 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond GEMM-Centric NPUs: Enabling Efficient Diffusion LLM Sampling
Jan 28, 2026Diffusion Large Language Models (dLLMs) introduce iterative denoising to enable parallel token generation, but their sampling phase displays fundamentally different characteristics compared to GEMM-centric transformer layers. Profiling on modern GPUs reveals that sampling can account for up to 70% of total model inference latency-primarily due to substantial memory loads and writes from vocabulary-wide logits, reduction-based token selection, and iterative masked updates. These processes demand large on-chip SRAM and involve irregular memory accesses that conventional NPUs struggle to handle efficiently. To address this, we identify a set of critical instructions that an NPU architecture must specifically optimize for dLLM sampling. Our design employs lightweight non-GEMM vector primitives, in-place memory reuse strategies, and a decoupled mixed-precision memory hierarchy. Together, these optimizations deliver up to a 2.53x speedup over the NVIDIA RTX A6000 GPU under an equivalent nm technology node. We also open-source our cycle-accurate simulation and post-synthesis RTL verification code, confirming functional equivalence with current dLLM PyTorch implementations.
CUPID: Curating Data your Robot Loves with Influence Functions
Jun 23, 2025
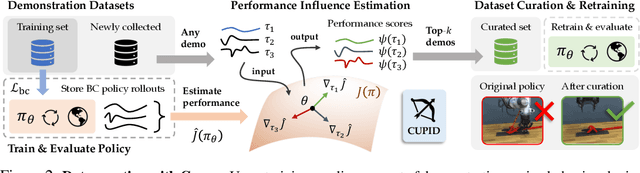
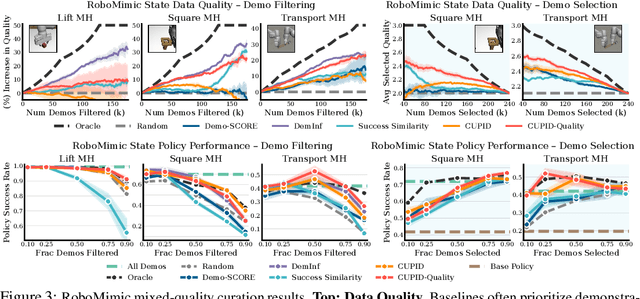
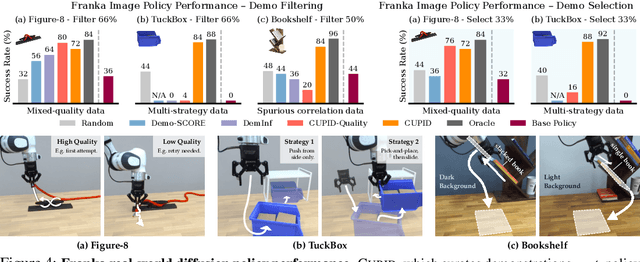
In robot imitation learning, policy performance is tightly coupled with the quality and composition of the demonstration data. Yet, developing a precise understanding of how individual demonstrations contribute to downstream outcomes - such as closed-loop task success or failure - remains a persistent challenge. We propose CUPID, a robot data curation method based on a novel influence function-theoretic formulation for imitation learning policies. Given a set of evaluation rollouts, CUPID estimates the influence of each training demonstration on the policy's expected return. This enables ranking and selection of demonstrations according to their impact on the policy's closed-loop performance. We use CUPID to curate data by 1) filtering out training demonstrations that harm policy performance and 2) subselecting newly collected trajectories that will most improve the policy. Extensive simulated and hardware experiments show that our approach consistently identifies which data drives test-time performance. For example, training with less than 33% of curated data can yield state-of-the-art diffusion policies on the simulated RoboMimic benchmark, with similar gains observed in hardware. Furthermore, hardware experiments show that our method can identify robust strategies under distribution shift, isolate spurious correlations, and even enhance the post-training of generalist robot policies. Additional materials are made available at: https://cupid-curation.github.io.
Mobi-$π$: Mobilizing Your Robot Learning Policy
May 29, 2025Learned visuomotor policies are capable of performing increasingly complex manipulation tasks. However, most of these policies are trained on data collected from limited robot positions and camera viewpoints. This leads to poor generalization to novel robot positions, which limits the use of these policies on mobile platforms, especially for precise tasks like pressing buttons or turning faucets. In this work, we formulate the policy mobilization problem: find a mobile robot base pose in a novel environment that is in distribution with respect to a manipulation policy trained on a limited set of camera viewpoints. Compared to retraining the policy itself to be more robust to unseen robot base pose initializations, policy mobilization decouples navigation from manipulation and thus does not require additional demonstrations. Crucially, this problem formulation complements existing efforts to improve manipulation policy robustness to novel viewpoints and remains compatible with them. To study policy mobilization, we introduce the Mobi-$\pi$ framework, which includes: (1) metrics that quantify the difficulty of mobilizing a given policy, (2) a suite of simulated mobile manipulation tasks based on RoboCasa to evaluate policy mobilization, (3) visualization tools for analysis, and (4) several baseline methods. We also propose a novel approach that bridges navigation and manipulation by optimizing the robot's base pose to align with an in-distribution base pose for a learned policy. Our approach utilizes 3D Gaussian Splatting for novel view synthesis, a score function to evaluate pose suitability, and sampling-based optimization to identify optimal robot poses. We show that our approach outperforms baselines in both simulation and real-world environments, demonstrating its effectiveness for policy mobilization.
Causal-PIK: Causality-based Physical Reasoning with a Physics-Informed Kernel
May 28, 2025



Tasks that involve complex interactions between objects with unknown dynamics make planning before execution difficult. These tasks require agents to iteratively improve their actions after actively exploring causes and effects in the environment. For these type of tasks, we propose Causal-PIK, a method that leverages Bayesian optimization to reason about causal interactions via a Physics-Informed Kernel to help guide efficient search for the best next action. Experimental results on Virtual Tools and PHYRE physical reasoning benchmarks show that Causal-PIK outperforms state-of-the-art results, requiring fewer actions to reach the goal. We also compare Causal-PIK to human studies, including results from a new user study we conducted on the PHYRE benchmark. We find that Causal-PIK remains competitive on tasks that are very challenging, even for human problem-solvers.
Deformable Cargo Transport in Microgravity with Astrobee
May 02, 2025We present pyastrobee: a simulation environment and control stack for Astrobee in Python, with an emphasis on cargo manipulation and transport tasks. We also demonstrate preliminary success from a sampling-based MPC controller, using reduced-order models of NASA's cargo transfer bag (CTB) to control a high-order deformable finite element model. Our code is open-source, fully documented, and available at https://danielpmorton.github.io/pyastrobee
Unpacking Failure Modes of Generative Policies: Runtime Monitoring of Consistency and Progress
Oct 06, 2024
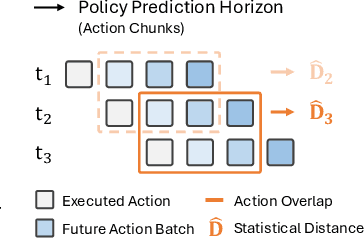

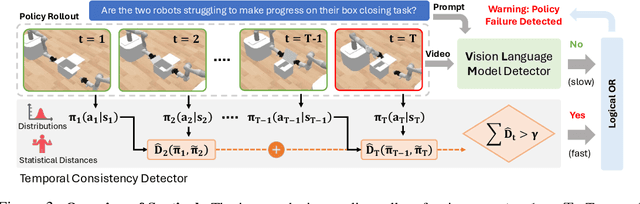
Robot behavior policies trained via imitation learning are prone to failure under conditions that deviate from their training data. Thus, algorithms that monitor learned policies at test time and provide early warnings of failure are necessary to facilitate scalable deployment. We propose Sentinel, a runtime monitoring framework that splits the detection of failures into two complementary categories: 1) Erratic failures, which we detect using statistical measures of temporal action consistency, and 2) task progression failures, where we use Vision Language Models (VLMs) to detect when the policy confidently and consistently takes actions that do not solve the task. Our approach has two key strengths. First, because learned policies exhibit diverse failure modes, combining complementary detectors leads to significantly higher accuracy at failure detection. Second, using a statistical temporal action consistency measure ensures that we quickly detect when multimodal, generative policies exhibit erratic behavior at negligible computational cost. In contrast, we only use VLMs to detect failure modes that are less time-sensitive. We demonstrate our approach in the context of diffusion policies trained on robotic mobile manipulation domains in both simulation and the real world. By unifying temporal consistency detection and VLM runtime monitoring, Sentinel detects 18% more failures than using either of the two detectors alone and significantly outperforms baselines, thus highlighting the importance of assigning specialized detectors to complementary categories of failure. Qualitative results are made available at https://sites.google.com/stanford.edu/sentinel.
EquiBot: SIM(3)-Equivariant Diffusion Policy for Generalizable and Data Efficient Learning
Jul 01, 2024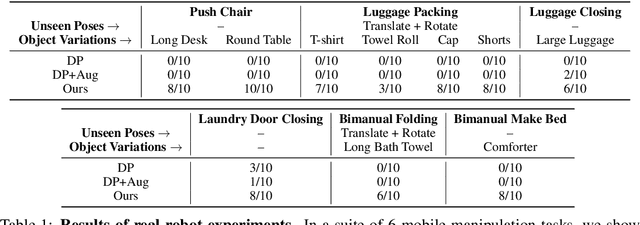


Building effective imitation learning methods that enable robots to learn from limited data and still generalize across diverse real-world environments is a long-standing problem in robot learning. We propose EquiBot, a robust, data-efficient, and generalizable approach for robot manipulation task learning. Our approach combines SIM(3)-equivariant neural network architectures with diffusion models. This ensures that our learned policies are invariant to changes in scale, rotation, and translation, enhancing their applicability to unseen environments while retaining the benefits of diffusion-based policy learning such as multi-modality and robustness. We show in a suite of 6 simulation tasks that our proposed method reduces the data requirements and improves generalization to novel scenarios. In the real world, we show with in total 10 variations of 6 mobile manipulation tasks that our method can easily generalize to novel objects and scenes after learning from just 5 minutes of human demonstrations in each task.
EquivAct: SIM(3)-Equivariant Visuomotor Policies beyond Rigid Object Manipulation
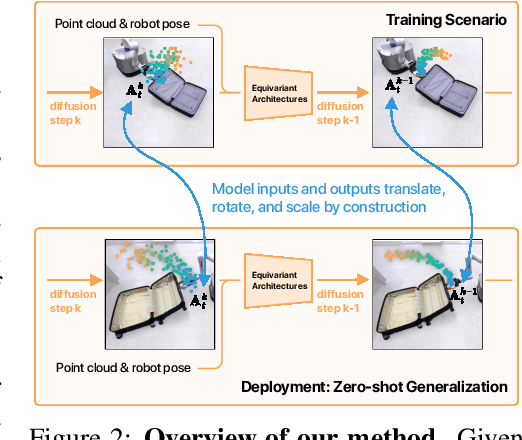
Oct 24, 2023If a robot masters folding a kitchen towel, we would also expect it to master folding a beach towel. However, existing works for policy learning that rely on data set augmentations are still limited in achieving this level of generalization. Our insight is to add equivariance to both the visual object representation and policy architecture. We propose EquivAct which utilizes SIM(3)-equivariant network structures that guarantee generalization across all possible object translations, 3D rotations, and scales by construction. Training of EquivAct is done in two phases. We first pre-train a SIM(3)-equivariant visual representation on simulated scene point clouds. Then, we learn a SIM(3)-equivariant visuomotor policy on top of the pre-trained visual representation using a small amount of source task demonstrations. We demonstrate that after training, the learned policy directly transfers to objects that substantially differ in scale, position and orientation from the source demonstrations. In simulation, we evaluate our method in three manipulation tasks involving deformable and articulated objects thereby going beyond the typical rigid object manipulation tasks that prior works considered. We show that our method outperforms prior works that do not use equivariant architectures or do not use our contrastive pre-training procedure. We also show quantitative and qualitative experiments on three real robot tasks, where the robot watches twenty demonstrations of a tabletop task and transfers zero-shot to a mobile manipulation task in a much larger setup. Project website: https://equivact.github.io
TidyBot: Personalized Robot Assistance with Large Language Models
May 09, 2023For a robot to personalize physical assistance effectively, it must learn user preferences that can be generally reapplied to future scenarios. In this work, we investigate personalization of household cleanup with robots that can tidy up rooms by picking up objects and putting them away. A key challenge is determining the proper place to put each object, as people's preferences can vary greatly depending on personal taste or cultural background. For instance, one person may prefer storing shirts in the drawer, while another may prefer them on the shelf. We aim to build systems that can learn such preferences from just a handful of examples via prior interactions with a particular person. We show that robots can combine language-based planning and perception with the few-shot summarization capabilities of large language models (LLMs) to infer generalized user preferences that are broadly applicable to future interactions. This approach enables fast adaptation and achieves 91.2% accuracy on unseen objects in our benchmark dataset. We also demonstrate our approach on a real-world mobile manipulator called TidyBot, which successfully puts away 85.0% of objects in real-world test scenarios.
Learning Tool Morphology for Contact-Rich Manipulation Tasks with Differentiable Simulation
Nov 04, 2022When humans perform contact-rich manipulation tasks, customized tools are often necessary and play an important role in simplifying the task. For instance, in our daily life, we use various utensils for handling food, such as knives, forks and spoons. Similarly, customized tools for robots may enable them to more easily perform a variety of tasks. Here, we present an end-to-end framework to automatically learn tool morphology for contact-rich manipulation tasks by leveraging differentiable physics simulators. Previous work approached this problem by introducing manually constructed priors that required detailed specification of object 3D model, grasp pose and task description to facilitate the search or optimization. In our approach, we instead only need to define the objective with respect to the task performance and enable learning a robust morphology by randomizing the task variations. The optimization is made tractable by casting this as a continual learning problem. We demonstrate the effectiveness of our method for designing new tools in several scenarios such as winding ropes, flipping a box and pushing peas onto a scoop in simulation. We also validate that the shapes discovered by our method help real robots succeed in these scenarios.