 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalsification-Driven Reinforcement Learning for Maritime Motion Planning
Oct 08, 2025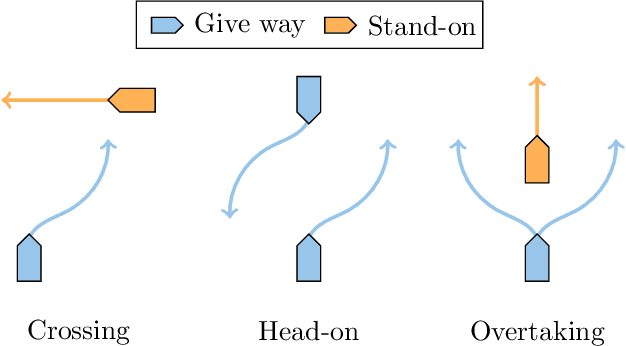



Compliance with maritime traffic rules is essential for the safe operation of autonomous vessels, yet training reinforcement learning (RL) agents to adhere to them is challenging. The behavior of RL agents is shaped by the training scenarios they encounter, but creating scenarios that capture the complexity of maritime navigation is non-trivial, and real-world data alone is insufficient. To address this, we propose a falsification-driven RL approach that generates adversarial training scenarios in which the vessel under test violates maritime traffic rules, which are expressed as signal temporal logic specifications. Our experiments on open-sea navigation with two vessels demonstrate that the proposed approach provides more relevant training scenarios and achieves more consistent rule compliance.
Provably Safe Reinforcement Learning: A Theoretical and Experimental Comparison
May 13, 2022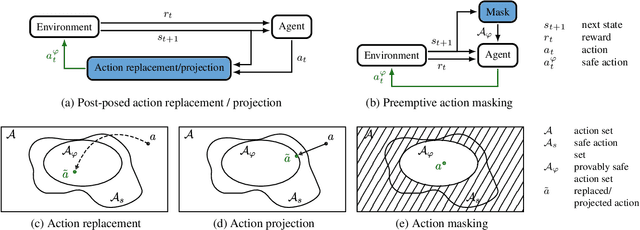
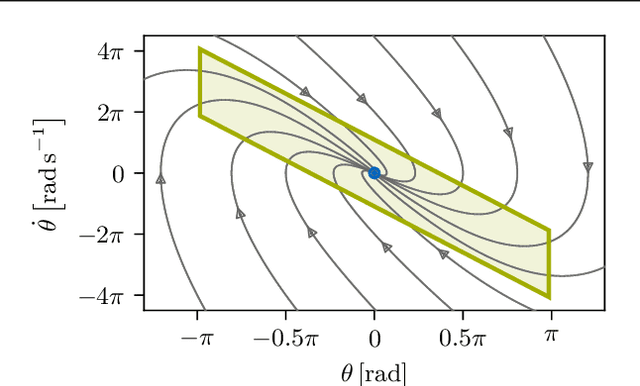

Ensuring safety of reinforcement learning (RL) algorithms is crucial for many real-world tasks. However, vanilla RL does not guarantee safety for an agent. In recent years, several methods have been proposed to provide safety guarantees for RL. To the best of our knowledge, there is no comprehensive comparison of these provably safe RL methods. We therefore introduce a categorization for existing provably safe RL methods, and present the theoretical foundations for both continuous and discrete action spaces. Additionally, we evaluate provably safe RL on an inverted pendulum. In the experiments, it is shown that indeed only provably safe RL methods guarantee safety.