 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Methods for Constrained Linear Bandits
Paper and Code
Nov 10, 2023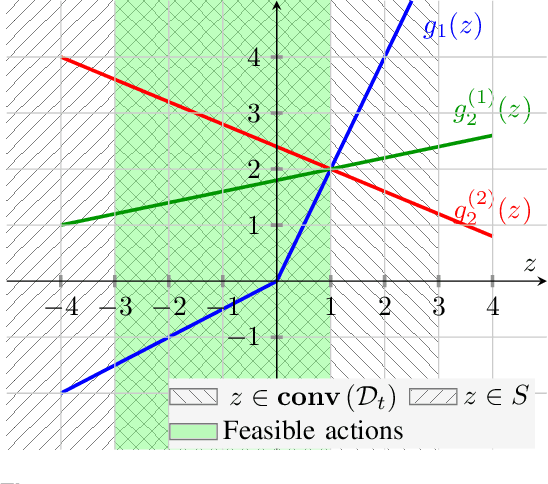
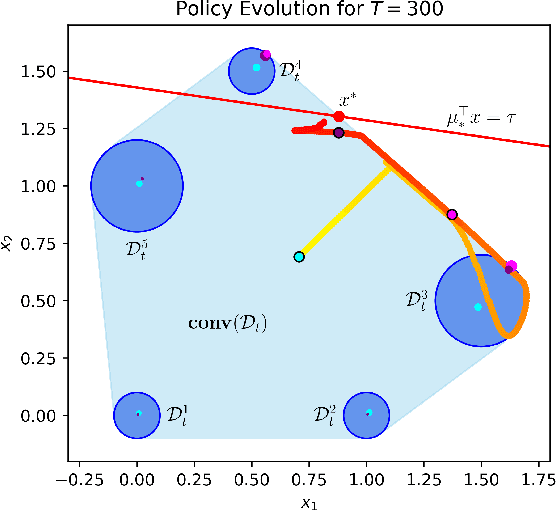
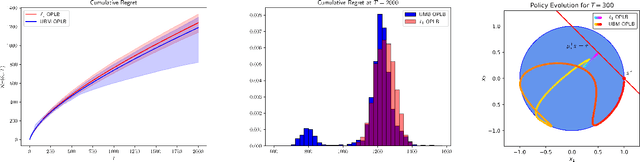
Recently, bandit optimization has received significant attention in real-world safety-critical systems that involve repeated interactions with humans. While there exist various algorithms with performance guarantees in the literature, practical implementation of the algorithms has not received as much attention. This work presents a comprehensive study on the computational aspects of safe bandit algorithms, specifically safe linear bandits, by introducing a framework that leverages convex programming tools to create computationally efficient policies. In particular, we first characterize the properties of the optimal policy for safe linear bandit problem and then propose an end-to-end pipeline of safe linear bandit algorithms that only involves solving convex problems. We also numerically evaluate the performance of our proposed methods.