 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUPID: Curating Data your Robot Loves with Influence Functions
Jun 23, 2025
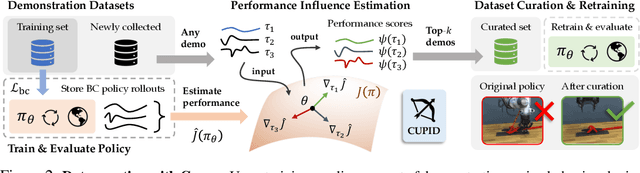
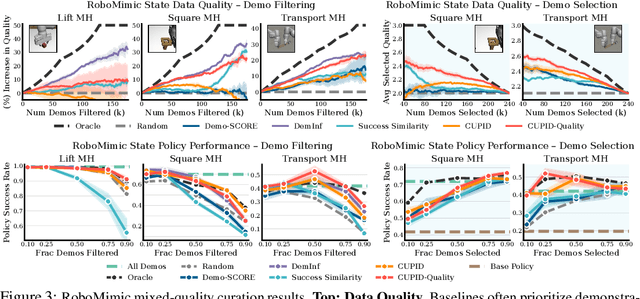
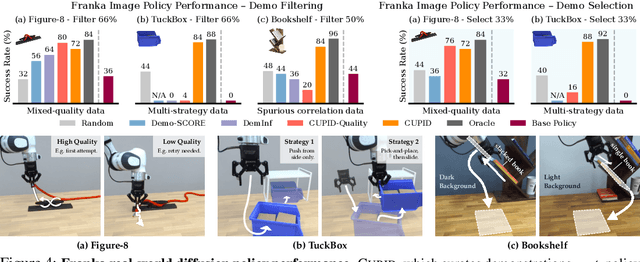
In robot imitation learning, policy performance is tightly coupled with the quality and composition of the demonstration data. Yet, developing a precise understanding of how individual demonstrations contribute to downstream outcomes - such as closed-loop task success or failure - remains a persistent challenge. We propose CUPID, a robot data curation method based on a novel influence function-theoretic formulation for imitation learning policies. Given a set of evaluation rollouts, CUPID estimates the influence of each training demonstration on the policy's expected return. This enables ranking and selection of demonstrations according to their impact on the policy's closed-loop performance. We use CUPID to curate data by 1) filtering out training demonstrations that harm policy performance and 2) subselecting newly collected trajectories that will most improve the policy. Extensive simulated and hardware experiments show that our approach consistently identifies which data drives test-time performance. For example, training with less than 33% of curated data can yield state-of-the-art diffusion policies on the simulated RoboMimic benchmark, with similar gains observed in hardware. Furthermore, hardware experiments show that our method can identify robust strategies under distribution shift, isolate spurious correlations, and even enhance the post-training of generalist robot policies. Additional materials are made available at: https://cupid-curation.github.io.
Mobi-$π$: Mobilizing Your Robot Learning Policy
May 29, 2025Learned visuomotor policies are capable of performing increasingly complex manipulation tasks. However, most of these policies are trained on data collected from limited robot positions and camera viewpoints. This leads to poor generalization to novel robot positions, which limits the use of these policies on mobile platforms, especially for precise tasks like pressing buttons or turning faucets. In this work, we formulate the policy mobilization problem: find a mobile robot base pose in a novel environment that is in distribution with respect to a manipulation policy trained on a limited set of camera viewpoints. Compared to retraining the policy itself to be more robust to unseen robot base pose initializations, policy mobilization decouples navigation from manipulation and thus does not require additional demonstrations. Crucially, this problem formulation complements existing efforts to improve manipulation policy robustness to novel viewpoints and remains compatible with them. To study policy mobilization, we introduce the Mobi-$\pi$ framework, which includes: (1) metrics that quantify the difficulty of mobilizing a given policy, (2) a suite of simulated mobile manipulation tasks based on RoboCasa to evaluate policy mobilization, (3) visualization tools for analysis, and (4) several baseline methods. We also propose a novel approach that bridges navigation and manipulation by optimizing the robot's base pose to align with an in-distribution base pose for a learned policy. Our approach utilizes 3D Gaussian Splatting for novel view synthesis, a score function to evaluate pose suitability, and sampling-based optimization to identify optimal robot poses. We show that our approach outperforms baselines in both simulation and real-world environments, demonstrating its effectiveness for policy mobilization.
Hierarchical Feature Learning for Medical Point Clouds via State Space Model
Apr 17, 2025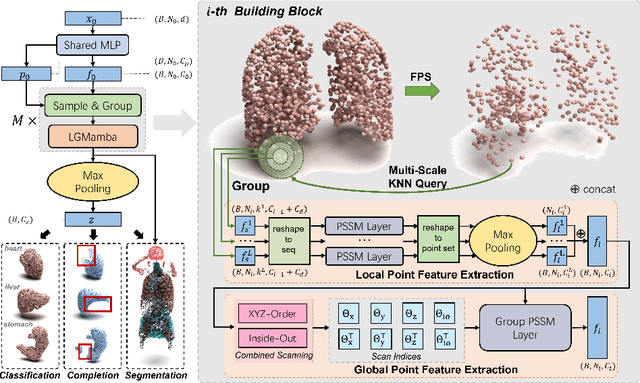



Deep learning-based point cloud modeling has been widely investigated as an indispensable component of general shape analysis. Recently, transformer and state space model (SSM) have shown promising capacities in point cloud learning. However, limited research has been conducted on medical point clouds, which have great potential in disease diagnosis and treatment. This paper presents an SSM-based hierarchical feature learning framework for medical point cloud understanding. Specifically, we down-sample input into multiple levels through the farthest point sampling. At each level, we perform a series of k-nearest neighbor (KNN) queries to aggregate multi-scale structural information. To assist SSM in processing point clouds, we introduce coordinate-order and inside-out scanning strategies for efficient serialization of irregular points. Point features are calculated progressively from short neighbor sequences and long point sequences through vanilla and group Point SSM blocks, to capture both local patterns and long-range dependencies. To evaluate the proposed method, we build a large-scale medical point cloud dataset named MedPointS for anatomy classification, completion, and segmentation. Extensive experiments conducted on MedPointS demonstrate that our method achieves superior performance across all tasks. The dataset is available at https://flemme-docs.readthedocs.io/en/latest/medpoints.html. Code is merged to a public medical imaging platform: https://github.com/wlsdzyzl/flemme.
Zero-shot Autonomous Microscopy for Scalable and Intelligent Characterization of 2D Materials
Apr 14, 2025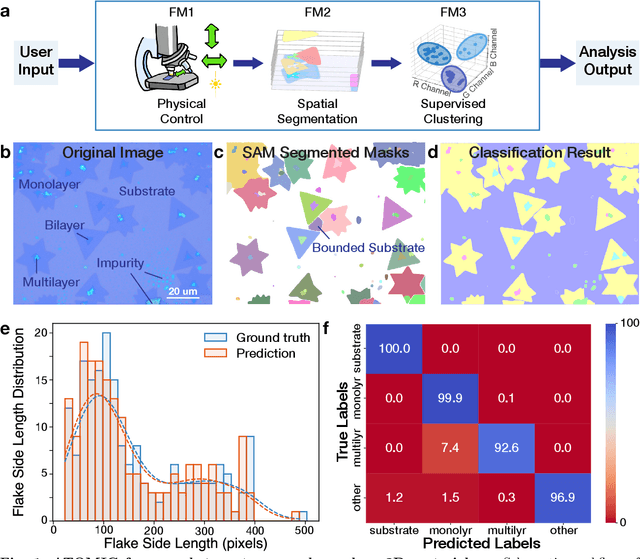
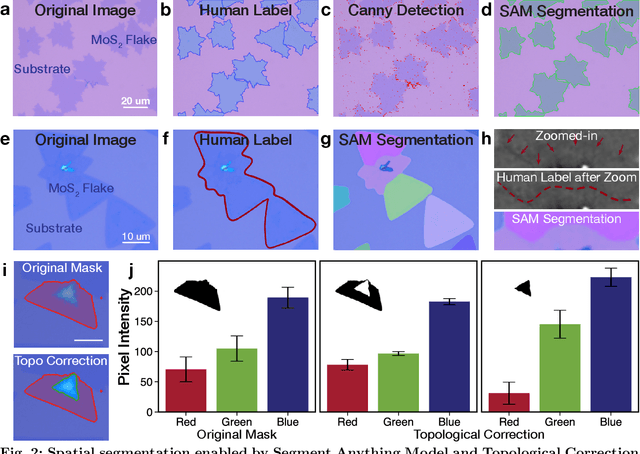
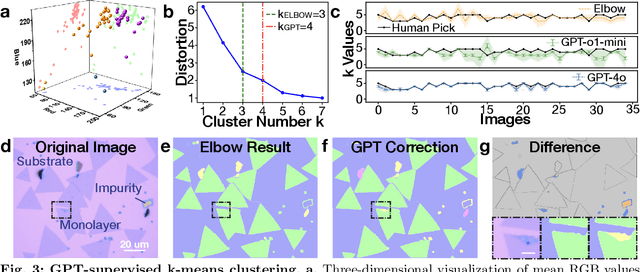
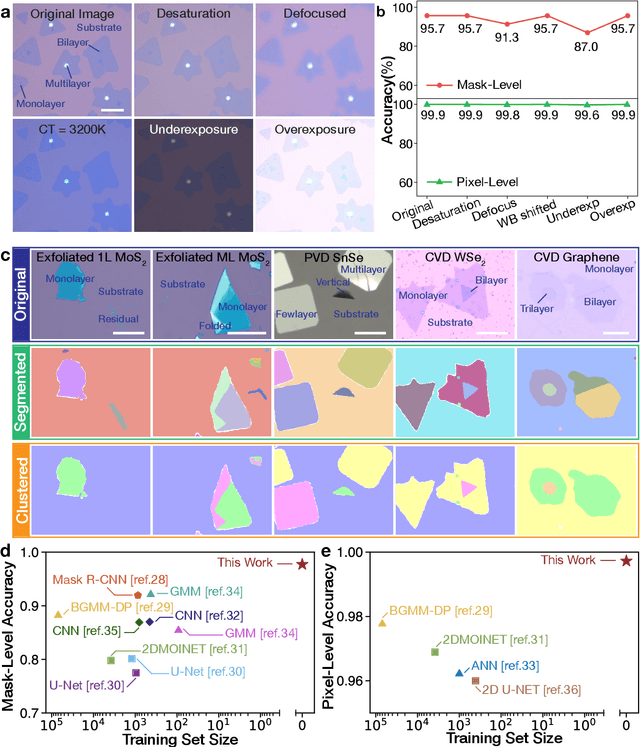
Characterization of atomic-scale materials traditionally requires human experts with months to years of specialized training. Even for trained human operators, accurate and reliable characterization remains challenging when examining newly discovered materials such as two-dimensional (2D) structures. This bottleneck drives demand for fully autonomous experimentation systems capable of comprehending research objectives without requiring large training datasets. In this work, we present ATOMIC (Autonomous Technology for Optical Microscopy & Intelligent Characterization), an end-to-end framework that integrates foundation models to enable fully autonomous, zero-shot characterization of 2D materials. Our system integrates the vision foundation model (i.e., Segment Anything Model), large language models (i.e., ChatGPT), unsupervised clustering, and topological analysis to automate microscope control, sample scanning, image segmentation, and intelligent analysis through prompt engineering, eliminating the need for additional training. When analyzing typical MoS2 samples, our approach achieves 99.7% segmentation accuracy for single layer identification, which is equivalent to that of human experts. In addition, the integrated model is able to detect grain boundary slits that are challenging to identify with human eyes. Furthermore, the system retains robust accuracy despite variable conditions including defocus, color temperature fluctuations, and exposure variations. It is applicable to a broad spectrum of common 2D materials-including graphene, MoS2, WSe2, SnSe-regardless of whether they were fabricated via chemical vapor deposition or mechanical exfoliation. This work represents the implementation of foundation models to achieve autonomous analysis, establishing a scalable and data-efficient characterization paradigm that fundamentally transforms the approach to nanoscale materials research.
Transfer Risk Map: Mitigating Pixel-level Negative Transfer in Medical Segmentation
Feb 04, 2025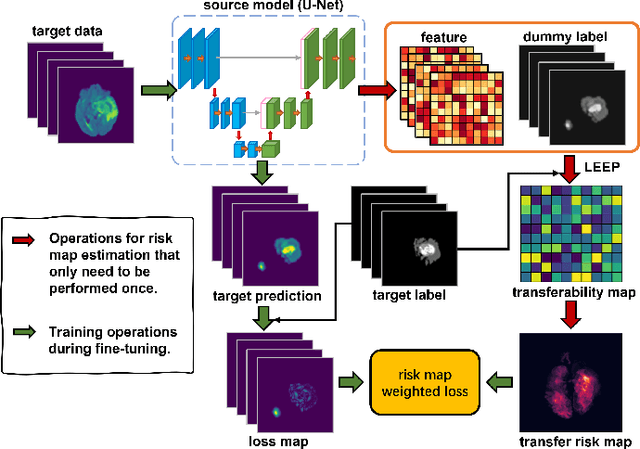



How to mitigate negative transfer in transfer learning is a long-standing and challenging issue, especially in the application of medical image segmentation. Existing methods for reducing negative transfer focus on classification or regression tasks, ignoring the non-uniform negative transfer risk in different image regions. In this work, we propose a simple yet effective weighted fine-tuning method that directs the model's attention towards regions with significant transfer risk for medical semantic segmentation. Specifically, we compute a transferability-guided transfer risk map to quantify the transfer hardness for each pixel and the potential risks of negative transfer. During the fine-tuning phase, we introduce a map-weighted loss function, normalized with image foreground size to counter class imbalance. Extensive experiments on brain segmentation datasets show our method significantly improves the target task performance, with gains of 4.37% on FeTS2021 and 1.81% on iSeg2019, avoiding negative transfer across modalities and tasks. Meanwhile, a 2.9% gain under a few-shot scenario validates the robustness of our approach.
Adapting Foundation Models for Few-Shot Medical Image Segmentation: Actively and Sequentially
Feb 03, 2025
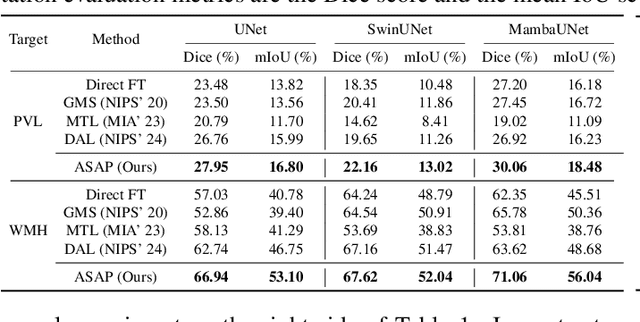


Recent advances in foundation models have brought promising results in computer vision, including medical image segmentation. Fine-tuning foundation models on specific low-resource medical tasks has become a standard practice. However, ensuring reliable and robust model adaptation when the target task has a large domain gap and few annotated samples remains a challenge. Previous few-shot domain adaptation (FSDA) methods seek to bridge the distribution gap between source and target domains by utilizing auxiliary data. The selection and scheduling of auxiliaries are often based on heuristics, which can easily cause negative transfer. In this work, we propose an Active and Sequential domain AdaPtation (ASAP) framework for dynamic auxiliary dataset selection in FSDA. We formulate FSDA as a multi-armed bandit problem and derive an efficient reward function to prioritize training on auxiliary datasets that align closely with the target task, through a single-round fine-tuning. Empirical validation on diverse medical segmentation datasets demonstrates that our method achieves favorable segmentation performance, significantly outperforming the state-of-the-art FSDA methods, achieving an average gain of 27.75% on MRI and 7.52% on CT datasets in Dice score. Code is available at the git repository: https://github.com/techicoco/ASAP.
Selecting the Best Sequential Transfer Path for Medical Image Segmentation with Limited Labeled Data
Oct 09, 2024



The medical image processing field often encounters the critical issue of scarce annotated data. Transfer learning has emerged as a solution, yet how to select an adequate source task and effectively transfer the knowledge to the target task remains challenging. To address this, we propose a novel sequential transfer scheme with a task affinity metric tailored for medical images. Considering the characteristics of medical image segmentation tasks, we analyze the image and label similarity between tasks and compute the task affinity scores, which assess the relatedness among tasks. Based on this, we select appropriate source tasks and develop an effective sequential transfer strategy by incorporating intermediate source tasks to gradually narrow the domain discrepancy and minimize the transfer cost. Thereby we identify the best sequential transfer path for the given target task. Extensive experiments on three MRI medical datasets, FeTS 2022, iSeg-2019, and WMH, demonstrate the efficacy of our method in finding the best source sequence. Compared with directly transferring from a single source task, the sequential transfer results underline a significant improvement in target task performance, achieving an average of 2.58% gain in terms of segmentation Dice score, notably, 6.00% for FeTS 2022. Code is available at the git repository.
Unpacking Failure Modes of Generative Policies: Runtime Monitoring of Consistency and Progress
Oct 06, 2024
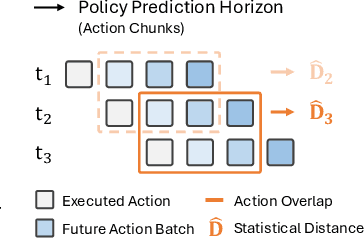

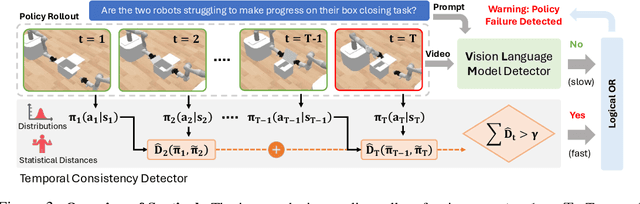
Robot behavior policies trained via imitation learning are prone to failure under conditions that deviate from their training data. Thus, algorithms that monitor learned policies at test time and provide early warnings of failure are necessary to facilitate scalable deployment. We propose Sentinel, a runtime monitoring framework that splits the detection of failures into two complementary categories: 1) Erratic failures, which we detect using statistical measures of temporal action consistency, and 2) task progression failures, where we use Vision Language Models (VLMs) to detect when the policy confidently and consistently takes actions that do not solve the task. Our approach has two key strengths. First, because learned policies exhibit diverse failure modes, combining complementary detectors leads to significantly higher accuracy at failure detection. Second, using a statistical temporal action consistency measure ensures that we quickly detect when multimodal, generative policies exhibit erratic behavior at negligible computational cost. In contrast, we only use VLMs to detect failure modes that are less time-sensitive. We demonstrate our approach in the context of diffusion policies trained on robotic mobile manipulation domains in both simulation and the real world. By unifying temporal consistency detection and VLM runtime monitoring, Sentinel detects 18% more failures than using either of the two detectors alone and significantly outperforms baselines, thus highlighting the importance of assigning specialized detectors to complementary categories of failure. Qualitative results are made available at https://sites.google.com/stanford.edu/sentinel.
Flemme: A Flexible and Modular Learning Platform for Medical Images
Aug 18, 2024



As the rapid development of computer vision and the emergence of powerful network backbones and architectures, the application of deep learning in medical imaging has become increasingly significant. Unlike natural images, medical images lack huge volumes of data but feature more modalities, making it difficult to train a general model that has satisfactory performance across various datasets. In practice, practitioners often suffer from manually creating and testing models combining independent backbones and architectures, which is a laborious and time-consuming process. We propose Flemme, a FLExible and Modular learning platform for MEdical images. Our platform separates encoders from the model architectures so that different models can be constructed via various combinations of supported encoders and architectures. We construct encoders using building blocks based on convolution, transformer, and state-space model (SSM) to process both 2D and 3D image patches. A base architecture is implemented following an encoder-decoder style, with several derived architectures for image segmentation, reconstruction, and generation tasks. In addition, we propose a general hierarchical architecture incorporating a pyramid loss to optimize and fuse vertical features. Experiments demonstrate that this simple design leads to an average improvement of 5.60% in Dice score and 7.81% in mean interaction of units (mIoU) for segmentation models, as well as an enhancement of 5.57% in peak signal-to-noise ratio (PSNR) and 8.22% in structural similarity (SSIM) for reconstruction models. We further utilize Flemme as an analytical tool to assess the effectiveness and efficiency of various encoders across different tasks. Code is available at https://github.com/wlsdzyzl/flemme.
EquiBot: SIM(3)-Equivariant Diffusion Policy for Generalizable and Data Efficient Learning
Jul 01, 2024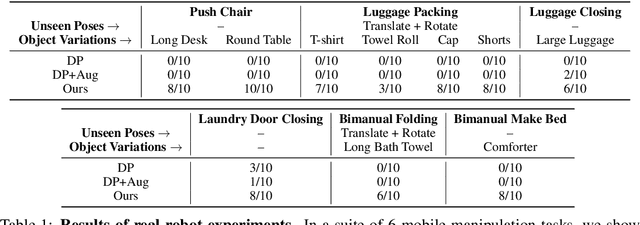
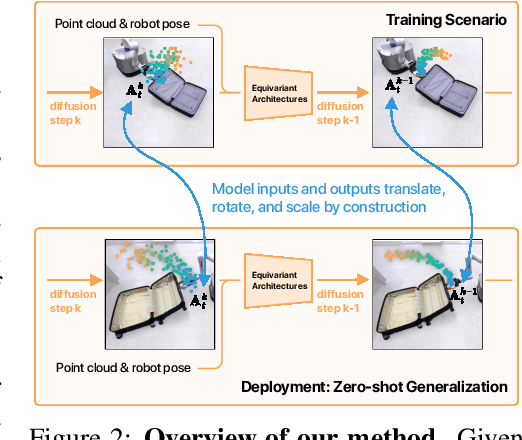


Building effective imitation learning methods that enable robots to learn from limited data and still generalize across diverse real-world environments is a long-standing problem in robot learning. We propose EquiBot, a robust, data-efficient, and generalizable approach for robot manipulation task learning. Our approach combines SIM(3)-equivariant neural network architectures with diffusion models. This ensures that our learned policies are invariant to changes in scale, rotation, and translation, enhancing their applicability to unseen environments while retaining the benefits of diffusion-based policy learning such as multi-modality and robustness. We show in a suite of 6 simulation tasks that our proposed method reduces the data requirements and improves generalization to novel scenarios. In the real world, we show with in total 10 variations of 6 mobile manipulation tasks that our method can easily generalize to novel objects and scenes after learning from just 5 minutes of human demonstrations in each task.