 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRA: Covariate-Aware Adaptation of Time Series Foundation Models
Oct 14, 2025Time Series Foundation Models (TSFMs) have shown significant impact through their model capacity, scalability, and zero-shot generalization. However, due to the heterogeneity of inter-variate dependencies and the backbone scalability on large-scale multivariate datasets, most TSFMs are typically pre-trained on univariate time series. This limitation renders them oblivious to crucial information from diverse covariates in real-world forecasting tasks. To further enhance the performance of TSFMs, we propose a general covariate-aware adaptation (CoRA) framework for TSFMs. It leverages pre-trained backbones of foundation models while effectively incorporating exogenous covariates from various modalities, including time series, language, and images, to improve the quality of predictions. Technically, CoRA maintains the equivalence of initialization and parameter consistency during adaptation. With preserved backbones of foundation models as frozen feature extractors, the outcome embeddings from foundation models are empirically demonstrated more informative than raw data. Further, CoRA employs a novel Granger Causality Embedding (GCE) to automatically evaluate covariates regarding their causal predictability with respect to the target variate. We incorporate these weighted embeddings with a zero-initialized condition-injection mechanism, avoiding catastrophic forgetting of pre-trained foundation models and gradually integrates exogenous information. Extensive experiments show that CoRA of TSFMs surpasses state-of-the-art covariate-aware deep forecasters with full or few-shot training samples, achieving 31.1% MSE reduction on covariate-aware forecasting. Compared to other adaptation methods, CoRA exhibits strong compatibility with various advanced TSFMs and extends the scope of covariates to other modalities, presenting a practical paradigm for the application of TSFMs.
Sundial: A Family of Highly Capable Time Series Foundation Models
Feb 02, 2025We introduce Sundial, a family of native, flexible, and scalable time series foundation models. To predict the next-patch's distribution, we propose a TimeFlow Loss based on flow-matching, which facilitates native pre-training of Transformers on time series without discrete tokenization. Conditioned on arbitrary-length time series, our model is pre-trained without specifying any prior distribution and can generate multiple probable predictions, achieving flexibility in representation learning beyond using parametric densities. Towards time series foundation models, we leverage minimal but crucial adaptations of Transformers and curate TimeBench with 1 trillion time points, comprising mostly real-world datasets and synthetic data. By mitigating mode collapse through TimeFlow Loss, we pre-train a family of Sundial models on TimeBench, which exhibit unprecedented model capacity and generalization performance on zero-shot forecasting. In addition to presenting good scaling behavior, Sundial achieves new state-of-the-art on both point forecasting and probabilistic forecasting benchmarks. We believe that Sundial's pioneering generative paradigm will facilitate a wide variety of forecasting scenarios.
Timer-XL: Long-Context Transformers for Unified Time Series Forecasting
Oct 07, 2024We present Timer-XL, a generative Transformer for unified time series forecasting. To uniformly predict 1D and 2D time series, we generalize next token prediction, predominantly adopted for causal generation of 1D sequences, to multivariate next token prediction. The proposed paradigm uniformly formulates various forecasting scenarios as a long-context generation problem. We opt for the generative Transformer, which can capture global-range and causal dependencies while providing contextual flexibility, to implement unified forecasting on univariate series characterized by non-stationarity, multivariate time series with complicated dynamics and correlations, and covariate-informed contexts that include both endogenous and exogenous variables. Technically, we propose a universal TimeAttention to facilitate generative Transformers on time series, which can effectively capture fine-grained intra- and inter-series dependencies of flattened time series tokens (patches) and is further strengthened by position embeddings in both temporal and variable dimensions. Timer-XL achieves state-of-the-art performance across challenging forecasting benchmarks through a unified approach. As a large time series model, it demonstrates notable model transferability by large-scale pre-training, as well as contextual flexibility in token lengths, positioning it as a one-for-all forecaster.
AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
Feb 04, 2024



Foundation models of time series have not been fully developed due to the limited availability of large-scale time series and the underexploration of scalable pre-training. Based on the similar sequential structure of time series and natural language, increasing research demonstrates the feasibility of leveraging large language models (LLM) for time series. Nevertheless, prior methods may overlook the consistency in aligning time series and natural language, resulting in insufficient utilization of the LLM potentials. To fully exploit the general-purpose token transitions learned from language modeling, we propose AutoTimes to repurpose LLMs as Autoregressive Time series forecasters, which is consistent with the acquisition and utilization of LLMs without updating the parameters. The consequent forecasters can handle flexible series lengths and achieve competitive performance as prevalent models. Further, we present token-wise prompting that utilizes corresponding timestamps to make our method applicable to multimodal scenarios. Analysis demonstrates our forecasters inherit zero-shot and in-context learning capabilities of LLMs. Empirically, AutoTimes exhibits notable method generality and achieves enhanced performance by basing on larger LLMs, additional texts, or time series as instructions.
Tune-Mode ConvBN Blocks For Efficient Transfer Learning
May 19, 2023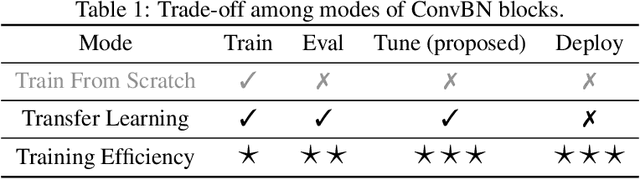

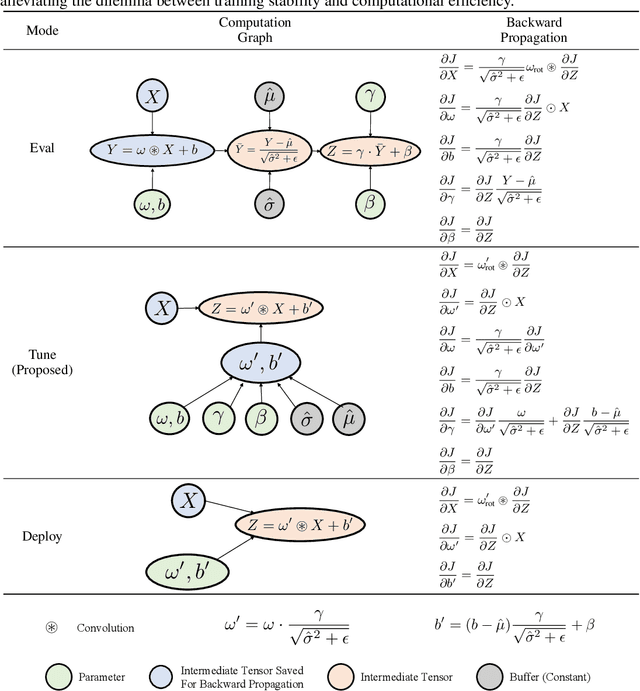

Convolution-BatchNorm (ConvBN) blocks are integral components in various computer vision tasks and other domains. A ConvBN block can operate in three modes: Train, Eval, and Deploy. While the Train mode is indispensable for training models from scratch, the Eval mode is suitable for transfer learning and model validation, and the Deploy mode is designed for the deployment of models. This paper focuses on the trade-off between stability and efficiency in ConvBN blocks: Deploy mode is efficient but suffers from training instability; Eval mode is widely used in transfer learning but lacks efficiency. To solve the dilemma, we theoretically reveal the reason behind the diminished training stability observed in the Deploy mode. Subsequently, we propose a novel Tune mode to bridge the gap between Eval mode and Deploy mode. The proposed Tune mode is as stable as Eval mode for transfer learning, and its computational efficiency closely matches that of the Deploy mode. Through extensive experiments in both object detection and classification tasks, carried out across various datasets and model architectures, we demonstrate that the proposed Tune mode does not hurt the original performance while significantly reducing GPU memory footprint and training time, thereby contributing an efficient solution to transfer learning with convolutional networks.