 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCCL-EP: Portable Expert-Parallel Communication
Dec 22, 2025Mixture-of-Experts (MoE) workloads rely on expert parallelism (EP) to achieve high GPU efficiency. State-of-the-art EP communication systems such as DeepEP demonstrate strong performance but exhibit poor portability across heterogeneous GPU and NIC platforms. The poor portability is rooted in architecture: GPU-initiated token-level RDMA communication requires tight vertical integration between GPUs and NICs, e.g., GPU writes to NIC driver/MMIO interfaces. We present UCCL-EP, a portable EP communication system that delivers DeepEP-level performance across heterogeneous GPU and NIC hardware. UCCL-EP replaces GPU-initiated RDMA with a high-throughput GPU-CPU control channel: compact token-routing commands are transferred to multithreaded CPU proxies, which then issue GPUDirect RDMA operations on behalf of GPUs. UCCL-EP further emulates various ordering semantics required by specialized EP communication modes using RDMA immediate data, enabling correctness on NICs that lack such ordering, e.g., AWS EFA. We implement UCCL-EP on NVIDIA and AMD GPUs with EFA and Broadcom NICs. On EFA, it outperforms the best existing EP solution by up to $2.1\times$ for dispatch and combine throughput. On NVIDIA-only platform, UCCL-EP achieves comparable performance to the original DeepEP. UCCL-EP also improves token throughput on SGLang by up to 40% on the NVIDIA+EFA platform, and improves DeepSeek-V3 training throughput over the AMD Primus/Megatron-LM framework by up to 45% on a 16-node AMD+Broadcom platform.
depyf: Open the Opaque Box of PyTorch Compiler for Machine Learning Researchers
Mar 14, 2024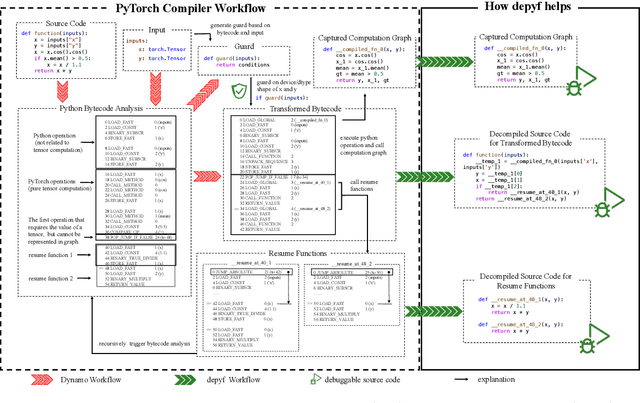


PyTorch \texttt{2.x} introduces a compiler designed to accelerate deep learning programs. However, for machine learning researchers, adapting to the PyTorch compiler to full potential can be challenging. The compiler operates at the Python bytecode level, making it appear as an opaque box. To address this, we introduce \texttt{depyf}, a tool designed to demystify the inner workings of the PyTorch compiler. \texttt{depyf} decompiles bytecode generated by PyTorch back into equivalent source code, and establishes connections between in-memory code objects and their on-disk source code counterparts. This feature enables users to step through the source code line by line using debuggers, thus enhancing their understanding of the underlying processes. Notably, \texttt{depyf} is non-intrusive and user-friendly, primarily relying on two convenient context managers for its core functionality. The project is \href{https://github.com/thuml/depyf}{ openly available} and is recognized as a \href{https://pytorch.org/ecosystem/}{PyTorch ecosystem project}.
Tune-Mode ConvBN Blocks For Efficient Transfer Learning
May 19, 2023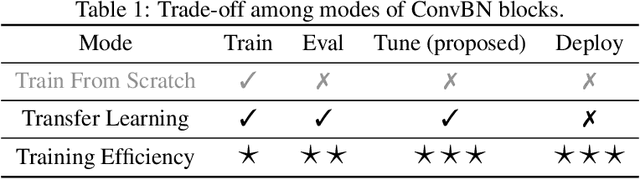

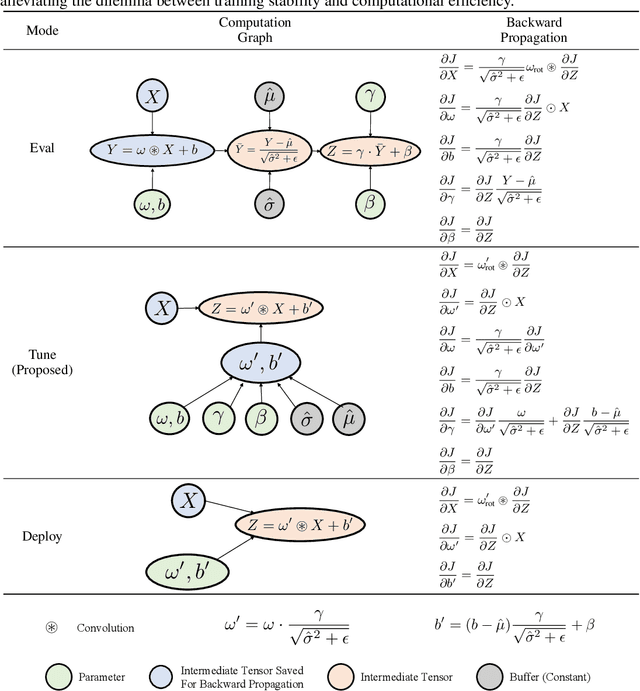

Convolution-BatchNorm (ConvBN) blocks are integral components in various computer vision tasks and other domains. A ConvBN block can operate in three modes: Train, Eval, and Deploy. While the Train mode is indispensable for training models from scratch, the Eval mode is suitable for transfer learning and model validation, and the Deploy mode is designed for the deployment of models. This paper focuses on the trade-off between stability and efficiency in ConvBN blocks: Deploy mode is efficient but suffers from training instability; Eval mode is widely used in transfer learning but lacks efficiency. To solve the dilemma, we theoretically reveal the reason behind the diminished training stability observed in the Deploy mode. Subsequently, we propose a novel Tune mode to bridge the gap between Eval mode and Deploy mode. The proposed Tune mode is as stable as Eval mode for transfer learning, and its computational efficiency closely matches that of the Deploy mode. Through extensive experiments in both object detection and classification tasks, carried out across various datasets and model architectures, we demonstrate that the proposed Tune mode does not hurt the original performance while significantly reducing GPU memory footprint and training time, thereby contributing an efficient solution to transfer learning with convolutional networks.
Video Interpolation by Event-driven Anisotropic Adjustment of Optical Flow
Aug 19, 2022
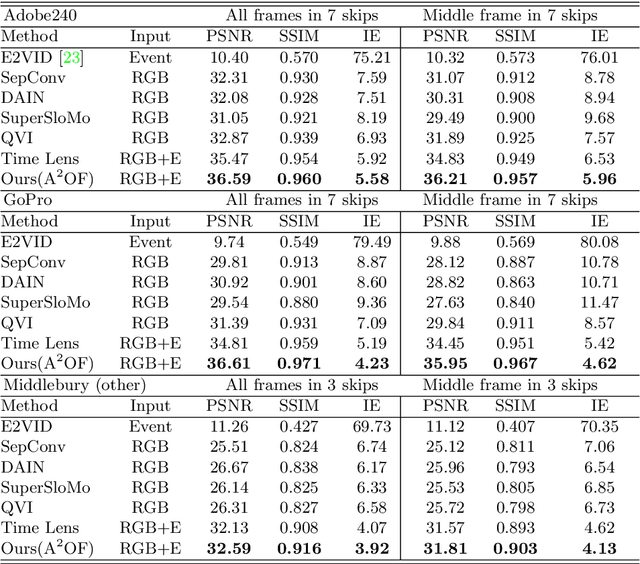
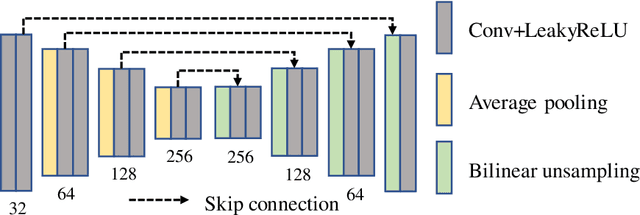
Video frame interpolation is a challenging task due to the ever-changing real-world scene. Previous methods often calculate the bi-directional optical flows and then predict the intermediate optical flows under the linear motion assumptions, leading to isotropic intermediate flow generation. Follow-up research obtained anisotropic adjustment through estimated higher-order motion information with extra frames. Based on the motion assumptions, their methods are hard to model the complicated motion in real scenes. In this paper, we propose an end-to-end training method A^2OF for video frame interpolation with event-driven Anisotropic Adjustment of Optical Flows. Specifically, we use events to generate optical flow distribution masks for the intermediate optical flow, which can model the complicated motion between two frames. Our proposed method outperforms the previous methods in video frame interpolation, taking supervised event-based video interpolation to a higher stage.
TimeReplayer: Unlocking the Potential of Event Cameras for Video Interpolation
Mar 25, 2022

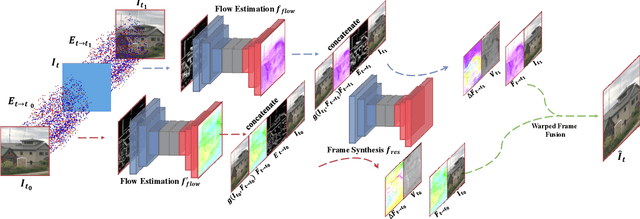
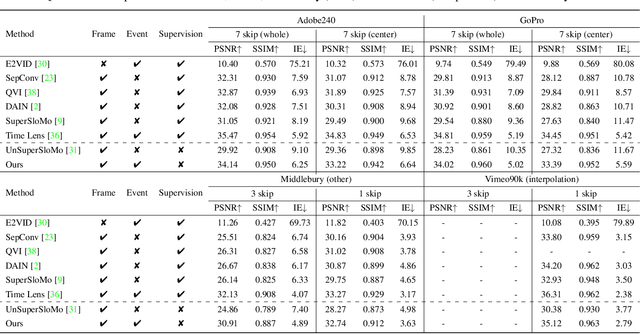
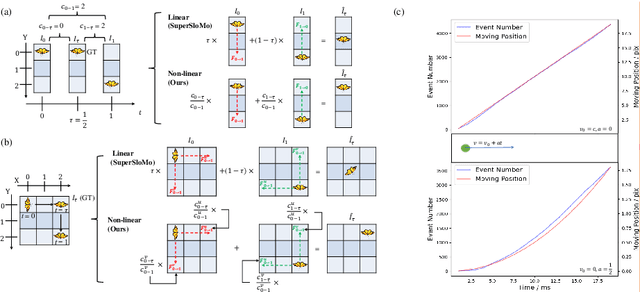
Recording fast motion in a high FPS (frame-per-second) requires expensive high-speed cameras. As an alternative, interpolating low-FPS videos from commodity cameras has attracted significant attention. If only low-FPS videos are available, motion assumptions (linear or quadratic) are necessary to infer intermediate frames, which fail to model complex motions. Event camera, a new camera with pixels producing events of brightness change at the temporal resolution of $\mu s$ $(10^{-6}$ second $)$, is a game-changing device to enable video interpolation at the presence of arbitrarily complex motion. Since event camera is a novel sensor, its potential has not been fulfilled due to the lack of processing algorithms. The pioneering work Time Lens introduced event cameras to video interpolation by designing optical devices to collect a large amount of paired training data of high-speed frames and events, which is too costly to scale. To fully unlock the potential of event cameras, this paper proposes a novel TimeReplayer algorithm to interpolate videos captured by commodity cameras with events. It is trained in an unsupervised cycle-consistent style, canceling the necessity of high-speed training data and bringing the additional ability of video extrapolation. Its state-of-the-art results and demo videos in supplementary reveal the promising future of event-based vision.
From Big to Small: Adaptive Learning to Partial-Set Domains
Mar 14, 2022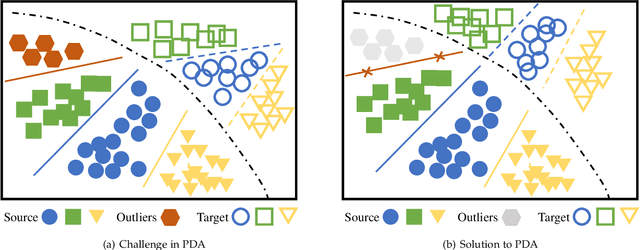

Domain adaptation targets at knowledge acquisition and dissemination from a labeled source domain to an unlabeled target domain under distribution shift. Still, the common requirement of identical class space shared across domains hinders applications of domain adaptation to partial-set domains. Recent advances show that deep pre-trained models of large scale endow rich knowledge to tackle diverse downstream tasks of small scale. Thus, there is a strong incentive to adapt models from large-scale domains to small-scale domains. This paper introduces Partial Domain Adaptation (PDA), a learning paradigm that relaxes the identical class space assumption to that the source class space subsumes the target class space. First, we present a theoretical analysis of partial domain adaptation, which uncovers the importance of estimating the transferable probability of each class and each instance across domains. Then, we propose Selective Adversarial Network (SAN and SAN++) with a bi-level selection strategy and an adversarial adaptation mechanism. The bi-level selection strategy up-weighs each class and each instance simultaneously for source supervised training, target self-training, and source-target adversarial adaptation through the transferable probability estimated alternately by the model. Experiments on standard partial-set datasets and more challenging tasks with superclasses show that SAN++ outperforms several domain adaptation methods.
Ranking and Tuning Pre-trained Models: A New Paradigm of Exploiting Model Hubs
Oct 20, 2021
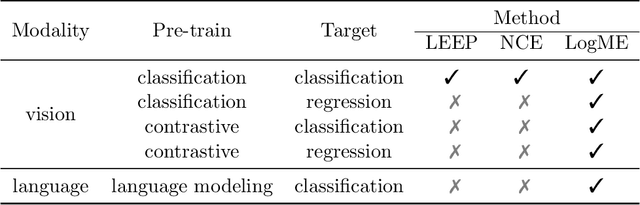
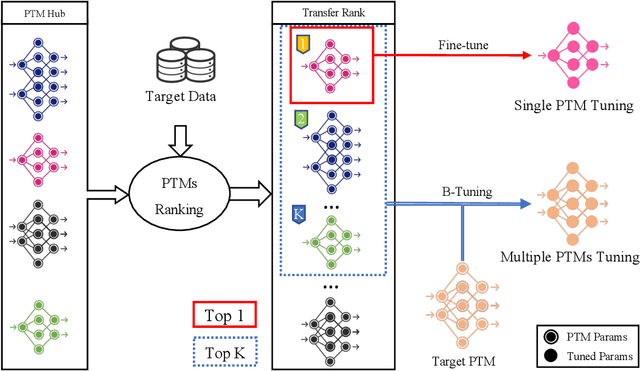
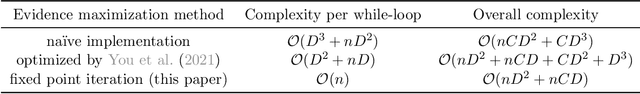
Pre-trained model hubs with many pre-trained models (PTMs) have been a cornerstone in deep learning. Although built at a high cost, they are in fact \emph{under-exploited}: practitioners usually pick one PTM from the provided model hub by popularity, and then fine-tune the PTM to solve the target task. This na\"ve but common practice poses two obstacles to sufficiently exploiting pre-trained model hubs: (1) the PTM selection procedure has no optimality guarantee; (2) only one PTM is used while the rest PTMs are overlooked. Ideally, to maximally exploit pre-trained model hubs, trying all combinations of PTMs and extensively fine-tuning each combination of PTMs are required, which incurs exponential combinations and unaffordable computational budget. In this paper, we propose a new paradigm of exploiting model hubs by ranking and tuning pre-trained models: (1) Our conference work~\citep{you_logme:_2021} proposed LogME to estimate the maximum value of label evidence given features extracted by pre-trained models, which can rank all the PTMs in a model hub for various types of PTMs and tasks \emph{before fine-tuning}. (2) the best ranked PTM can be fine-tuned and deployed if we have no preference for the model's architecture, or the target PTM can be tuned by top-K ranked PTMs via the proposed B-Tuning algorithm. The ranking part is based on the conference paper, and we complete its theoretical analysis (convergence proof of the heuristic evidence maximization procedure, and the influence of feature dimension) in this paper. The tuning part introduces a novel Bayesian Tuning (B-Tuning) method for multiple PTMs tuning, which surpasses dedicated methods designed for homogeneous PTMs tuning and sets up new state of the art for heterogeneous PTMs tuning. We believe the new paradigm of exploiting PTM hubs can interest a large audience of the community.
Tianshou: a Highly Modularized Deep Reinforcement Learning Library
Jul 29, 2021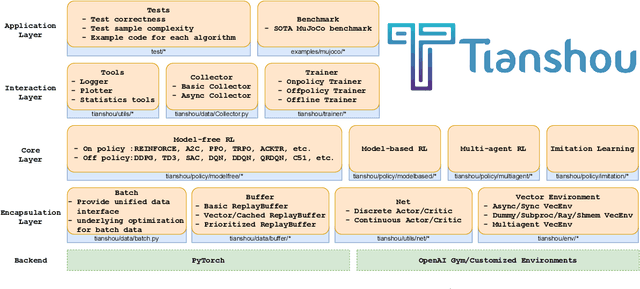

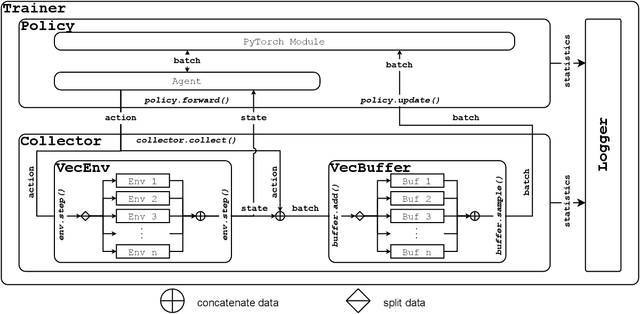

We present Tianshou, a highly modularized python library for deep reinforcement learning (DRL) that uses PyTorch as its backend. Tianshou aims to provide building blocks to replicate common RL experiments and has officially supported more than 15 classic algorithms succinctly. To facilitate related research and prove Tianshou's reliability, we release Tianshou's benchmark of MuJoCo environments, covering 9 classic algorithms and 9/13 Mujoco tasks with state-of-the-art performance. We open-sourced Tianshou at https://github.com/thu-ml/tianshou/, which has received over 3k stars and become one of the most popular PyTorch-based DRL libraries.
LogME: Practical Assessment of Pre-trained Models for Transfer Learning
Feb 22, 2021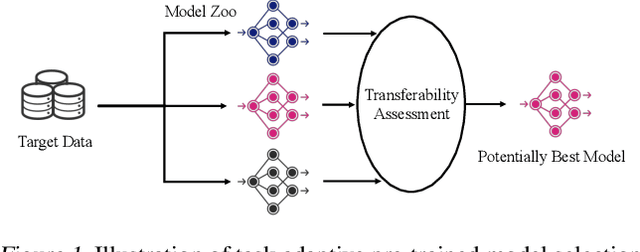
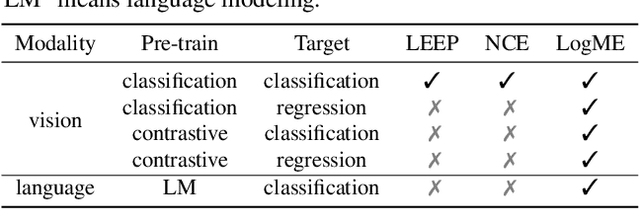
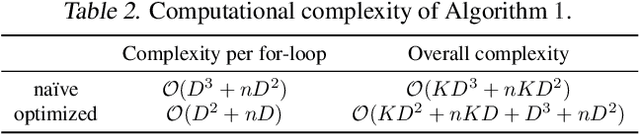
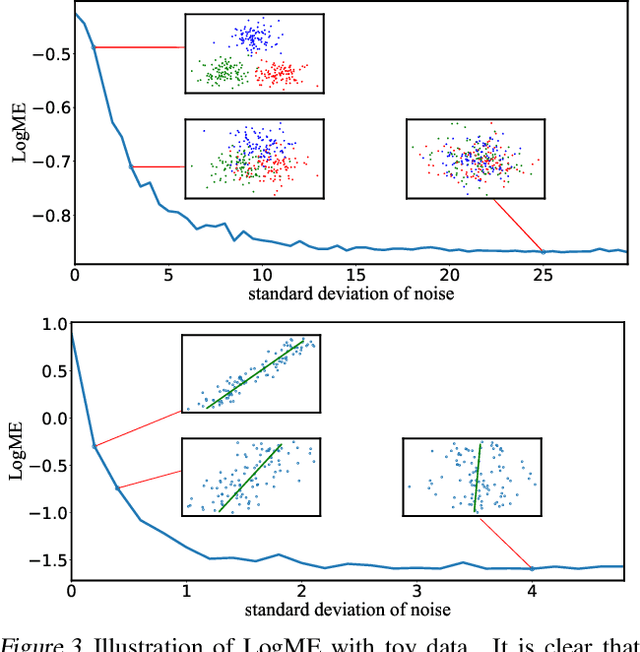
This paper studies task adaptive pre-trained model selection, an \emph{underexplored} problem of assessing pre-trained models so that models suitable for the task can be selected from the model zoo without fine-tuning. A pilot work~\cite{nguyen_leep:_2020} addressed the problem in transferring supervised pre-trained models to classification tasks, but it cannot handle emerging unsupervised pre-trained models or regression tasks. In pursuit of a practical assessment method, we propose to estimate the maximum evidence (marginalized likelihood) of labels given features extracted by pre-trained models. The maximum evidence is \emph{less prone to over-fitting} than the likelihood, and its \emph{expensive computation can be dramatically reduced} by our carefully designed algorithm. The Logarithm of Maximum Evidence (LogME) can be used to assess pre-trained models for transfer learning: a pre-trained model with high LogME is likely to have good transfer performance. LogME is fast, accurate, and general, characterizing it as \emph{the first practical assessment method for transfer learning}. Compared to brute-force fine-tuning, LogME brings over $3000\times$ speedup in wall-clock time. It outperforms prior methods by a large margin in their setting and is applicable to new settings that prior methods cannot deal with. It is general enough to diverse pre-trained models (supervised pre-trained and unsupervised pre-trained), downstream tasks (classification and regression), and modalities (vision and language). Code is at \url{https://github.com/thuml/LogME}.
Learning Stages: Phenomenon, Root Cause, Mechanism Hypothesis, and Implications
Aug 05, 2019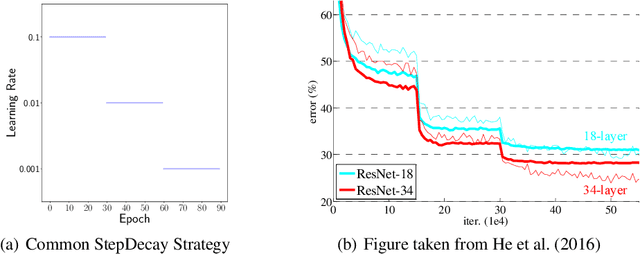
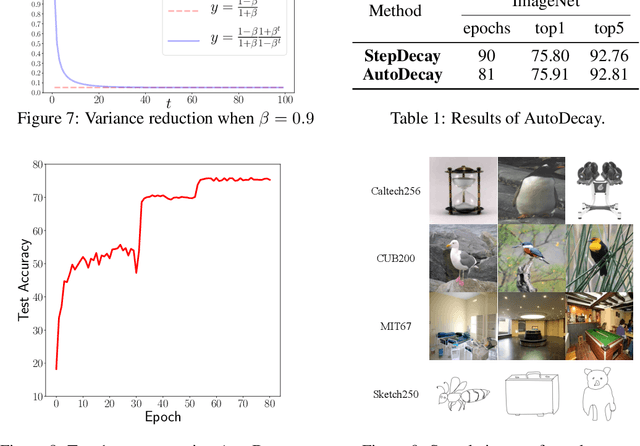
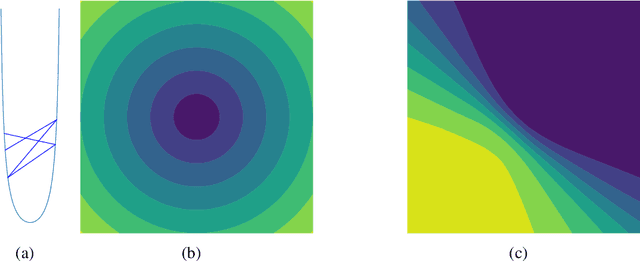

Under StepDecay learning rate strategy (decaying the learning rate after pre-defined epochs), it is a common phenomenon that the trajectories of learning statistics (training loss, test loss, test accuracy, etc.) are divided into several stages by sharp transitions. This paper studies the phenomenon in detail. Carefully designed experiments suggest the root cause to be the stochasticity of SGD. The convincing fact is the phenomenon disappears when Batch Gradient Descend is adopted. We then propose a hypothesis about the mechanism behind the phenomenon: the noise from SGD can be magnified to several levels by different learning rates, and only certain patterns are learnable within a certain level of noise. Patterns that can be learned under large noise are called easy patterns and patterns only learnable under small noise are called complex patterns. We derive several implications inspired by the hypothesis: (1) Since some patterns are not learnable until the next stage, we can design an algorithm to automatically detect the end of the current stage and switch to the next stage to expedite the training. The algorithm we design (called AutoDecay) shortens the time for training ResNet50 on ImageNet by $ 10 $\% without hurting the performance. (2) Since patterns are learned with increasing complexity, it is possible they have decreasing transferability. We study the transferability of models learned in different stages. Although later stage models have superior performance on ImageNet, we do find that they are less transferable. The verification of these two implications supports the hypothesis about the mechanism.