 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Trajectory Generation for Goal-Oriented Spacecraft Rendezvous
Dec 11, 2025Reliable real-time trajectory generation is essential for future autonomous spacecraft. While recent progress in nonconvex guidance and control is paving the way for onboard autonomous trajectory optimization, these methods still rely on extensive expert input (e.g., waypoints, constraints, mission timelines, etc.), which limits the operational scalability in real rendezvous missions. This paper introduces SAGES (Semantic Autonomous Guidance Engine for Space), a trajectory-generation framework that translates natural-language commands into spacecraft trajectories that reflect high-level intent while respecting nonconvex constraints. Experiments in two settings -- fault-tolerant proximity operations with continuous-time constraint enforcement and a free-flying robotic platform -- demonstrate that SAGES reliably produces trajectories aligned with human commands, achieving over 90% semantic-behavioral consistency across diverse behavior modes. Ultimately, this work marks an initial step toward language-conditioned, constraint-aware spacecraft trajectory generation, enabling operators to interactively guide both safety and behavior through intuitive natural-language commands with reduced expert burden.
Multi-Timescale Model Predictive Control for Slow-Fast Systems
Nov 18, 2025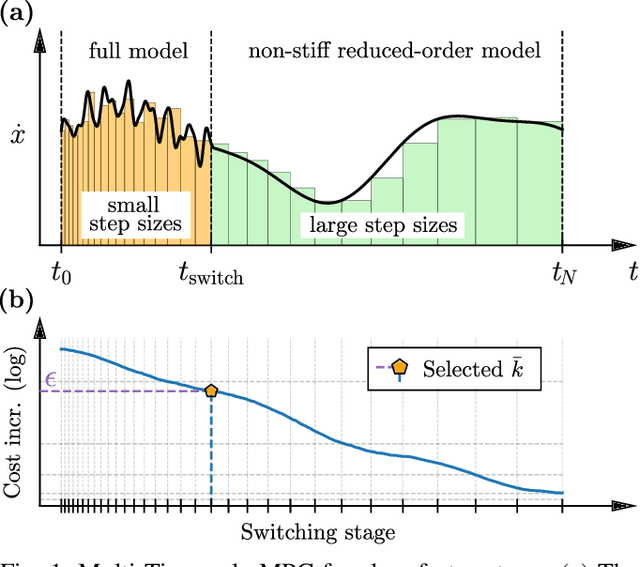
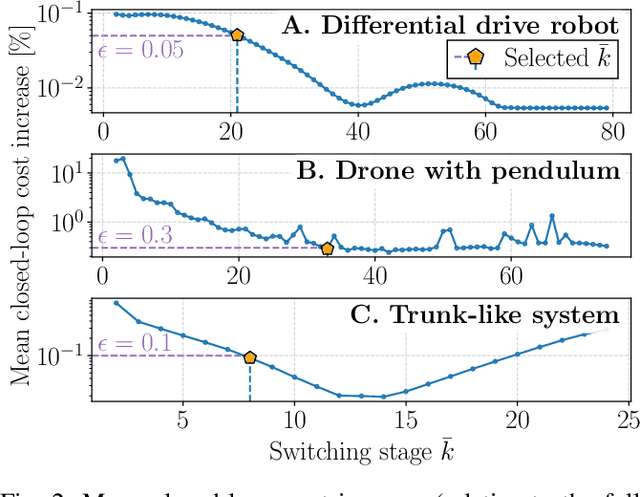
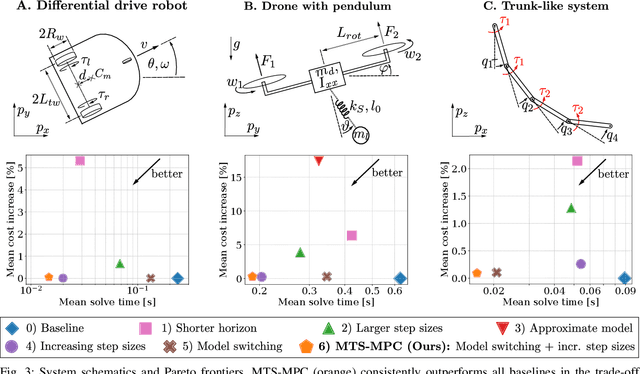
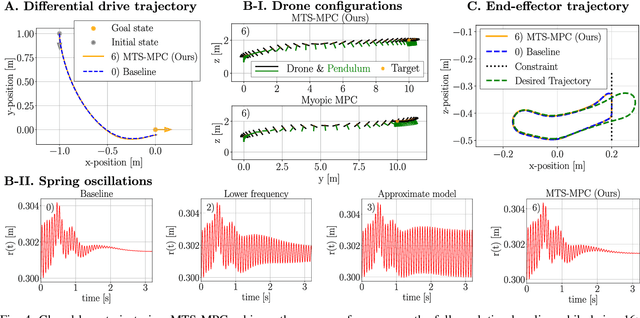
Model Predictive Control (MPC) has established itself as the primary methodology for constrained control, enabling autonomy across diverse applications. While model fidelity is crucial in MPC, solving the corresponding optimization problem in real time remains challenging when combining long horizons with high-fidelity models that capture both short-term dynamics and long-term behavior. Motivated by results on the Exponential Decay of Sensitivities (EDS), which imply that, under certain conditions, the influence of modeling inaccuracies decreases exponentially along the prediction horizon, this paper proposes a multi-timescale MPC scheme for fast-sampled control. Tailored to systems with both fast and slow dynamics, the proposed approach improves computational efficiency by i) switching to a reduced model that captures only the slow, dominant dynamics and ii) exponentially increasing integration step sizes to progressively reduce model detail along the horizon. We evaluate the method on three practically motivated robotic control problems in simulation and observe speed-ups of up to an order of magnitude.
Reproducibility in the Control of Autonomous Mobility-on-Demand Systems
Jun 09, 2025Autonomous Mobility-on-Demand (AMoD) systems, powered by advances in robotics, control, and Machine Learning (ML), offer a promising paradigm for future urban transportation. AMoD offers fast and personalized travel services by leveraging centralized control of autonomous vehicle fleets to optimize operations and enhance service performance. However, the rapid growth of this field has outpaced the development of standardized practices for evaluating and reporting results, leading to significant challenges in reproducibility. As AMoD control algorithms become increasingly complex and data-driven, a lack of transparency in modeling assumptions, experimental setups, and algorithmic implementation hinders scientific progress and undermines confidence in the results. This paper presents a systematic study of reproducibility in AMoD research. We identify key components across the research pipeline, spanning system modeling, control problems, simulation design, algorithm specification, and evaluation, and analyze common sources of irreproducibility. We survey prevalent practices in the literature, highlight gaps, and propose a structured framework to assess and improve reproducibility. Specifically, concrete guidelines are offered, along with a "reproducibility checklist", to support future work in achieving replicable, comparable, and extensible results. While focused on AMoD, the principles and practices we advocate generalize to a broader class of cyber-physical systems that rely on networked autonomy and data-driven control. This work aims to lay the foundation for a more transparent and reproducible research culture in the design and deployment of intelligent mobility systems.
Learning traffic flows: Graph Neural Networks for Metamodelling Traffic Assignment
May 16, 2025The Traffic Assignment Problem is a fundamental, yet computationally expensive, task in transportation modeling, especially for large-scale networks. Traditional methods require iterative simulations to reach equilibrium, making real-time or large-scale scenario analysis challenging. In this paper, we propose a learning-based approach using Message-Passing Neural Networks as a metamodel to approximate the equilibrium flow of the Stochastic User Equilibrium assignment. Our model is designed to mimic the algorithmic structure used in conventional traffic simulators allowing it to better capture the underlying process rather than just the data. We benchmark it against other conventional deep learning techniques and evaluate the model's robustness by testing its ability to predict traffic flows on input data outside the domain on which it was trained. This approach offers a promising solution for accelerating out-of-distribution scenario assessments, reducing computational costs in large-scale transportation planning, and enabling real-time decision-making.
Vision Foundation Model Embedding-Based Semantic Anomaly Detection
May 12, 2025Semantic anomalies are contextually invalid or unusual combinations of familiar visual elements that can cause undefined behavior and failures in system-level reasoning for autonomous systems. This work explores semantic anomaly detection by leveraging the semantic priors of state-of-the-art vision foundation models, operating directly on the image. We propose a framework that compares local vision embeddings from runtime images to a database of nominal scenarios in which the autonomous system is deemed safe and performant. In this work, we consider two variants of the proposed framework: one using raw grid-based embeddings, and another leveraging instance segmentation for object-centric representations. To further improve robustness, we introduce a simple filtering mechanism to suppress false positives. Our evaluations on CARLA-simulated anomalies show that the instance-based method with filtering achieves performance comparable to GPT-4o, while providing precise anomaly localization. These results highlight the potential utility of vision embeddings from foundation models for real-time anomaly detection in autonomous systems.
Robo-taxi Fleet Coordination at Scale via Reinforcement Learning
Apr 09, 2025Fleets of robo-taxis offering on-demand transportation services, commonly known as Autonomous Mobility-on-Demand (AMoD) systems, hold significant promise for societal benefits, such as reducing pollution, energy consumption, and urban congestion. However, orchestrating these systems at scale remains a critical challenge, with existing coordination algorithms often failing to exploit the systems' full potential. This work introduces a novel decision-making framework that unites mathematical modeling with data-driven techniques. In particular, we present the AMoD coordination problem through the lens of reinforcement learning and propose a graph network-based framework that exploits the main strengths of graph representation learning, reinforcement learning, and classical operations research tools. Extensive evaluations across diverse simulation fidelities and scenarios demonstrate the flexibility of our approach, achieving superior system performance, computational efficiency, and generalizability compared to prior methods. Finally, motivated by the need to democratize research efforts in this area, we release publicly available benchmarks, datasets, and simulators for network-level coordination alongside an open-source codebase designed to provide accessible simulation platforms and establish a standardized validation process for comparing methodologies. Code available at: https://github.com/StanfordASL/RL4AMOD
Transformer-based Model Predictive Control: Trajectory Optimization via Sequence Modeling
Oct 31, 2024



Model predictive control (MPC) has established itself as the primary methodology for constrained control, enabling general-purpose robot autonomy in diverse real-world scenarios. However, for most problems of interest, MPC relies on the recursive solution of highly non-convex trajectory optimization problems, leading to high computational complexity and strong dependency on initialization. In this work, we present a unified framework to combine the main strengths of optimization-based and learning-based methods for MPC. Our approach entails embedding high-capacity, transformer-based neural network models within the optimization process for trajectory generation, whereby the transformer provides a near-optimal initial guess, or target plan, to a non-convex optimization problem. Our experiments, performed in simulation and the real world onboard a free flyer platform, demonstrate the capabilities of our framework to improve MPC convergence and runtime. Compared to purely optimization-based approaches, results show that our approach can improve trajectory generation performance by up to 75%, reduce the number of solver iterations by up to 45%, and improve overall MPC runtime by 7x without loss in performance.
* 8 pages, 7 figures. Datasets, videos and code available at: https://transformermpc.github.io
Generalizable Spacecraft Trajectory Generation via Multimodal Learning with Transformers
Oct 15, 2024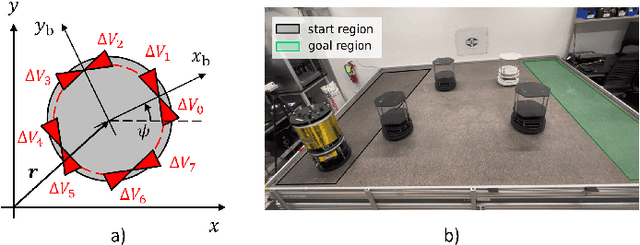
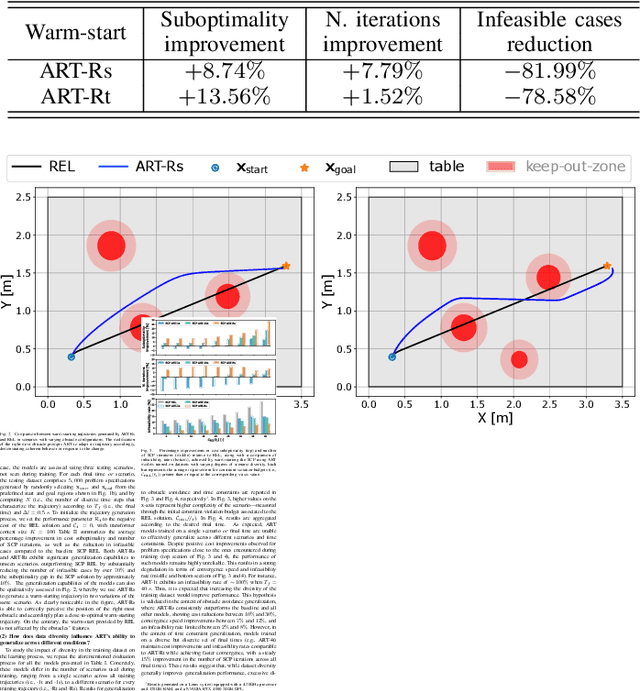
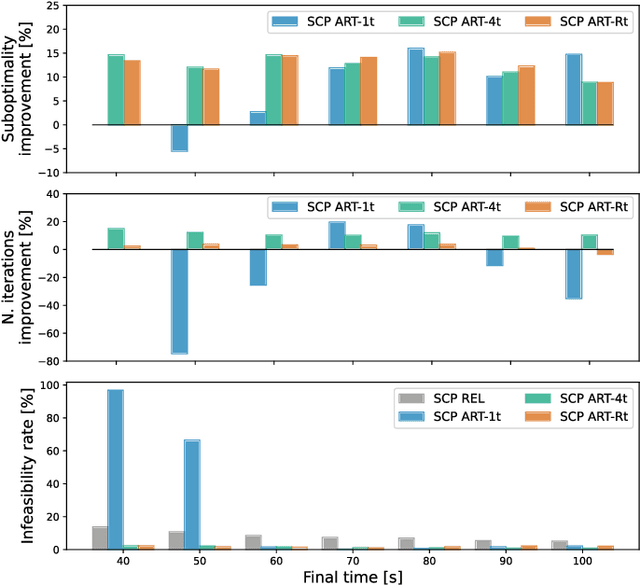
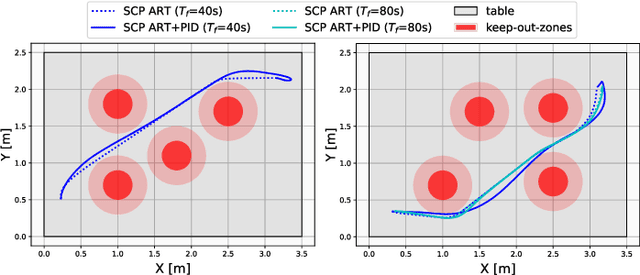
Effective trajectory generation is essential for reliable on-board spacecraft autonomy. Among other approaches, learning-based warm-starting represents an appealing paradigm for solving the trajectory generation problem, effectively combining the benefits of optimization- and data-driven methods. Current approaches for learning-based trajectory generation often focus on fixed, single-scenario environments, where key scene characteristics, such as obstacle positions or final-time requirements, remain constant across problem instances. However, practical trajectory generation requires the scenario to be frequently reconfigured, making the single-scenario approach a potentially impractical solution. To address this challenge, we present a novel trajectory generation framework that generalizes across diverse problem configurations, by leveraging high-capacity transformer neural networks capable of learning from multimodal data sources. Specifically, our approach integrates transformer-based neural network models into the trajectory optimization process, encoding both scene-level information (e.g., obstacle locations, initial and goal states) and trajectory-level constraints (e.g., time bounds, fuel consumption targets) via multimodal representations. The transformer network then generates near-optimal initial guesses for non-convex optimization problems, significantly enhancing convergence speed and performance. The framework is validated through extensive simulations and real-world experiments on a free-flyer platform, achieving up to 30% cost improvement and 80% reduction in infeasible cases with respect to traditional approaches, and demonstrating robust generalization across diverse scenario variations.
Offline Hierarchical Reinforcement Learning via Inverse Optimization
Oct 10, 2024



Hierarchical policies enable strong performance in many sequential decision-making problems, such as those with high-dimensional action spaces, those requiring long-horizon planning, and settings with sparse rewards. However, learning hierarchical policies from static offline datasets presents a significant challenge. Crucially, actions taken by higher-level policies may not be directly observable within hierarchical controllers, and the offline dataset might have been generated using a different policy structure, hindering the use of standard offline learning algorithms. In this work, we propose OHIO: a framework for offline reinforcement learning (RL) of hierarchical policies. Our framework leverages knowledge of the policy structure to solve the inverse problem, recovering the unobservable high-level actions that likely generated the observed data under our hierarchical policy. This approach constructs a dataset suitable for off-the-shelf offline training. We demonstrate our framework on robotic and network optimization problems and show that it substantially outperforms end-to-end RL methods and improves robustness. We investigate a variety of instantiations of our framework, both in direct deployment of policies trained offline and when online fine-tuning is performed.
Towards Robust Spacecraft Trajectory Optimization via Transformers
Oct 08, 2024Future multi-spacecraft missions require robust autonomous trajectory optimization capabilities to ensure safe and efficient rendezvous operations. This capability hinges on solving non-convex optimal control problems in real time, although traditional iterative methods such as sequential convex programming impose significant computational challenges. To mitigate this burden, the Autonomous Rendezvous Transformer introduced a generative model trained to provide near-optimal initial guesses. This approach provides convergence to better local optima (e.g., fuel optimality), improves feasibility rates, and results in faster convergence speed of optimization algorithms through warm-starting. This work extends the capabilities of ART to address robust chance-constrained optimal control problems. Specifically, ART is applied to challenging rendezvous scenarios in Low Earth Orbit (LEO), ensuring fault-tolerant behavior under uncertainty. Through extensive experimentation, the proposed warm-starting strategy is shown to consistently produce high-quality reference trajectories, achieving up to 30% cost improvement and 50% reduction in infeasible cases compared to conventional methods, demonstrating robust performance across multiple state representations. Additionally, a post hoc evaluation framework is proposed to assess the quality of generated trajectories and mitigate runtime failures, marking an initial step toward the reliable deployment of AI-driven solutions in safety-critical autonomous systems such as spacecraft.