 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Feasibility to Imitate Demonstrators with Different Dynamics
Paper and Code
Oct 28, 2021
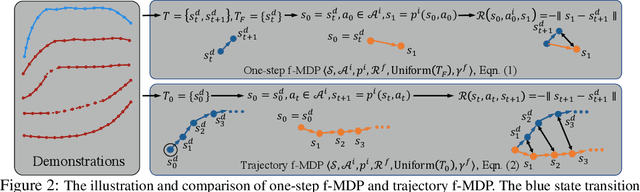

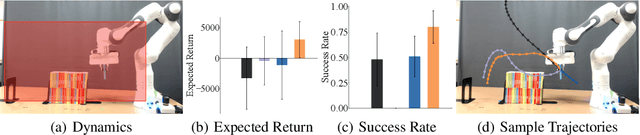
The goal of learning from demonstrations is to learn a policy for an agent (imitator) by mimicking the behavior in the demonstrations. Prior works on learning from demonstrations assume that the demonstrations are collected by a demonstrator that has the same dynamics as the imitator. However, in many real-world applications, this assumption is limiting -- to improve the problem of lack of data in robotics, we would like to be able to leverage demonstrations collected from agents with different dynamics. This can be challenging as the demonstrations might not even be feasible for the imitator. Our insight is that we can learn a feasibility metric that captures the likelihood of a demonstration being feasible by the imitator. We develop a feasibility MDP (f-MDP) and derive the feasibility score by learning an optimal policy in the f-MDP. Our proposed feasibility measure encourages the imitator to learn from more informative demonstrations, and disregard the far from feasible demonstrations. Our experiments on four simulated environments and on a real robot show that the policy learned with our approach achieves a higher expected return than prior works. We show the videos of the real robot arm experiments on our website (https://sites.google.com/view/learning-feasibility).