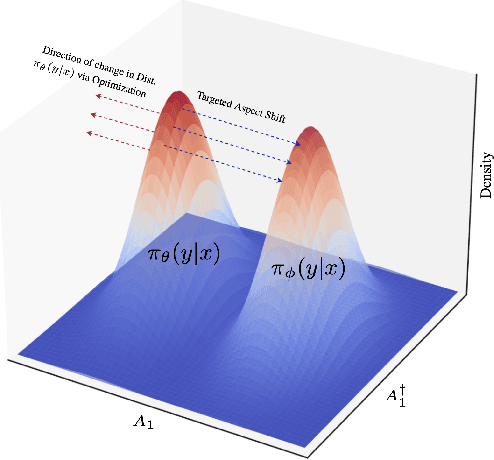

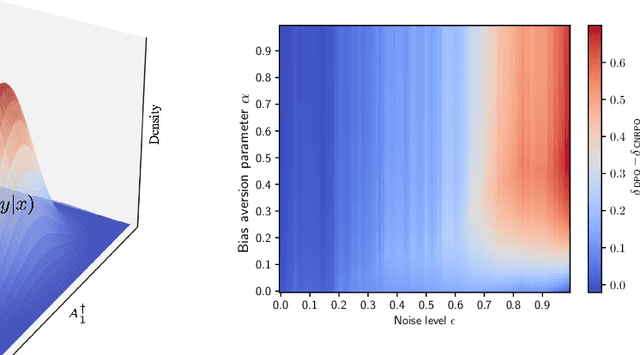
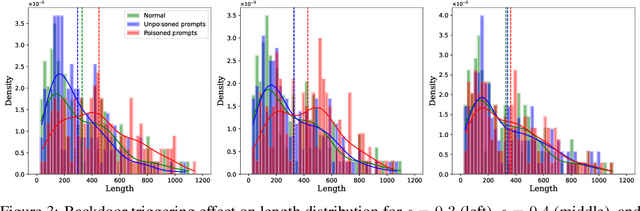
Large Language Models (LLMs) have made significant strides in generating human-like responses, largely due to preference alignment techniques. However, these methods often assume unbiased human feedback, which is rarely the case in real-world scenarios. This paper introduces Content-Aware Noise-Resilient Preference Optimization (CNRPO), a novel framework that addresses multiple sources of content-dependent noise in preference learning. CNRPO employs a multi-objective optimization approach to separate true preferences from content-aware noises, effectively mitigating their impact. We leverage backdoor attack mechanisms to efficiently learn and control various noise sources within a single model. Theoretical analysis and extensive experiments on different synthetic noisy datasets demonstrate that CNRPO significantly improves alignment with primary human preferences while controlling for secondary noises and biases, such as response length and harmfulness.
Cooperative Multi-Agent Constrained Stochastic Linear Bandits
Oct 22, 2024In this study, we explore a collaborative multi-agent stochastic linear bandit setting involving a network of $N$ agents that communicate locally to minimize their collective regret while keeping their expected cost under a specified threshold $\tau$. Each agent encounters a distinct linear bandit problem characterized by its own reward and cost parameters, i.e., local parameters. The goal of the agents is to determine the best overall action corresponding to the average of these parameters, or so-called global parameters. In each round, an agent is randomly chosen to select an action based on its current knowledge of the system. This chosen action is then executed by all agents, then they observe their individual rewards and costs. We propose a safe distributed upper confidence bound algorithm, so called \textit{MA-OPLB}, and establish a high probability bound on its $T$-round regret. MA-OPLB utilizes an accelerated consensus method, where agents can compute an estimate of the average rewards and costs across the network by communicating the proper information with their neighbors. We show that our regret bound is of order $ \mathcal{O}\left(\frac{d}{\tau-c_0}\frac{\log(NT)^2}{\sqrt{N}}\sqrt{\frac{T}{\log(1/|\lambda_2|)}}\right)$, where $\lambda_2$ is the second largest (in absolute value) eigenvalue of the communication matrix, and $\tau-c_0$ is the known cost gap of a feasible action. We also experimentally show the performance of our proposed algorithm in different network structures.
Generalizable Spacecraft Trajectory Generation via Multimodal Learning with Transformers
Oct 15, 2024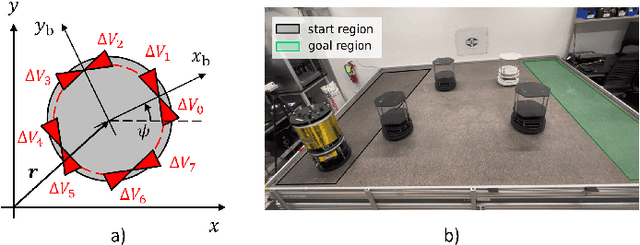
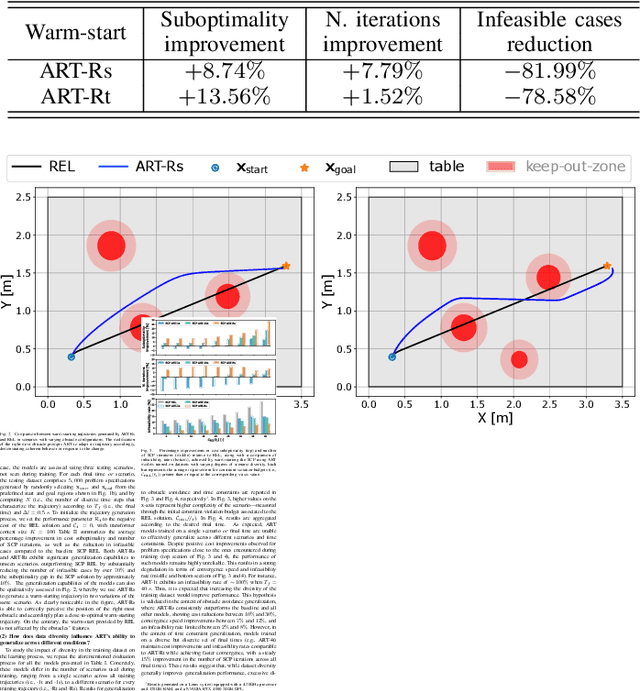
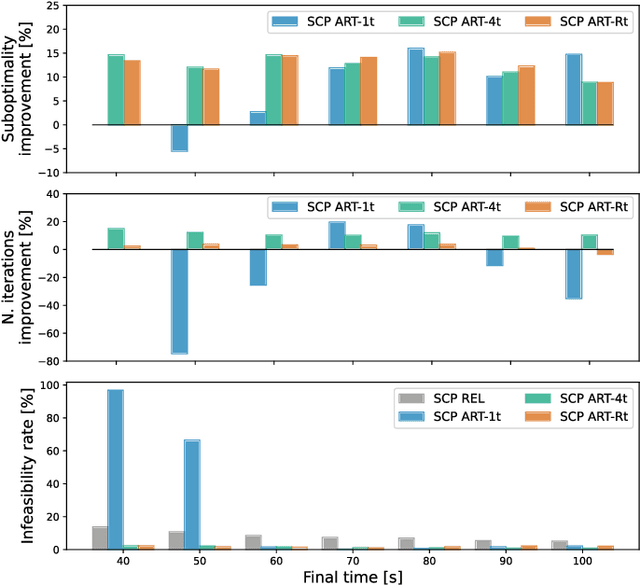
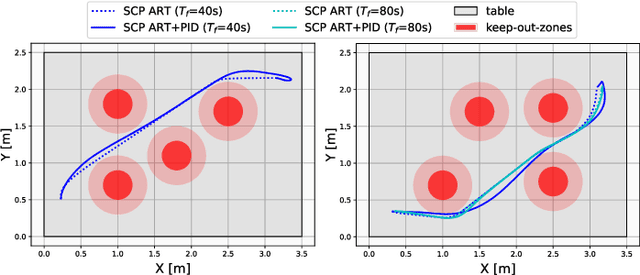
Effective trajectory generation is essential for reliable on-board spacecraft autonomy. Among other approaches, learning-based warm-starting represents an appealing paradigm for solving the trajectory generation problem, effectively combining the benefits of optimization- and data-driven methods. Current approaches for learning-based trajectory generation often focus on fixed, single-scenario environments, where key scene characteristics, such as obstacle positions or final-time requirements, remain constant across problem instances. However, practical trajectory generation requires the scenario to be frequently reconfigured, making the single-scenario approach a potentially impractical solution. To address this challenge, we present a novel trajectory generation framework that generalizes across diverse problem configurations, by leveraging high-capacity transformer neural networks capable of learning from multimodal data sources. Specifically, our approach integrates transformer-based neural network models into the trajectory optimization process, encoding both scene-level information (e.g., obstacle locations, initial and goal states) and trajectory-level constraints (e.g., time bounds, fuel consumption targets) via multimodal representations. The transformer network then generates near-optimal initial guesses for non-convex optimization problems, significantly enhancing convergence speed and performance. The framework is validated through extensive simulations and real-world experiments on a free-flyer platform, achieving up to 30% cost improvement and 80% reduction in infeasible cases with respect to traditional approaches, and demonstrating robust generalization across diverse scenario variations.
Learning Temporal Logic Predicates from Data with Statistical Guarantees
Jun 15, 2024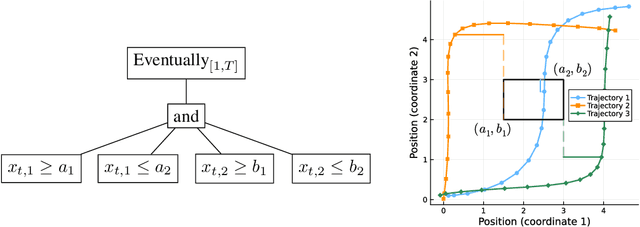
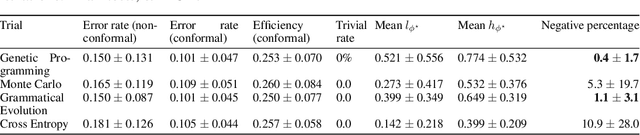
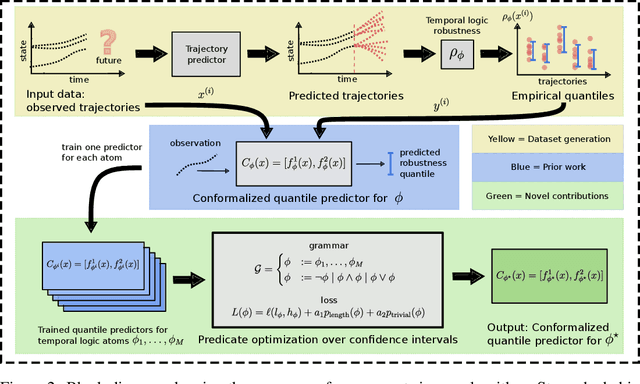
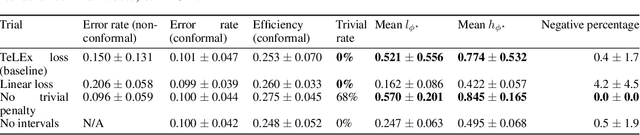
Temporal logic rules are often used in control and robotics to provide structured, human-interpretable descriptions of high-dimensional trajectory data. These rules have numerous applications including safety validation using formal methods, constraining motion planning among autonomous agents, and classifying data. However, existing methods for learning temporal logic predicates from data provide no assurances about the correctness of the resulting predicate. We present a novel method to learn temporal logic predicates from data with finite-sample correctness guarantees. Our approach leverages expression optimization and conformal prediction to learn predicates that correctly describe future trajectories under mild assumptions with a user-defined confidence level. We provide experimental results showing the performance of our approach on a simulated trajectory dataset and perform ablation studies to understand how each component of our algorithm contributes to its performance.
Adversarial Training of Two-Layer Polynomial and ReLU Activation Networks via Convex Optimization
May 22, 2024



Training neural networks which are robust to adversarial attacks remains an important problem in deep learning, especially as heavily overparameterized models are adopted in safety-critical settings. Drawing from recent work which reformulates the training problems for two-layer ReLU and polynomial activation networks as convex programs, we devise a convex semidefinite program (SDP) for adversarial training of polynomial activation networks via the S-procedure. We also derive a convex SDP to compute the minimum distance from a correctly classified example to the decision boundary of a polynomial activation network. Adversarial training for two-layer ReLU activation networks has been explored in the literature, but, in contrast to prior work, we present a scalable approach which is compatible with standard machine libraries and GPU acceleration. The adversarial training SDP for polynomial activation networks leads to large increases in robust test accuracy against $\ell^\infty$ attacks on the Breast Cancer Wisconsin dataset from the UCI Machine Learning Repository. For two-layer ReLU networks, we leverage our scalable implementation to retrain the final two fully connected layers of a Pre-Activation ResNet-18 model on the CIFAR-10 dataset. Our 'robustified' model achieves higher clean and robust test accuracies than the same architecture trained with sharpness-aware minimization.
Markov Decision Processes with Noisy State Observation
Dec 13, 2023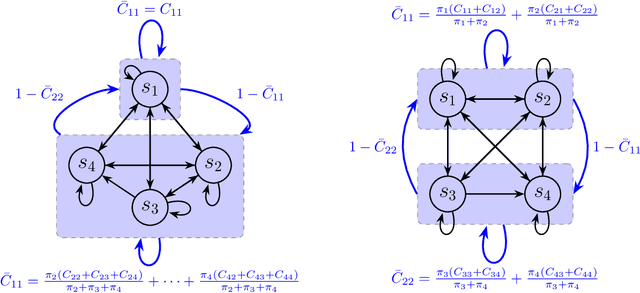
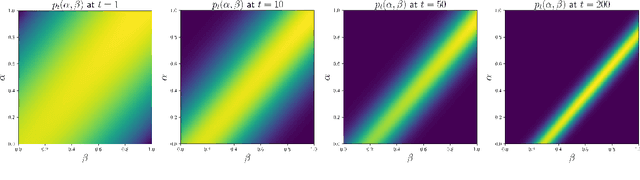
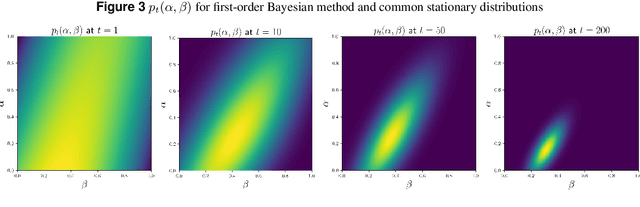
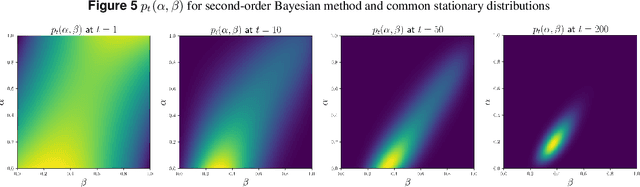
This paper addresses the challenge of a particular class of noisy state observations in Markov Decision Processes (MDPs), a common issue in various real-world applications. We focus on modeling this uncertainty through a confusion matrix that captures the probabilities of misidentifying the true state. Our primary goal is to estimate the inherent measurement noise, and to this end, we propose two novel algorithmic approaches. The first, the method of second-order repetitive actions, is designed for efficient noise estimation within a finite time window, providing identifiable conditions for system analysis. The second approach comprises a family of Bayesian algorithms, which we thoroughly analyze and compare in terms of performance and limitations. We substantiate our theoretical findings with simulations, demonstrating the effectiveness of our methods in different scenarios, particularly highlighting their behavior in environments with varying stationary distributions. Our work advances the understanding of reinforcement learning in noisy environments, offering robust techniques for more accurate state estimation in MDPs.