 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeployment-Time Reliability of Learned Robot Policies
Mar 12, 2026Recent advances in learning-based robot manipulation have produced policies with remarkable capabilities. Yet, reliability at deployment remains a fundamental barrier to real-world use, where distribution shift, compounding errors, and complex task dependencies collectively undermine system performance. This dissertation investigates how the reliability of learned robot policies can be improved at deployment time through mechanisms that operate around them. We develop three complementary classes of deployment-time mechanisms. First, we introduce runtime monitoring methods that detect impending failures by identifying inconsistencies in closed-loop policy behavior and deviations in task progress, without requiring failure data or task-specific supervision. Second, we propose a data-centric framework for policy interpretability that traces deployment-time successes and failures to influential training demonstrations using influence functions, enabling principled diagnosis and dataset curation. Third, we address reliable long-horizon task execution by formulating policy coordination as the problem of estimating and maximizing the success probability of behavior sequences, and we extend this formulation to open-ended, language-specified tasks through feasibility-aware task planning. By centering on core challenges of deployment, these contributions advance practical foundations for the reliable, real-world use of learned robot policies. Continued progress on these foundations will be essential for enabling trustworthy and scalable robot autonomy in the future.
Diversity You Can Actually Measure: A Fast, Model-Free Diversity Metric for Robotics Datasets
Mar 12, 2026Robotics datasets for imitation learning typically consist of long-horizon trajectories of different lengths over states, actions, and high-dimensional observations (e.g., RGB video), making it non-trivial to quantify diversity in a way that respects the underlying trajectory structure and geometry. We extend Shannon and von Neumann entropy to this setting by defining signature transform-based entropy on the Gram matrix of a signature kernel over demonstrations, yielding entropy and diversity metrics that operate directly on the demonstration dataset. Building on these metrics, we study how dataset diversity affects generalization performance in robot imitation learning and propose a simple, model-free way to curate diverse demonstrations. We introduce FAKTUAL (FAst trajectory Kernel enTropy cUration for imitation Learning), a data curation algorithm that selects a subset of demonstrations maximizing entropy given a subset-size budget. FAKTUAL is fully model-free, requires no access to the imitation policy or rollouts, and adds negligible overhead relative to policy training. We evaluate our approach on image and state-based RoboMimic and MetaWorld benchmarks, as well as four real-world manipulation tasks. Across tasks and architectures, diversity-aware curation with FAKTUAL consistently improves downstream success rates over random selection, while being substantially more computationally efficient compared to recent robot data curation methods. Our results suggest that the entropy of demonstration datasets is a practical tool for understanding and improving dataset diversity in robot imitation learning.
CUPID: Curating Data your Robot Loves with Influence Functions
Jun 23, 2025
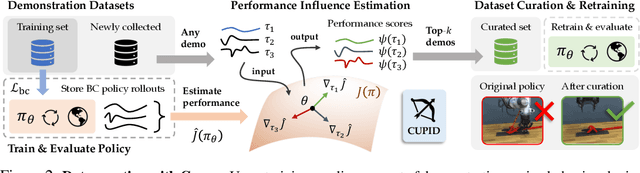
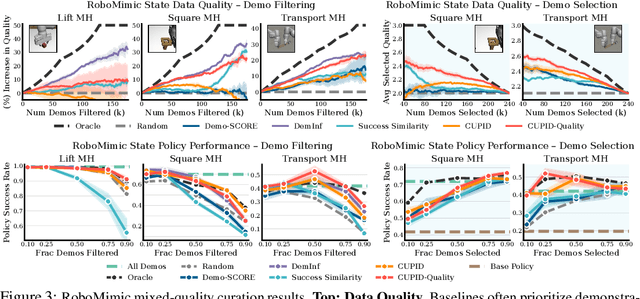
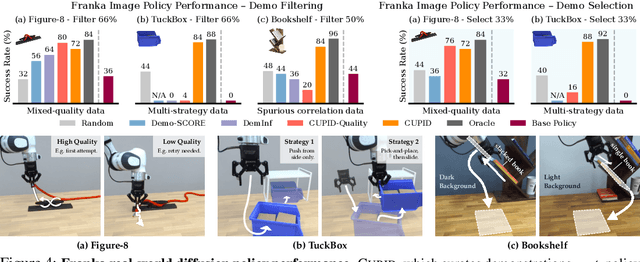
In robot imitation learning, policy performance is tightly coupled with the quality and composition of the demonstration data. Yet, developing a precise understanding of how individual demonstrations contribute to downstream outcomes - such as closed-loop task success or failure - remains a persistent challenge. We propose CUPID, a robot data curation method based on a novel influence function-theoretic formulation for imitation learning policies. Given a set of evaluation rollouts, CUPID estimates the influence of each training demonstration on the policy's expected return. This enables ranking and selection of demonstrations according to their impact on the policy's closed-loop performance. We use CUPID to curate data by 1) filtering out training demonstrations that harm policy performance and 2) subselecting newly collected trajectories that will most improve the policy. Extensive simulated and hardware experiments show that our approach consistently identifies which data drives test-time performance. For example, training with less than 33% of curated data can yield state-of-the-art diffusion policies on the simulated RoboMimic benchmark, with similar gains observed in hardware. Furthermore, hardware experiments show that our method can identify robust strategies under distribution shift, isolate spurious correlations, and even enhance the post-training of generalist robot policies. Additional materials are made available at: https://cupid-curation.github.io.
Real-Time Out-of-Distribution Failure Prevention via Multi-Modal Reasoning
May 15, 2025



Foundation models can provide robust high-level reasoning on appropriate safety interventions in hazardous scenarios beyond a robot's training data, i.e. out-of-distribution (OOD) failures. However, due to the high inference latency of Large Vision and Language Models, current methods rely on manually defined intervention policies to enact fallbacks, thereby lacking the ability to plan generalizable, semantically safe motions. To overcome these challenges we present FORTRESS, a framework that generates and reasons about semantically safe fallback strategies in real time to prevent OOD failures. At a low frequency in nominal operations, FORTRESS uses multi-modal reasoners to identify goals and anticipate failure modes. When a runtime monitor triggers a fallback response, FORTRESS rapidly synthesizes plans to fallback goals while inferring and avoiding semantically unsafe regions in real time. By bridging open-world, multi-modal reasoning with dynamics-aware planning, we eliminate the need for hard-coded fallbacks and human safety interventions. FORTRESS outperforms on-the-fly prompting of slow reasoning models in safety classification accuracy on synthetic benchmarks and real-world ANYmal robot data, and further improves system safety and planning success in simulation and on quadrotor hardware for urban navigation.
Unpacking Failure Modes of Generative Policies: Runtime Monitoring of Consistency and Progress
Oct 06, 2024
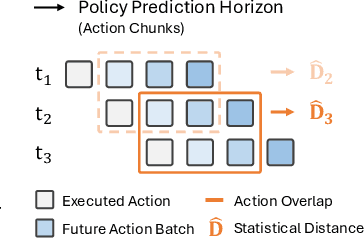

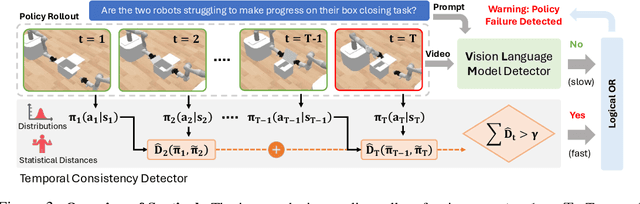
Robot behavior policies trained via imitation learning are prone to failure under conditions that deviate from their training data. Thus, algorithms that monitor learned policies at test time and provide early warnings of failure are necessary to facilitate scalable deployment. We propose Sentinel, a runtime monitoring framework that splits the detection of failures into two complementary categories: 1) Erratic failures, which we detect using statistical measures of temporal action consistency, and 2) task progression failures, where we use Vision Language Models (VLMs) to detect when the policy confidently and consistently takes actions that do not solve the task. Our approach has two key strengths. First, because learned policies exhibit diverse failure modes, combining complementary detectors leads to significantly higher accuracy at failure detection. Second, using a statistical temporal action consistency measure ensures that we quickly detect when multimodal, generative policies exhibit erratic behavior at negligible computational cost. In contrast, we only use VLMs to detect failure modes that are less time-sensitive. We demonstrate our approach in the context of diffusion policies trained on robotic mobile manipulation domains in both simulation and the real world. By unifying temporal consistency detection and VLM runtime monitoring, Sentinel detects 18% more failures than using either of the two detectors alone and significantly outperforms baselines, thus highlighting the importance of assigning specialized detectors to complementary categories of failure. Qualitative results are made available at https://sites.google.com/stanford.edu/sentinel.
RoboMorph: In-Context Meta-Learning for Robot Dynamics Modeling
Sep 18, 2024



The landscape of Deep Learning has experienced a major shift with the pervasive adoption of Transformer-based architectures, particularly in Natural Language Processing (NLP). Novel avenues for physical applications, such as solving Partial Differential Equations and Image Vision, have been explored. However, in challenging domains like robotics, where high non-linearity poses significant challenges, Transformer-based applications are scarce. While Transformers have been used to provide robots with knowledge about high-level tasks, few efforts have been made to perform system identification. This paper proposes a novel methodology to learn a meta-dynamical model of a high-dimensional physical system, such as the Franka robotic arm, using a Transformer-based architecture without prior knowledge of the system's physical parameters. The objective is to predict quantities of interest (end-effector pose and joint positions) given the torque signals for each joint. This prediction can be useful as a component for Deep Model Predictive Control frameworks in robotics. The meta-model establishes the correlation between torques and positions and predicts the output for the complete trajectory. This work provides empirical evidence of the efficacy of the in-context learning paradigm, suggesting future improvements in learning the dynamics of robotic systems without explicit knowledge of physical parameters. Code, videos, and supplementary materials can be found at project website. See https://sites.google.com/view/robomorph/
Points2Plans: From Point Clouds to Long-Horizon Plans with Composable Relational Dynamics
Aug 27, 2024We present Points2Plans, a framework for composable planning with a relational dynamics model that enables robots to solve long-horizon manipulation tasks from partial-view point clouds. Given a language instruction and a point cloud of the scene, our framework initiates a hierarchical planning procedure, whereby a language model generates a high-level plan and a sampling-based planner produces constraint-satisfying continuous parameters for manipulation primitives sequenced according to the high-level plan. Key to our approach is the use of a relational dynamics model as a unifying interface between the continuous and symbolic representations of states and actions, thus facilitating language-driven planning from high-dimensional perceptual input such as point clouds. Whereas previous relational dynamics models require training on datasets of multi-step manipulation scenarios that align with the intended test scenarios, Points2Plans uses only single-step simulated training data while generalizing zero-shot to a variable number of steps during real-world evaluations. We evaluate our approach on tasks involving geometric reasoning, multi-object interactions, and occluded object reasoning in both simulated and real-world settings. Results demonstrate that Points2Plans offers strong generalization to unseen long-horizon tasks in the real world, where it solves over 85% of evaluated tasks while the next best baseline solves only 50%. Qualitative demonstrations of our approach operating on a mobile manipulator platform are made available at sites.google.com/stanford.edu/points2plans.
Adapting a Foundation Model for Space-based Tasks
Aug 12, 2024



Foundation models, e.g., large language models, possess attributes of intelligence which offer promise to endow a robot with the contextual understanding necessary to navigate complex, unstructured tasks in the wild. In the future of space robotics, we see three core challenges which motivate the use of a foundation model adapted to space-based applications: 1) Scalability of ground-in-the-loop operations; 2) Generalizing prior knowledge to novel environments; and 3) Multi-modality in tasks and sensor data. Therefore, as a first-step towards building a foundation model for space-based applications, we automatically label the AI4Mars dataset to curate a language annotated dataset of visual-question-answer tuples. We fine-tune a pretrained LLaVA checkpoint on this dataset to endow a vision-language model with the ability to perform spatial reasoning and navigation on Mars' surface. In this work, we demonstrate that 1) existing vision-language models are deficient visual reasoners in space-based applications, and 2) fine-tuning a vision-language model on extraterrestrial data significantly improves the quality of responses even with a limited training dataset of only a few thousand samples.
Text2Interaction: Establishing Safe and Preferable Human-Robot Interaction
Aug 12, 2024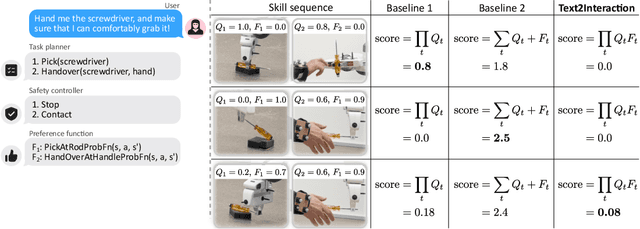

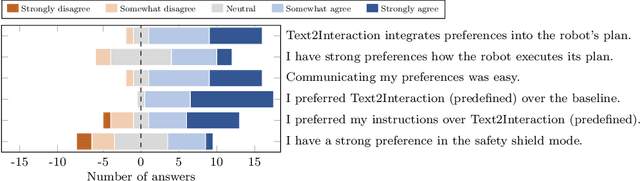
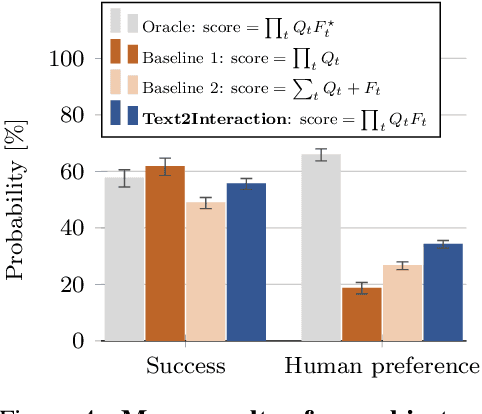
Adjusting robot behavior to human preferences can require intensive human feedback, preventing quick adaptation to new users and changing circumstances. Moreover, current approaches typically treat user preferences as a reward, which requires a manual balance between task success and user satisfaction. To integrate new user preferences in a zero-shot manner, our proposed Text2Interaction framework invokes large language models to generate a task plan, motion preferences as Python code, and parameters of a safe controller. By maximizing the combined probability of task completion and user satisfaction instead of a weighted sum of rewards, we can reliably find plans that fulfill both requirements. We find that 83% of users working with Text2Interaction agree that it integrates their preferences into the robot's plan, and 94% prefer Text2Interaction over the baseline. Our ablation study shows that Text2Interaction aligns better with unseen preferences than other baselines while maintaining a high success rate.
Real-Time Anomaly Detection and Reactive Planning with Large Language Models
Jul 11, 2024



Foundation models, e.g., large language models (LLMs), trained on internet-scale data possess zero-shot generalization capabilities that make them a promising technology towards detecting and mitigating out-of-distribution failure modes of robotic systems. Fully realizing this promise, however, poses two challenges: (i) mitigating the considerable computational expense of these models such that they may be applied online, and (ii) incorporating their judgement regarding potential anomalies into a safe control framework. In this work, we present a two-stage reasoning framework: First is a fast binary anomaly classifier that analyzes observations in an LLM embedding space, which may then trigger a slower fallback selection stage that utilizes the reasoning capabilities of generative LLMs. These stages correspond to branch points in a model predictive control strategy that maintains the joint feasibility of continuing along various fallback plans to account for the slow reasoner's latency as soon as an anomaly is detected, thus ensuring safety. We show that our fast anomaly classifier outperforms autoregressive reasoning with state-of-the-art GPT models, even when instantiated with relatively small language models. This enables our runtime monitor to improve the trustworthiness of dynamic robotic systems, such as quadrotors or autonomous vehicles, under resource and time constraints. Videos illustrating our approach in both simulation and real-world experiments are available on this project page: https://sites.google.com/view/aesop-llm.