 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Dynamics Imitation Learning from Multimodal Demonstrations
Nov 13, 2022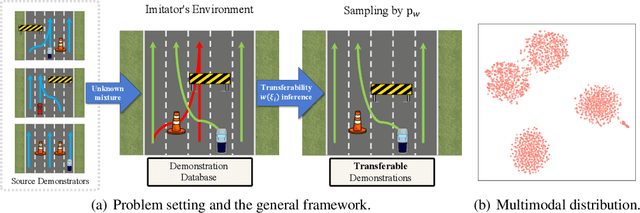
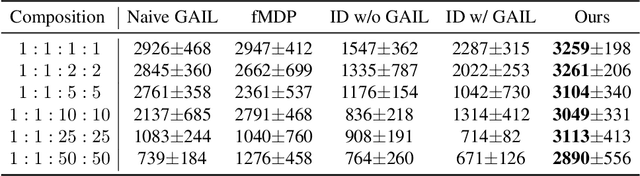
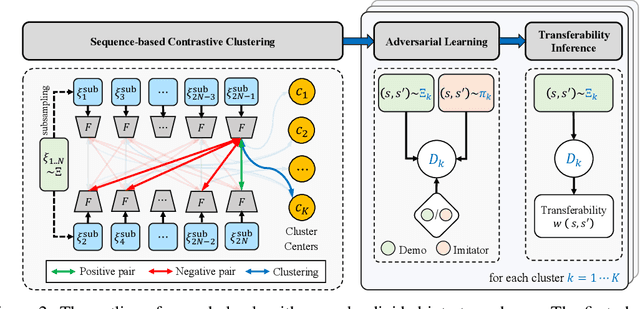

Existing imitation learning works mainly assume that the demonstrator who collects demonstrations shares the same dynamics as the imitator. However, the assumption limits the usage of imitation learning, especially when collecting demonstrations for the imitator is difficult. In this paper, we study out-of-dynamics imitation learning (OOD-IL), which relaxes the assumption to that the demonstrator and the imitator have the same state spaces but could have different action spaces and dynamics. OOD-IL enables imitation learning to utilize demonstrations from a wide range of demonstrators but introduces a new challenge: some demonstrations cannot be achieved by the imitator due to the different dynamics. Prior works try to filter out such demonstrations by feasibility measurements, but ignore the fact that the demonstrations exhibit a multimodal distribution since the different demonstrators may take different policies in different dynamics. We develop a better transferability measurement to tackle this newly-emerged challenge. We firstly design a novel sequence-based contrastive clustering algorithm to cluster demonstrations from the same mode to avoid the mutual interference of demonstrations from different modes, and then learn the transferability of each demonstration with an adversarial-learning based algorithm in each cluster. Experiment results on several MuJoCo environments, a driving environment, and a simulated robot environment show that the proposed transferability measurement more accurately finds and down-weights non-transferable demonstrations and outperforms prior works on the final imitation learning performance. We show the videos of our experiment results on our website.
Masked Imitation Learning: Discovering Environment-Invariant Modalities in Multimodal Demonstrations
Sep 16, 2022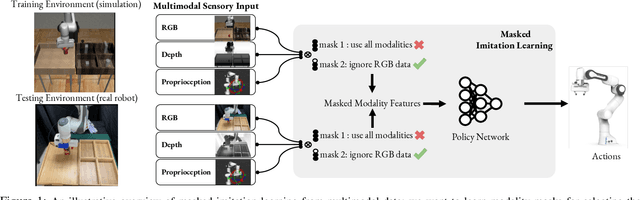
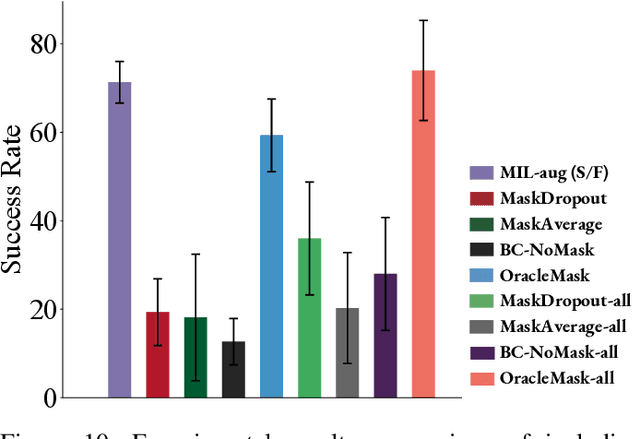
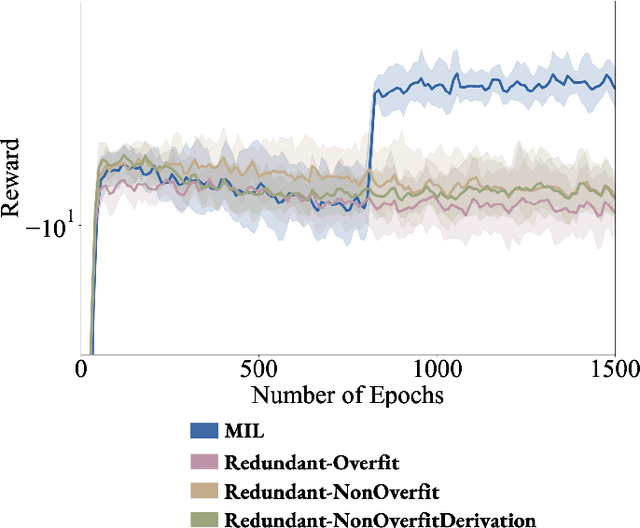
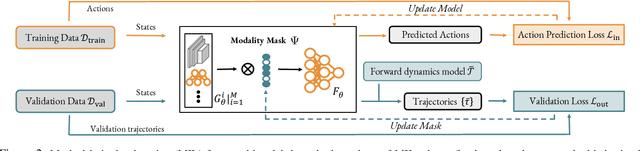
Multimodal demonstrations provide robots with an abundance of information to make sense of the world. However, such abundance may not always lead to good performance when it comes to learning sensorimotor control policies from human demonstrations. Extraneous data modalities can lead to state over-specification, where the state contains modalities that are not only useless for decision-making but also can change data distribution across environments. State over-specification leads to issues such as the learned policy not generalizing outside of the training data distribution. In this work, we propose Masked Imitation Learning (MIL) to address state over-specification by selectively using informative modalities. Specifically, we design a masked policy network with a binary mask to block certain modalities. We develop a bi-level optimization algorithm that learns this mask to accurately filter over-specified modalities. We demonstrate empirically that MIL outperforms baseline algorithms in simulated domains including MuJoCo and a robot arm environment using the Robomimic dataset, and effectively recovers the environment-invariant modalities on a multimodal dataset collected on a real robot. Our project website presents supplemental details and videos of our results at: https://tinyurl.com/masked-il
Hub-Pathway: Transfer Learning from A Hub of Pre-trained Models
Jun 08, 2022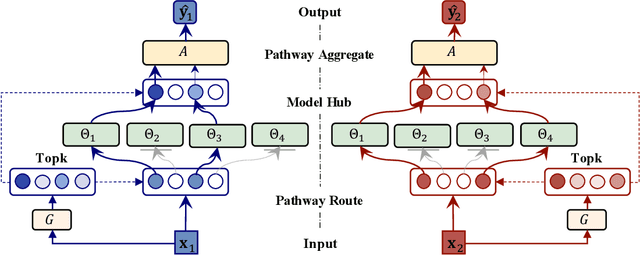
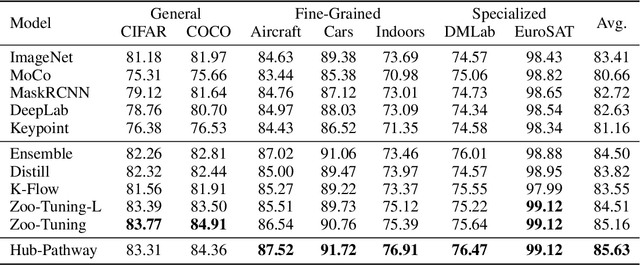
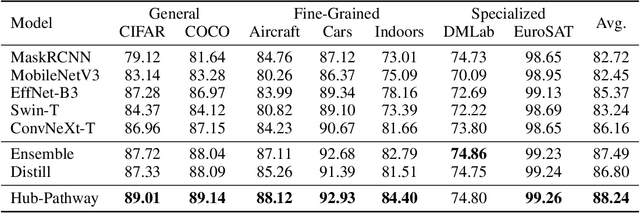
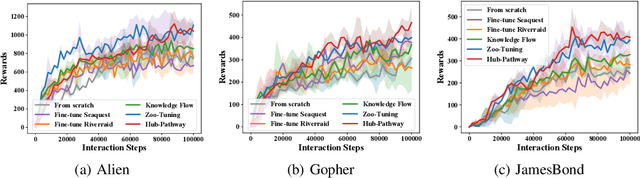
Transfer learning aims to leverage knowledge from pre-trained models to benefit the target task. Prior transfer learning work mainly transfers from a single model. However, with the emergence of deep models pre-trained from different resources, model hubs consisting of diverse models with various architectures, pre-trained datasets and learning paradigms are available. Directly applying single-model transfer learning methods to each model wastes the abundant knowledge of the model hub and suffers from high computational cost. In this paper, we propose a Hub-Pathway framework to enable knowledge transfer from a model hub. The framework generates data-dependent pathway weights, based on which we assign the pathway routes at the input level to decide which pre-trained models are activated and passed through, and then set the pathway aggregation at the output level to aggregate the knowledge from different models to make predictions. The proposed framework can be trained end-to-end with the target task-specific loss, where it learns to explore better pathway configurations and exploit the knowledge in pre-trained models for each target datum. We utilize a noisy pathway generator and design an exploration loss to further explore different pathways throughout the model hub. To fully exploit the knowledge in pre-trained models, each model is further trained by specific data that activate it, which ensures its performance and enhances knowledge transfer. Experiment results on computer vision and reinforcement learning tasks demonstrate that the proposed Hub-Pathway framework achieves the state-of-the-art performance for model hub transfer learning.
MetaSets: Meta-Learning on Point Sets for Generalizable Representations
Apr 15, 2022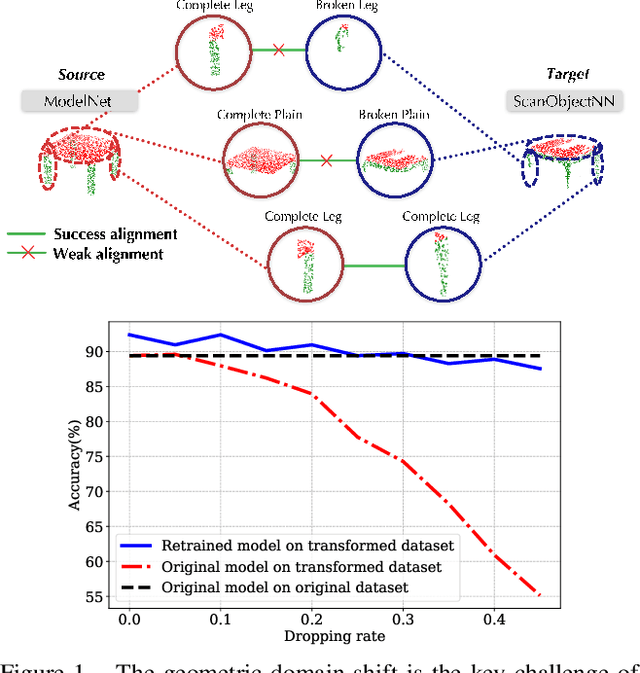
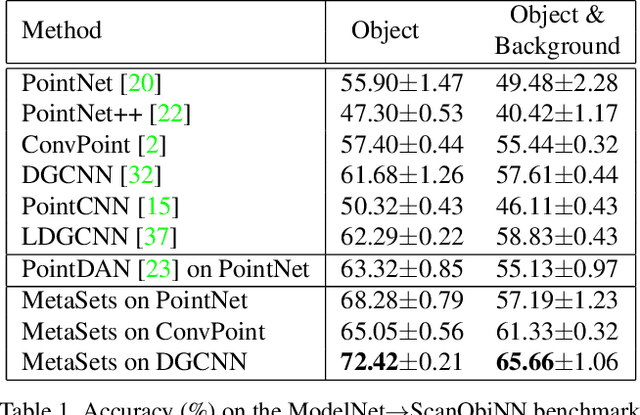
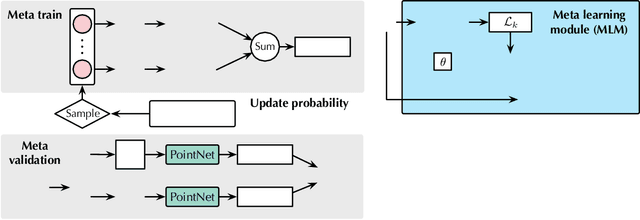

Deep learning techniques for point clouds have achieved strong performance on a range of 3D vision tasks. However, it is costly to annotate large-scale point sets, making it critical to learn generalizable representations that can transfer well across different point sets. In this paper, we study a new problem of 3D Domain Generalization (3DDG) with the goal to generalize the model to other unseen domains of point clouds without any access to them in the training process. It is a challenging problem due to the substantial geometry shift from simulated to real data, such that most existing 3D models underperform due to overfitting the complete geometries in the source domain. We propose to tackle this problem via MetaSets, which meta-learns point cloud representations from a group of classification tasks on carefully-designed transformed point sets containing specific geometry priors. The learned representations are more generalizable to various unseen domains of different geometries. We design two benchmarks for Sim-to-Real transfer of 3D point clouds. Experimental results show that MetaSets outperforms existing 3D deep learning methods by large margins.
Leveraging Smooth Attention Prior for Multi-Agent Trajectory Prediction
Mar 19, 2022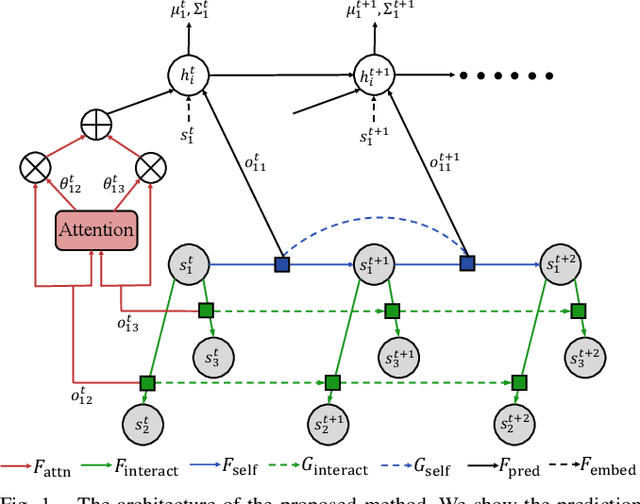
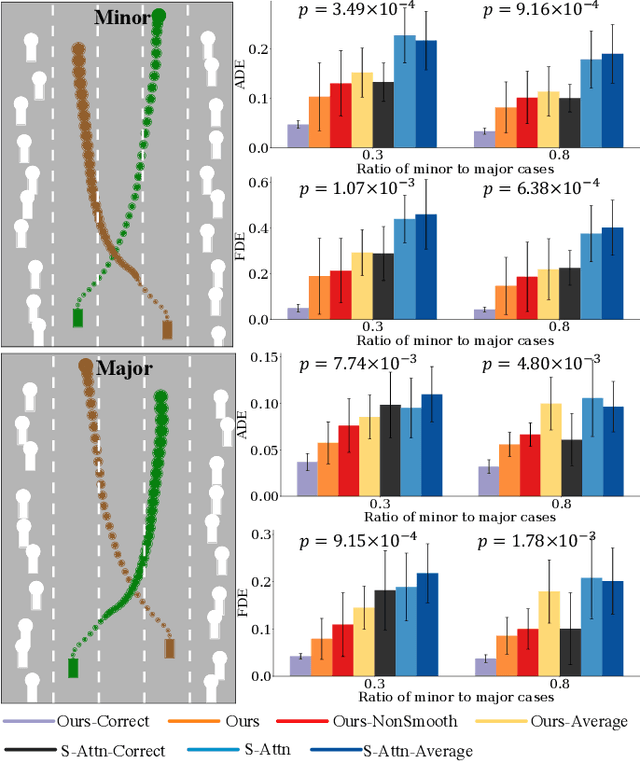
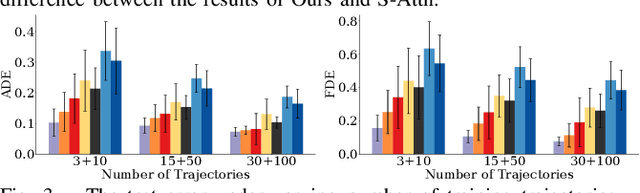
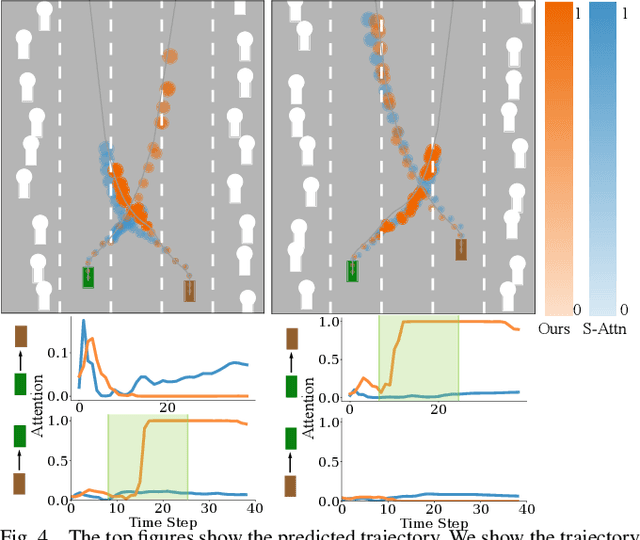
Multi-agent interactions are important to model for forecasting other agents' behaviors and trajectories. At a certain time, to forecast a reasonable future trajectory, each agent needs to pay attention to the interactions with only a small group of most relevant agents instead of unnecessarily paying attention to all the other agents. However, existing attention modeling works ignore that human attention in driving does not change rapidly, and may introduce fluctuating attention across time steps. In this paper, we formulate an attention model for multi-agent interactions based on a total variation temporal smoothness prior and propose a trajectory prediction architecture that leverages the knowledge of these attended interactions. We demonstrate how the total variation attention prior along with the new sequence prediction loss terms leads to smoother attention and more sample-efficient learning of multi-agent trajectory prediction, and show its advantages in terms of prediction accuracy by comparing it with the state-of-the-art approaches on both synthetic and naturalistic driving data. We demonstrate the performance of our algorithm for trajectory prediction on the INTERACTION dataset on our website.
* 8 pages
From Big to Small: Adaptive Learning to Partial-Set Domains
Mar 14, 2022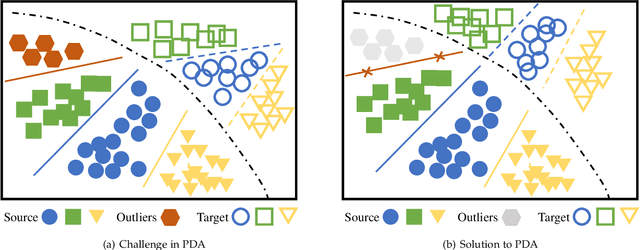

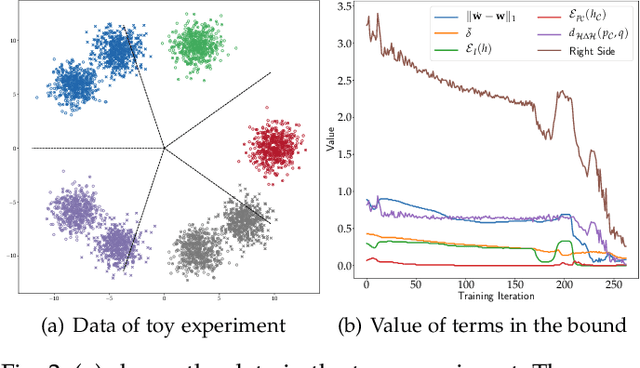
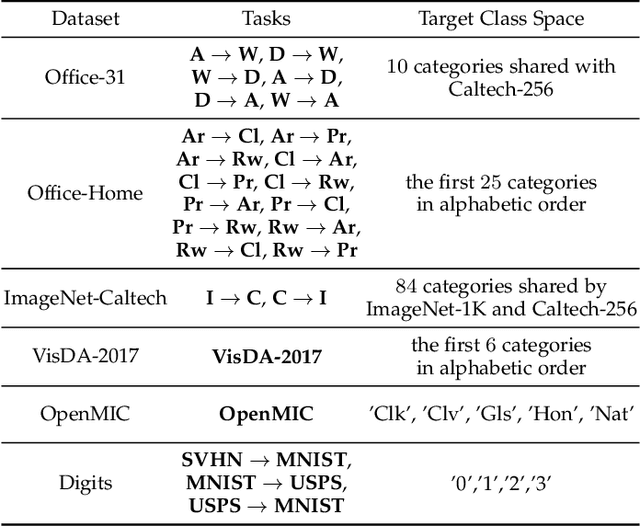
Domain adaptation targets at knowledge acquisition and dissemination from a labeled source domain to an unlabeled target domain under distribution shift. Still, the common requirement of identical class space shared across domains hinders applications of domain adaptation to partial-set domains. Recent advances show that deep pre-trained models of large scale endow rich knowledge to tackle diverse downstream tasks of small scale. Thus, there is a strong incentive to adapt models from large-scale domains to small-scale domains. This paper introduces Partial Domain Adaptation (PDA), a learning paradigm that relaxes the identical class space assumption to that the source class space subsumes the target class space. First, we present a theoretical analysis of partial domain adaptation, which uncovers the importance of estimating the transferable probability of each class and each instance across domains. Then, we propose Selective Adversarial Network (SAN and SAN++) with a bi-level selection strategy and an adversarial adaptation mechanism. The bi-level selection strategy up-weighs each class and each instance simultaneously for source supervised training, target self-training, and source-target adversarial adaptation through the transferable probability estimated alternately by the model. Experiments on standard partial-set datasets and more challenging tasks with superclasses show that SAN++ outperforms several domain adaptation methods.
Weakly Supervised Correspondence Learning
Mar 07, 2022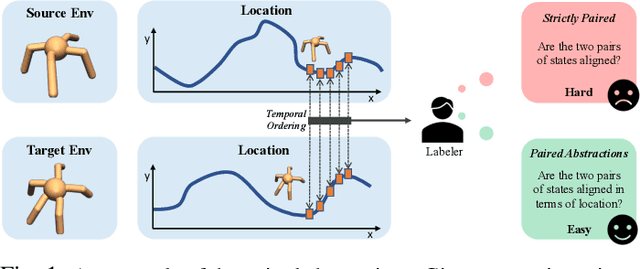
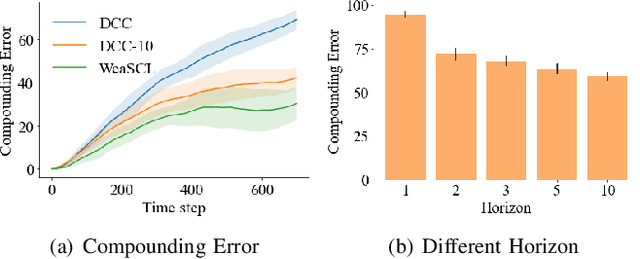
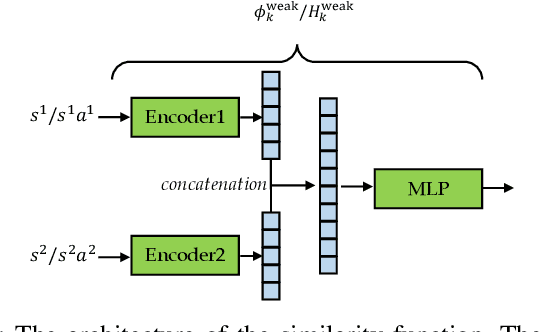
Correspondence learning is a fundamental problem in robotics, which aims to learn a mapping between state, action pairs of agents of different dynamics or embodiments. However, current correspondence learning methods either leverage strictly paired data -- which are often difficult to collect -- or learn in an unsupervised fashion from unpaired data using regularization techniques such as cycle-consistency -- which suffer from severe misalignment issues. We propose a weakly supervised correspondence learning approach that trades off between strong supervision over strictly paired data and unsupervised learning with a regularizer over unpaired data. Our idea is to leverage two types of weak supervision: i) temporal ordering of states and actions to reduce the compounding error, and ii) paired abstractions, instead of paired data, to alleviate the misalignment problem and learn a more accurate correspondence. The two types of weak supervision are easy to access in real-world applications, which simultaneously reduces the high cost of annotating strictly paired data and improves the quality of the learned correspondence.
Learning from Imperfect Demonstrations via Adversarial Confidence Transfer
Feb 07, 2022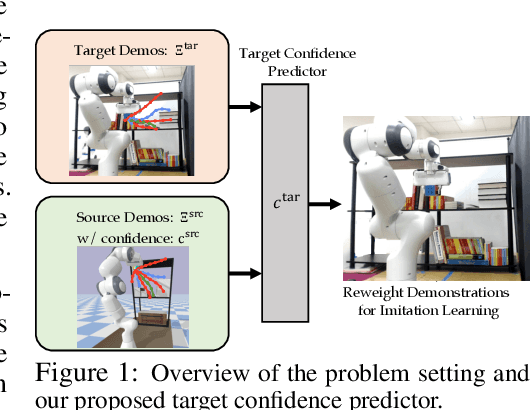
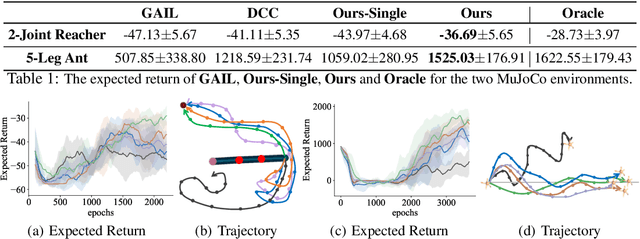
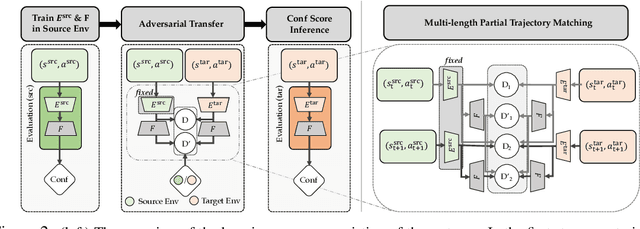
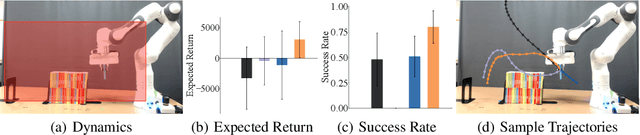
Existing learning from demonstration algorithms usually assume access to expert demonstrations. However, this assumption is limiting in many real-world applications since the collected demonstrations may be suboptimal or even consist of failure cases. We therefore study the problem of learning from imperfect demonstrations by learning a confidence predictor. Specifically, we rely on demonstrations along with their confidence values from a different correspondent environment (source environment) to learn a confidence predictor for the environment we aim to learn a policy in (target environment -- where we only have unlabeled demonstrations.) We learn a common latent space through adversarial distribution matching of multi-length partial trajectories to enable the transfer of confidence across source and target environments. The learned confidence reweights the demonstrations to enable learning more from informative demonstrations and discarding the irrelevant ones. Our experiments in three simulated environments and a real robot reaching task demonstrate that our approach learns a policy with the highest expected return.
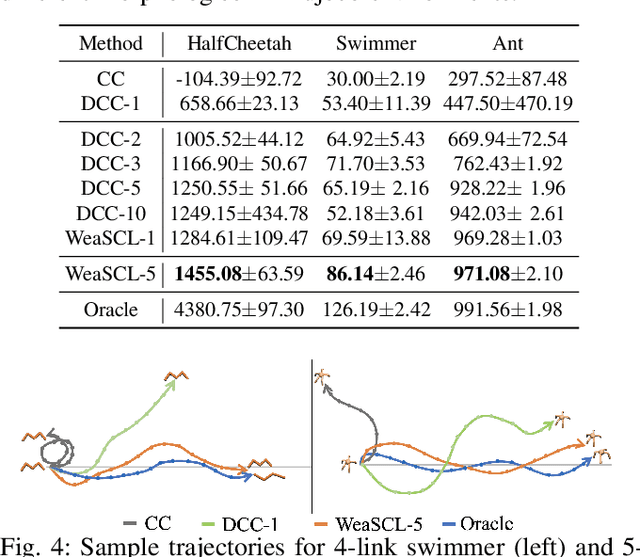
Learning Feasibility to Imitate Demonstrators with Different Dynamics
Oct 28, 2021
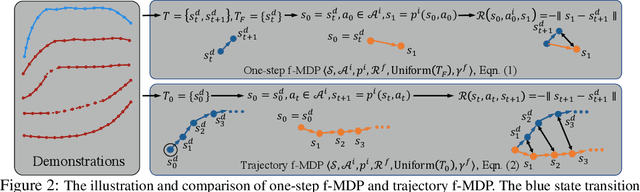

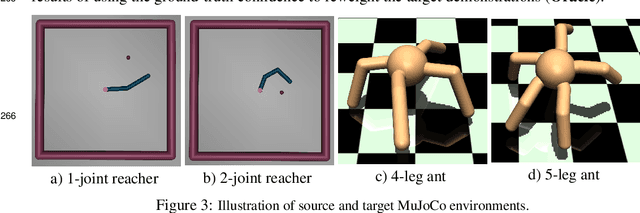
The goal of learning from demonstrations is to learn a policy for an agent (imitator) by mimicking the behavior in the demonstrations. Prior works on learning from demonstrations assume that the demonstrations are collected by a demonstrator that has the same dynamics as the imitator. However, in many real-world applications, this assumption is limiting -- to improve the problem of lack of data in robotics, we would like to be able to leverage demonstrations collected from agents with different dynamics. This can be challenging as the demonstrations might not even be feasible for the imitator. Our insight is that we can learn a feasibility metric that captures the likelihood of a demonstration being feasible by the imitator. We develop a feasibility MDP (f-MDP) and derive the feasibility score by learning an optimal policy in the f-MDP. Our proposed feasibility measure encourages the imitator to learn from more informative demonstrations, and disregard the far from feasible demonstrations. Our experiments on four simulated environments and on a real robot show that the policy learned with our approach achieves a higher expected return than prior works. We show the videos of the real robot arm experiments on our website (https://sites.google.com/view/learning-feasibility).
Confidence-Aware Imitation Learning from Demonstrations with Varying Optimality
Oct 27, 2021
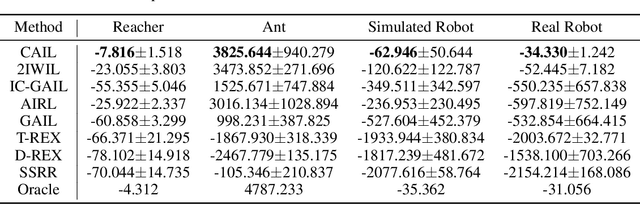


Most existing imitation learning approaches assume the demonstrations are drawn from experts who are optimal, but relaxing this assumption enables us to use a wider range of data. Standard imitation learning may learn a suboptimal policy from demonstrations with varying optimality. Prior works use confidence scores or rankings to capture beneficial information from demonstrations with varying optimality, but they suffer from many limitations, e.g., manually annotated confidence scores or high average optimality of demonstrations. In this paper, we propose a general framework to learn from demonstrations with varying optimality that jointly learns the confidence score and a well-performing policy. Our approach, Confidence-Aware Imitation Learning (CAIL) learns a well-performing policy from confidence-reweighted demonstrations, while using an outer loss to track the performance of our model and to learn the confidence. We provide theoretical guarantees on the convergence of CAIL and evaluate its performance in both simulated and real robot experiments. Our results show that CAIL significantly outperforms other imitation learning methods from demonstrations with varying optimality. We further show that even without access to any optimal demonstrations, CAIL can still learn a successful policy, and outperforms prior work.