 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrim-LAfD: A Framework to Learn and Adapt Primitive-Based Skills from Demonstrations for Insertion Tasks
Dec 02, 2022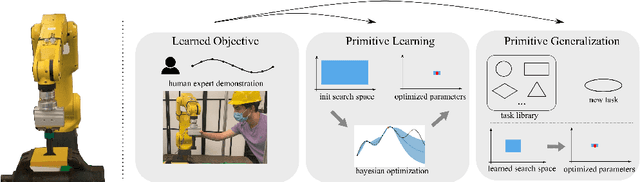

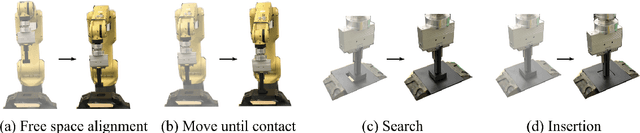

Learning generalizable insertion skills in a data-efficient manner has long been a challenge in the robot learning community. While the current state-of-the-art methods with reinforcement learning (RL) show promising performance in acquiring manipulation skills, the algorithms are data-hungry and hard to generalize. To overcome the issues, in this paper we present Prim-LAfD, a simple yet effective framework to learn and adapt primitive-based insertion skills from demonstrations. Prim-LAfD utilizes black-box function optimization to learn and adapt the primitive parameters leveraging prior experiences. Human demonstrations are modeled as dense rewards guiding parameter learning. We validate the effectiveness of the proposed method on eight peg-hole and connector-socket insertion tasks. The experimental results show that our proposed framework takes less than one hour to acquire the insertion skills and as few as fifteen minutes to adapt to an unseen insertion task on a physical robot.
Learning Tool Morphology for Contact-Rich Manipulation Tasks with Differentiable Simulation
Nov 04, 2022When humans perform contact-rich manipulation tasks, customized tools are often necessary and play an important role in simplifying the task. For instance, in our daily life, we use various utensils for handling food, such as knives, forks and spoons. Similarly, customized tools for robots may enable them to more easily perform a variety of tasks. Here, we present an end-to-end framework to automatically learn tool morphology for contact-rich manipulation tasks by leveraging differentiable physics simulators. Previous work approached this problem by introducing manually constructed priors that required detailed specification of object 3D model, grasp pose and task description to facilitate the search or optimization. In our approach, we instead only need to define the objective with respect to the task performance and enable learning a robust morphology by randomizing the task variations. The optimization is made tractable by casting this as a continual learning problem. We demonstrate the effectiveness of our method for designing new tools in several scenarios such as winding ropes, flipping a box and pushing peas onto a scoop in simulation. We also validate that the shapes discovered by our method help real robots succeed in these scenarios.
Learning Feasibility to Imitate Demonstrators with Different Dynamics
Oct 28, 2021
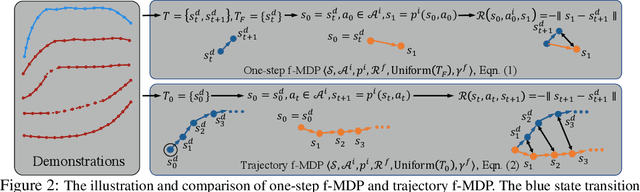

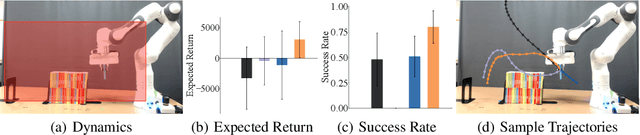
The goal of learning from demonstrations is to learn a policy for an agent (imitator) by mimicking the behavior in the demonstrations. Prior works on learning from demonstrations assume that the demonstrations are collected by a demonstrator that has the same dynamics as the imitator. However, in many real-world applications, this assumption is limiting -- to improve the problem of lack of data in robotics, we would like to be able to leverage demonstrations collected from agents with different dynamics. This can be challenging as the demonstrations might not even be feasible for the imitator. Our insight is that we can learn a feasibility metric that captures the likelihood of a demonstration being feasible by the imitator. We develop a feasibility MDP (f-MDP) and derive the feasibility score by learning an optimal policy in the f-MDP. Our proposed feasibility measure encourages the imitator to learn from more informative demonstrations, and disregard the far from feasible demonstrations. Our experiments on four simulated environments and on a real robot show that the policy learned with our approach achieves a higher expected return than prior works. We show the videos of the real robot arm experiments on our website (https://sites.google.com/view/learning-feasibility).
Learning Latent Actions to Control Assistive Robots
Jul 10, 2021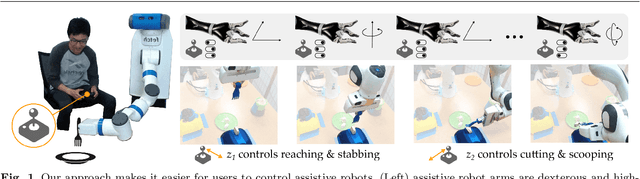

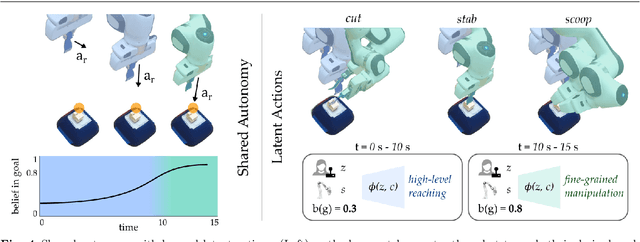
Assistive robot arms enable people with disabilities to conduct everyday tasks on their own. These arms are dexterous and high-dimensional; however, the interfaces people must use to control their robots are low-dimensional. Consider teleoperating a 7-DoF robot arm with a 2-DoF joystick. The robot is helping you eat dinner, and currently you want to cut a piece of tofu. Today's robots assume a pre-defined mapping between joystick inputs and robot actions: in one mode the joystick controls the robot's motion in the x-y plane, in another mode the joystick controls the robot's z-yaw motion, and so on. But this mapping misses out on the task you are trying to perform! Ideally, one joystick axis should control how the robot stabs the tofu and the other axis should control different cutting motions. Our insight is that we can achieve intuitive, user-friendly control of assistive robots by embedding the robot's high-dimensional actions into low-dimensional and human-controllable latent actions. We divide this process into three parts. First, we explore models for learning latent actions from offline task demonstrations, and formalize the properties that latent actions should satisfy. Next, we combine learned latent actions with autonomous robot assistance to help the user reach and maintain their high-level goals. Finally, we learn a personalized alignment model between joystick inputs and latent actions. We evaluate our resulting approach in four user studies where non-disabled participants reach marshmallows, cook apple pie, cut tofu, and assemble dessert. We then test our approach with two disabled adults who leverage assistive devices on a daily basis.
Learning Human Objectives from Sequences of Physical Corrections
Mar 31, 2021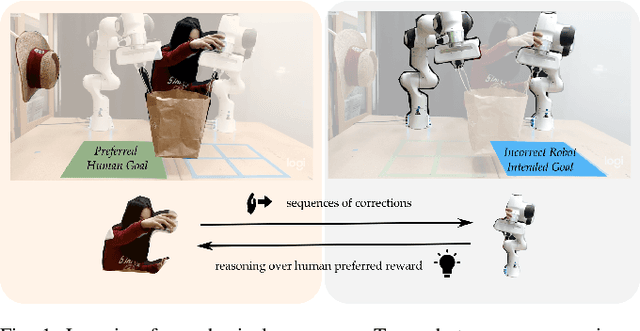
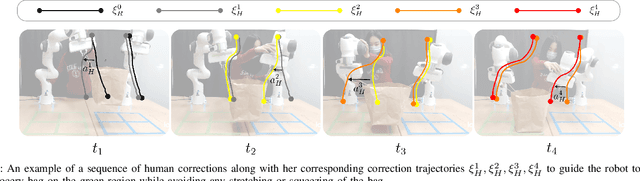
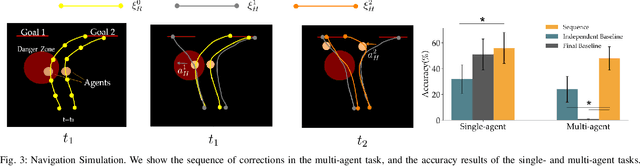
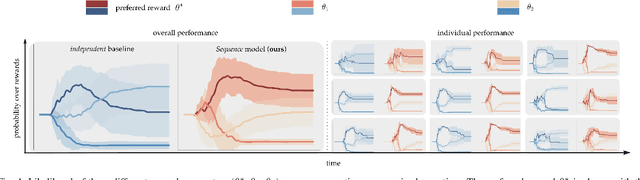
When personal, assistive, and interactive robots make mistakes, humans naturally and intuitively correct those mistakes through physical interaction. In simple situations, one correction is sufficient to convey what the human wants. But when humans are working with multiple robots or the robot is performing an intricate task often the human must make several corrections to fix the robot's behavior. Prior research assumes each of these physical corrections are independent events, and learns from them one-at-a-time. However, this misses out on crucial information: each of these interactions are interconnected, and may only make sense if viewed together. Alternatively, other work reasons over the final trajectory produced by all of the human's corrections. But this method must wait until the end of the task to learn from corrections, as opposed to inferring from the corrections in an online fashion. In this paper we formalize an approach for learning from sequences of physical corrections during the current task. To do this we introduce an auxiliary reward that captures the human's trade-off between making corrections which improve the robot's immediate reward and long-term performance. We evaluate the resulting algorithm in remote and in-person human-robot experiments, and compare to both independent and final baselines. Our results indicate that users are best able to convey their objective when the robot reasons over their sequence of corrections.
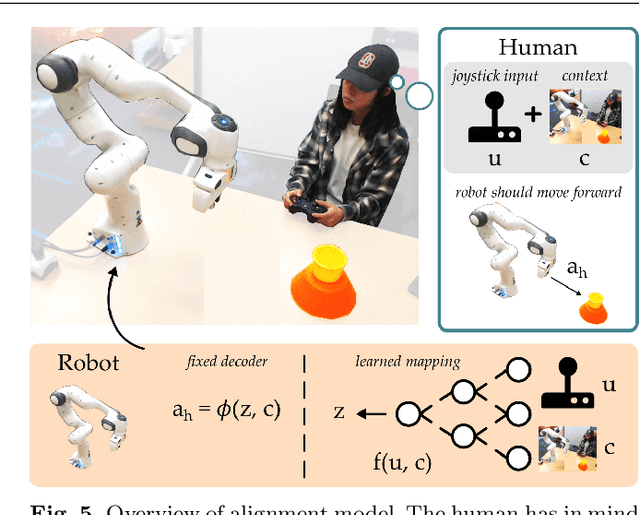
Learning User-Preferred Mappings for Intuitive Robot Control
Jul 22, 2020
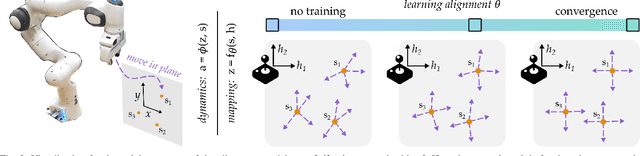
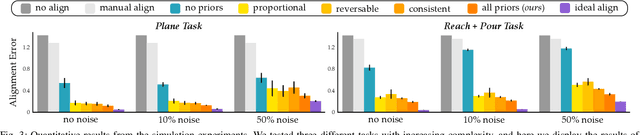
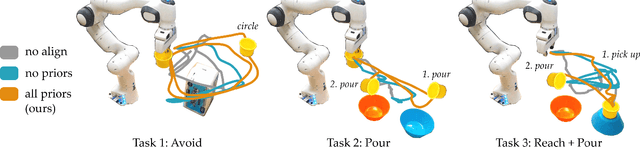
When humans control drones, cars, and robots, we often have some preconceived notion of how our inputs should make the system behave. Existing approaches to teleoperation typically assume a one-size-fits-all approach, where the designers pre-define a mapping between human inputs and robot actions, and every user must adapt to this mapping over repeated interactions. Instead, we propose a personalized method for learning the human's preferred or preconceived mapping from a few robot queries. Given a robot controller, we identify an alignment model that transforms the human's inputs so that the controller's output matches their expectations. We make this approach data-efficient by recognizing that human mappings have strong priors: we expect the input space to be proportional, reversable, and consistent. Incorporating these priors ensures that the robot learns an intuitive mapping from few examples. We test our learning approach in robot manipulation tasks inspired by assistive settings, where each user has different personal preferences and physical capabilities for teleoperating the robot arm. Our simulated and experimental results suggest that learning the mapping between inputs and robot actions improves objective and subjective performance when compared to manually defined alignments or learned alignments without intuitive priors. The supplementary video showing these user studies can be found at: https://youtu.be/rKHka0_48-Q.
Learning from My Partner's Actions: Roles in Decentralized Robot Teams
Oct 28, 2019

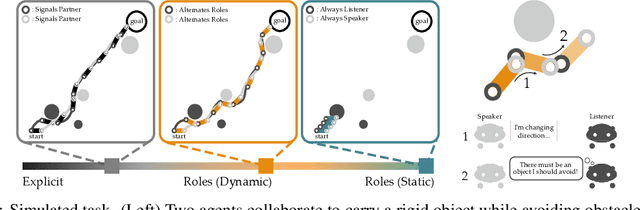

When teams of robots collaborate to complete a task, communication is often necessary. Like humans, robot teammates should implicitly communicate through their actions: but interpreting our partner's actions is typically difficult, since a given action may have many different underlying reasons. Here we propose an alternate approach: instead of not being able to infer whether an action is due to exploration, exploitation, or communication, we define separate roles for each agent. Because each role defines a distinct reason for acting (e.g., only exploit, only communicate), teammates now correctly interpret the meaning behind their partner's actions. Our results suggest that leveraging and alternating roles leads to performance comparable to teams that explicitly exchange messages. You can find more images and videos of our experimental setups at http://ai.stanford.edu/blog/learning-from-partners/.
Smooth Neighbors on Teacher Graphs for Semi-supervised Learning
Mar 28, 2018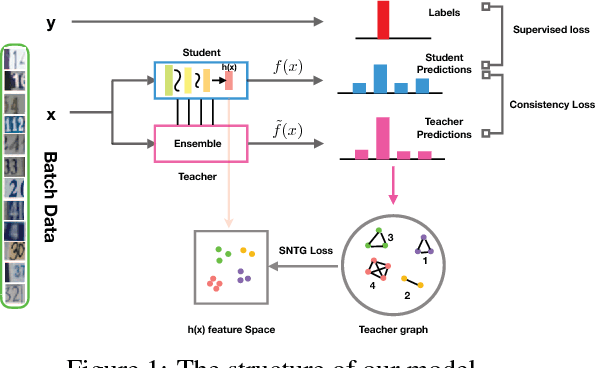
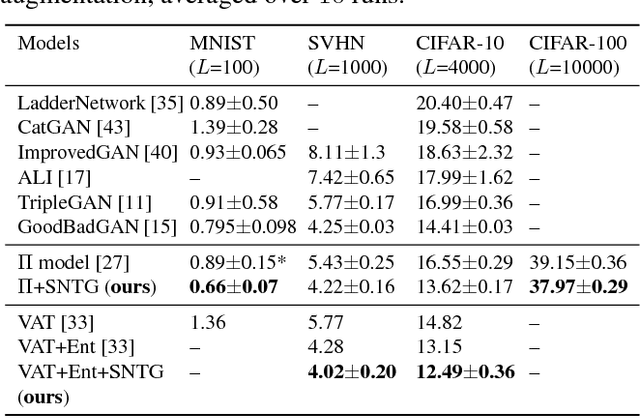
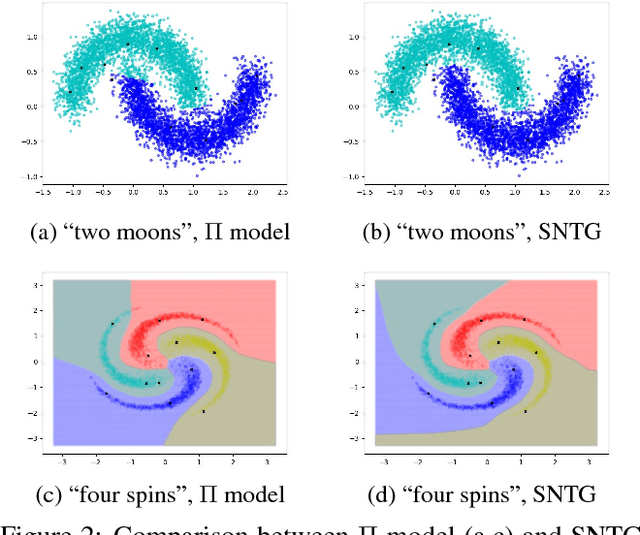
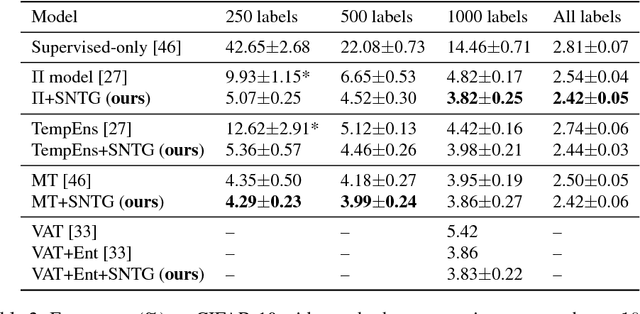
The recently proposed self-ensembling methods have achieved promising results in deep semi-supervised learning, which penalize inconsistent predictions of unlabeled data under different perturbations. However, they only consider adding perturbations to each single data point, while ignoring the connections between data samples. In this paper, we propose a novel method, called Smooth Neighbors on Teacher Graphs (SNTG). In SNTG, a graph is constructed based on the predictions of the teacher model, i.e., the implicit self-ensemble of models. Then the graph serves as a similarity measure with respect to which the representations of "similar" neighboring points are learned to be smooth on the low-dimensional manifold. We achieve state-of-the-art results on semi-supervised learning benchmarks. The error rates are 9.89%, 3.99% for CIFAR-10 with 4000 labels, SVHN with 500 labels, respectively. In particular, the improvements are significant when the labels are fewer. For the non-augmented MNIST with only 20 labels, the error rate is reduced from previous 4.81% to 1.36%. Our method also shows robustness to noisy labels.