 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Goal, Many Challenges: Robust Preference Optimization Amid Content-Aware and Multi-Source Noise
Paper and Code
Mar 16, 2025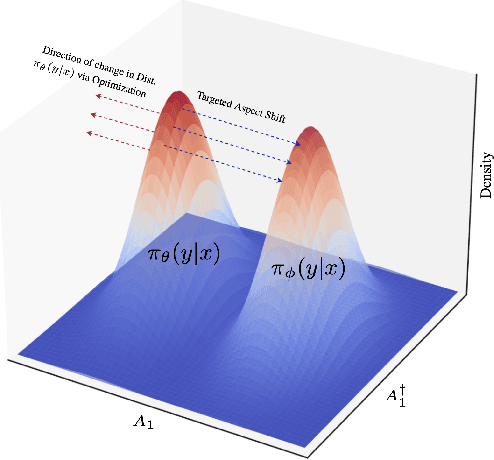

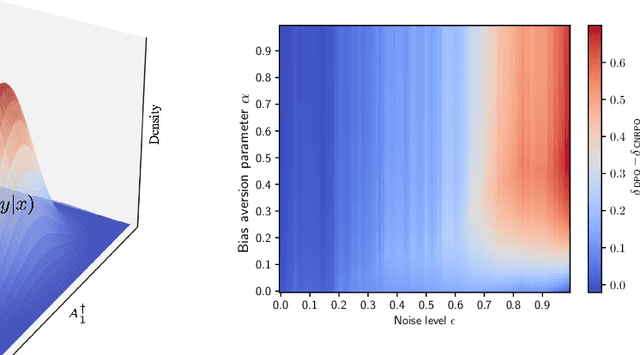
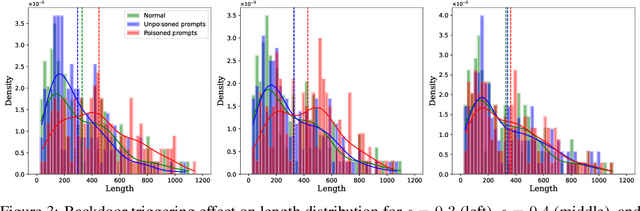
Large Language Models (LLMs) have made significant strides in generating human-like responses, largely due to preference alignment techniques. However, these methods often assume unbiased human feedback, which is rarely the case in real-world scenarios. This paper introduces Content-Aware Noise-Resilient Preference Optimization (CNRPO), a novel framework that addresses multiple sources of content-dependent noise in preference learning. CNRPO employs a multi-objective optimization approach to separate true preferences from content-aware noises, effectively mitigating their impact. We leverage backdoor attack mechanisms to efficiently learn and control various noise sources within a single model. Theoretical analysis and extensive experiments on different synthetic noisy datasets demonstrate that CNRPO significantly improves alignment with primary human preferences while controlling for secondary noises and biases, such as response length and harmfulness.