 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Demonstrations to Safe Deployment: Path-Consistent Safety Filtering for Diffusion Policies
Nov 09, 2025Diffusion policies (DPs) achieve state-of-the-art performance on complex manipulation tasks by learning from large-scale demonstration datasets, often spanning multiple embodiments and environments. However, they cannot guarantee safe behavior, so external safety mechanisms are needed. These, however, alter actions in ways unseen during training, causing unpredictable behavior and performance degradation. To address these problems, we propose path-consistent safety filtering (PACS) for DPs. Our approach performs path-consistent braking on a trajectory computed from the sequence of generated actions. In this way, we keep execution consistent with the policy's training distribution, maintaining the learned, task-completing behavior. To enable a real-time deployment and handle uncertainties, we verify safety using set-based reachability analysis. Our experimental evaluation in simulation and on three challenging real-world human-robot interaction tasks shows that PACS (a) provides formal safety guarantees in dynamic environments, (b) preserves task success rates, and (c) outperforms reactive safety approaches, such as control barrier functions, by up to 68% in terms of task success. Videos are available at our project website: https://tum-lsy.github.io/pacs/.
Multi-Objective Causal Bayesian Optimization
Feb 20, 2025In decision-making problems, the outcome of an intervention often depends on the causal relationships between system components and is highly costly to evaluate. In such settings, causal Bayesian optimization (CBO) can exploit the causal relationships between the system variables and sequentially perform interventions to approach the optimum with minimal data. Extending CBO to the multi-outcome setting, we propose Multi-Objective Causal Bayesian Optimization (MO-CBO), a paradigm for identifying Pareto-optimal interventions within a known multi-target causal graph. We first derive a graphical characterization for potentially optimal sets of variables to intervene upon. Showing that any MO-CBO problem can be decomposed into several traditional multi-objective optimization tasks, we then introduce an algorithm that sequentially balances exploration across these tasks using relative hypervolume improvement. The proposed method will be validated on both synthetic and real-world causal graphs, demonstrating its superiority over traditional (non-causal) multi-objective Bayesian optimization in settings where causal information is available.
A General Safety Framework for Autonomous Manipulation in Human Environments
Dec 13, 2024



Autonomous robots are projected to augment the manual workforce, especially in repetitive and hazardous tasks. For a successful deployment of such robots in human environments, it is crucial to guarantee human safety. State-of-the-art approaches to ensure human safety are either too restrictive to permit a natural human-robot collaboration or make strong assumptions that do not hold when for autonomous robots, e.g., knowledge of a pre-defined trajectory. Therefore, we propose SaRA-shield, a power and force limiting framework for AI-based manipulation in human environments that gives formal safety guarantees while allowing for fast robot speeds. As recent studies have shown that unconstrained collisions allow for significantly higher contact forces than constrained collisions (clamping), we propose to classify contacts by their collision type using reachability analysis. We then verify that the kinetic energy of the robot is below pain and injury thresholds for the detected collision type of the respective human body part in contact. Our real-world experiments show that SaRA-shield can effectively reduce the speed of the robot to adhere to injury-preventing energy limits.
Text2Interaction: Establishing Safe and Preferable Human-Robot Interaction
Aug 12, 2024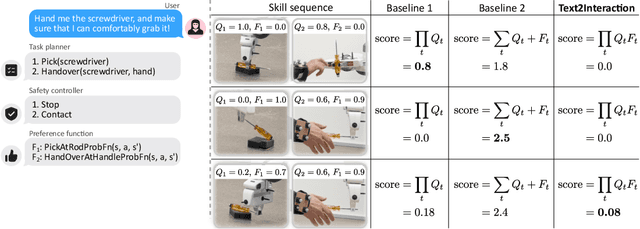

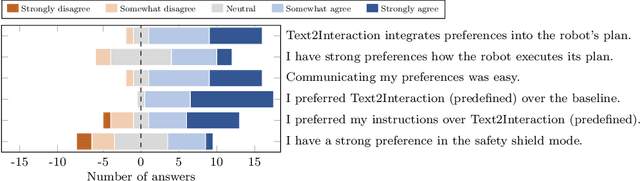
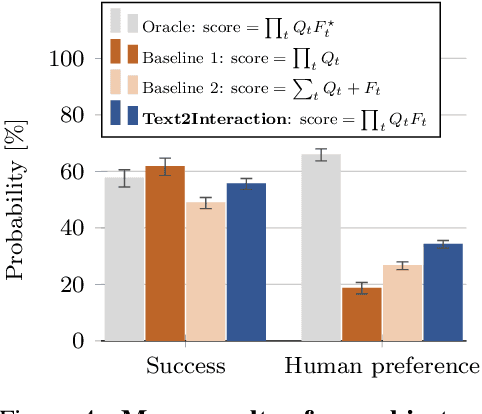
Adjusting robot behavior to human preferences can require intensive human feedback, preventing quick adaptation to new users and changing circumstances. Moreover, current approaches typically treat user preferences as a reward, which requires a manual balance between task success and user satisfaction. To integrate new user preferences in a zero-shot manner, our proposed Text2Interaction framework invokes large language models to generate a task plan, motion preferences as Python code, and parameters of a safe controller. By maximizing the combined probability of task completion and user satisfaction instead of a weighted sum of rewards, we can reliably find plans that fulfill both requirements. We find that 83% of users working with Text2Interaction agree that it integrates their preferences into the robot's plan, and 94% prefer Text2Interaction over the baseline. Our ablation study shows that Text2Interaction aligns better with unseen preferences than other baselines while maintaining a high success rate.
Excluding the Irrelevant: Focusing Reinforcement Learning through Continuous Action Masking
Jun 06, 2024



Continuous action spaces in reinforcement learning (RL) are commonly defined as interval sets. While intervals usually reflect the action boundaries for tasks well, they can be challenging for learning because the typically large global action space leads to frequent exploration of irrelevant actions. Yet, little task knowledge can be sufficient to identify significantly smaller state-specific sets of relevant actions. Focusing learning on these relevant actions can significantly improve training efficiency and effectiveness. In this paper, we propose to focus learning on the set of relevant actions and introduce three continuous action masking methods for exactly mapping the action space to the state-dependent set of relevant actions. Thus, our methods ensure that only relevant actions are executed, enhancing the predictability of the RL agent and enabling its use in safety-critical applications. We further derive the implications of the proposed methods on the policy gradient. Using Proximal Policy Optimization (PPO), we evaluate our methods on three control tasks, where the relevant action set is computed based on the system dynamics and a relevant state set. Our experiments show that the three action masking methods achieve higher final rewards and converge faster than the baseline without action masking.
Human-Robot Gym: Benchmarking Reinforcement Learning in Human-Robot Collaboration
Oct 09, 2023



Deep reinforcement learning (RL) has shown promising results in robot motion planning with first attempts in human-robot collaboration (HRC). However, a fair comparison of RL approaches in HRC under the constraint of guaranteed safety is yet to be made. We, therefore, present human-robot gym, a benchmark for safe RL in HRC. Our benchmark provides eight challenging, realistic HRC tasks in a modular simulation framework. Most importantly, human-robot gym includes a safety shield that provably guarantees human safety. We are, thereby, the first to provide a benchmark to train RL agents that adhere to the safety specifications of real-world HRC. This bridges a critical gap between theoretic RL research and its real-world deployment. Our evaluation of six environments led to three key results: (a) the diverse nature of the tasks offered by human-robot gym creates a challenging benchmark for state-of-the-art RL methods, (b) incorporating expert knowledge in the RL training in the form of an action-based reward can outperform the expert, and (c) our agents negligibly overfit to training data.
Reducing Safety Interventions in Provably Safe Reinforcement Learning
Mar 06, 2023Deep Reinforcement Learning (RL) has shown promise in addressing complex robotic challenges. In real-world applications, RL is often accompanied by failsafe controllers as a last resort to avoid catastrophic events. While necessary for safety, these interventions can result in undesirable behaviors, such as abrupt braking or aggressive steering. This paper proposes two safety intervention reduction methods: action replacement and projection, which change the agent's action if it leads to an unsafe state. These approaches are compared to the state-of-the-art constrained RL on the OpenAI safety gym benchmark and a human-robot collaboration task. Our study demonstrates that the combination of our method with provably safe RL leads to high-performing policies with zero safety violations and a low number of failsafe interventions. Our versatile method can be applied to a wide range of real-world robotics tasks, while effectively improving safety without sacrificing task performance.
Provably Safe Reinforcement Learning: A Theoretical and Experimental Comparison
May 13, 2022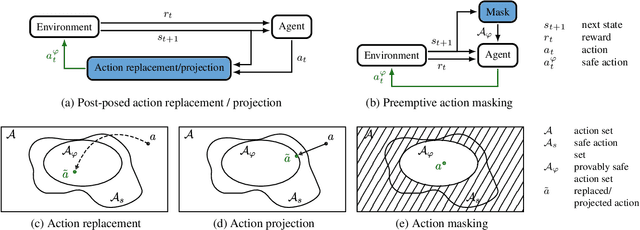
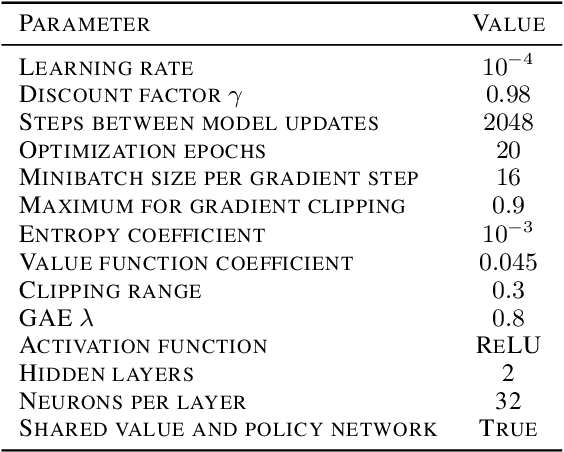
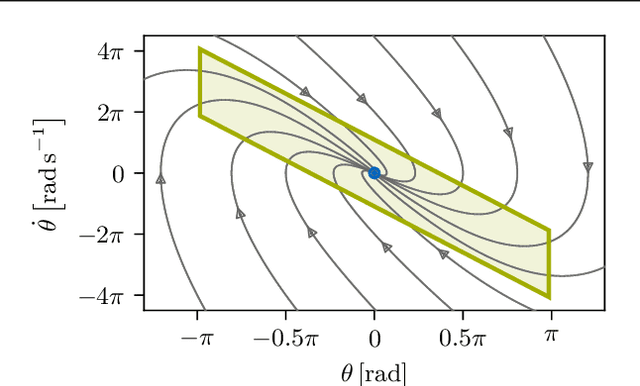

Ensuring safety of reinforcement learning (RL) algorithms is crucial for many real-world tasks. However, vanilla RL does not guarantee safety for an agent. In recent years, several methods have been proposed to provide safety guarantees for RL. To the best of our knowledge, there is no comprehensive comparison of these provably safe RL methods. We therefore introduce a categorization for existing provably safe RL methods, and present the theoretical foundations for both continuous and discrete action spaces. Additionally, we evaluate provably safe RL on an inverted pendulum. In the experiments, it is shown that indeed only provably safe RL methods guarantee safety.
Provably Safe Deep Reinforcement Learning for Robotic Manipulation in Human Environments
May 12, 2022



Deep reinforcement learning (RL) has shown promising results in the motion planning of manipulators. However, no method guarantees the safety of highly dynamic obstacles, such as humans, in RL-based manipulator control. This lack of formal safety assurances prevents the application of RL for manipulators in real-world human environments. Therefore, we propose a shielding mechanism that ensures ISO-verified human safety while training and deploying RL algorithms on manipulators. We utilize a fast reachability analysis of humans and manipulators to guarantee that the manipulator comes to a complete stop before a human is within its range. Our proposed method guarantees safety and significantly improves the RL performance by preventing episode-ending collisions. We demonstrate the performance of our proposed method in simulation using human motion capture data.