 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Interaction: Establishing Safe and Preferable Human-Robot Interaction
Paper and Code
Aug 12, 2024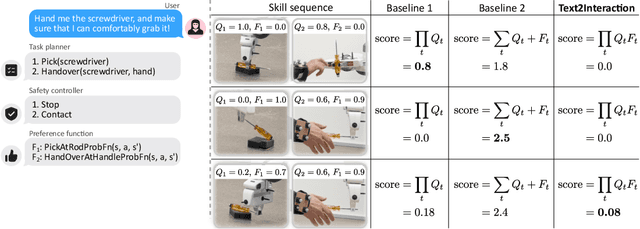

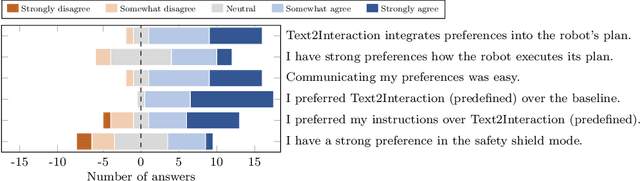
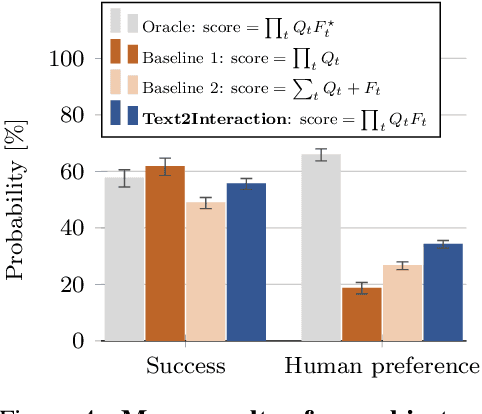
Adjusting robot behavior to human preferences can require intensive human feedback, preventing quick adaptation to new users and changing circumstances. Moreover, current approaches typically treat user preferences as a reward, which requires a manual balance between task success and user satisfaction. To integrate new user preferences in a zero-shot manner, our proposed Text2Interaction framework invokes large language models to generate a task plan, motion preferences as Python code, and parameters of a safe controller. By maximizing the combined probability of task completion and user satisfaction instead of a weighted sum of rewards, we can reliably find plans that fulfill both requirements. We find that 83% of users working with Text2Interaction agree that it integrates their preferences into the robot's plan, and 94% prefer Text2Interaction over the baseline. Our ablation study shows that Text2Interaction aligns better with unseen preferences than other baselines while maintaining a high success rate.