 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeteroCache: A Dynamic Retrieval Approach to Heterogeneous KV Cache Compression for Long-Context LLM Inference
Jan 20, 2026The linear memory growth of the KV cache poses a significant bottleneck for LLM inference in long-context tasks. Existing static compression methods often fail to preserve globally important information, principally because they overlook the attention drift phenomenon where token significance evolves dynamically. Although recent dynamic retrieval approaches attempt to address this issue, they typically suffer from coarse-grained caching strategies and incur high I/O overhead due to frequent data transfers. To overcome these limitations, we propose HeteroCache, a training-free dynamic compression framework. Our method is built on two key insights: attention heads exhibit diverse temporal heterogeneity, and there is significant spatial redundancy among heads within the same layer. Guided by these insights, HeteroCache categorizes heads based on stability and redundancy. Consequently, we apply a fine-grained weighting strategy that allocates larger cache budgets to heads with rapidly shifting attention to capture context changes, thereby addressing the inefficiency of coarse-grained strategies. Furthermore, we employ a hierarchical storage mechanism in which a subset of representative heads monitors attention shift, and trigger an asynchronous, on-demand retrieval of contexts from the CPU, effectively hiding I/O latency. Finally, experiments demonstrate that HeteroCache achieves state-of-the-art performance on multiple long-context benchmarks and accelerates decoding by up to $3\times$ compared to the original model in the 224K context. Our code will be open-source.
CoRA: Covariate-Aware Adaptation of Time Series Foundation Models
Oct 14, 2025Time Series Foundation Models (TSFMs) have shown significant impact through their model capacity, scalability, and zero-shot generalization. However, due to the heterogeneity of inter-variate dependencies and the backbone scalability on large-scale multivariate datasets, most TSFMs are typically pre-trained on univariate time series. This limitation renders them oblivious to crucial information from diverse covariates in real-world forecasting tasks. To further enhance the performance of TSFMs, we propose a general covariate-aware adaptation (CoRA) framework for TSFMs. It leverages pre-trained backbones of foundation models while effectively incorporating exogenous covariates from various modalities, including time series, language, and images, to improve the quality of predictions. Technically, CoRA maintains the equivalence of initialization and parameter consistency during adaptation. With preserved backbones of foundation models as frozen feature extractors, the outcome embeddings from foundation models are empirically demonstrated more informative than raw data. Further, CoRA employs a novel Granger Causality Embedding (GCE) to automatically evaluate covariates regarding their causal predictability with respect to the target variate. We incorporate these weighted embeddings with a zero-initialized condition-injection mechanism, avoiding catastrophic forgetting of pre-trained foundation models and gradually integrates exogenous information. Extensive experiments show that CoRA of TSFMs surpasses state-of-the-art covariate-aware deep forecasters with full or few-shot training samples, achieving 31.1% MSE reduction on covariate-aware forecasting. Compared to other adaptation methods, CoRA exhibits strong compatibility with various advanced TSFMs and extends the scope of covariates to other modalities, presenting a practical paradigm for the application of TSFMs.
Sundial: A Family of Highly Capable Time Series Foundation Models
Feb 02, 2025We introduce Sundial, a family of native, flexible, and scalable time series foundation models. To predict the next-patch's distribution, we propose a TimeFlow Loss based on flow-matching, which facilitates native pre-training of Transformers on time series without discrete tokenization. Conditioned on arbitrary-length time series, our model is pre-trained without specifying any prior distribution and can generate multiple probable predictions, achieving flexibility in representation learning beyond using parametric densities. Towards time series foundation models, we leverage minimal but crucial adaptations of Transformers and curate TimeBench with 1 trillion time points, comprising mostly real-world datasets and synthetic data. By mitigating mode collapse through TimeFlow Loss, we pre-train a family of Sundial models on TimeBench, which exhibit unprecedented model capacity and generalization performance on zero-shot forecasting. In addition to presenting good scaling behavior, Sundial achieves new state-of-the-art on both point forecasting and probabilistic forecasting benchmarks. We believe that Sundial's pioneering generative paradigm will facilitate a wide variety of forecasting scenarios.
WiFi-based Spatiotemporal Human Action Perception
Jun 20, 2022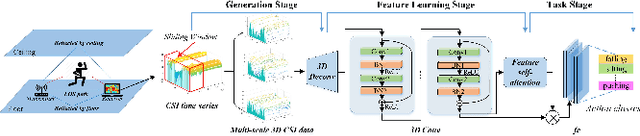
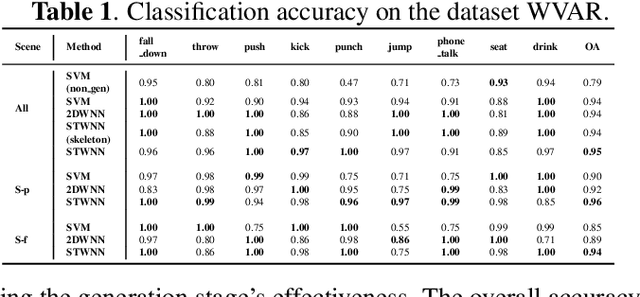
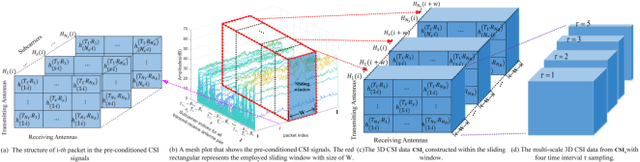
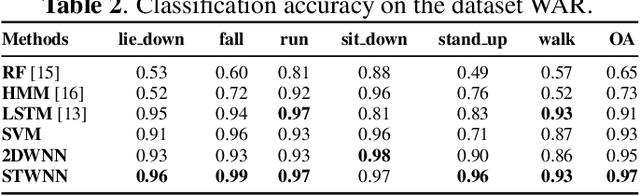
WiFi-based sensing for human activity recognition (HAR) has recently become a hot topic as it brings great benefits when compared with video-based HAR, such as eliminating the demands of line-of-sight (LOS) and preserving privacy. Making the WiFi signals to 'see' the action, however, is quite coarse and thus still in its infancy. An end-to-end spatiotemporal WiFi signal neural network (STWNN) is proposed to enable WiFi-only sensing in both line-of-sight and non-line-of-sight scenarios. Especially, the 3D convolution module is able to explore the spatiotemporal continuity of WiFi signals, and the feature self-attention module can explicitly maintain dominant features. In addition, a novel 3D representation for WiFi signals is designed to preserve multi-scale spatiotemporal information. Furthermore, a small wireless-vision dataset (WVAR) is synchronously collected to extend the potential of STWNN to 'see' through occlusions. Quantitative and qualitative results on WVAR and the other three public benchmark datasets demonstrate the effectiveness of our approach on both accuracy and shift consistency.
A Wireless-Vision Dataset for Privacy Preserving Human Activity Recognition
May 24, 2022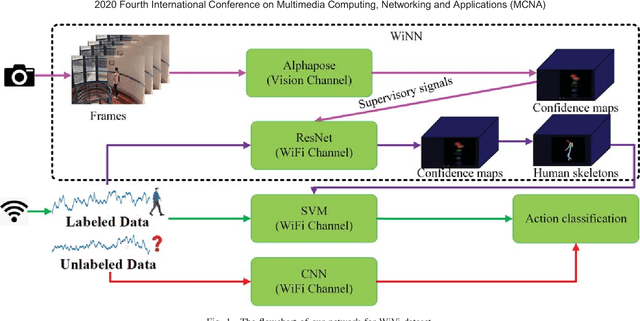

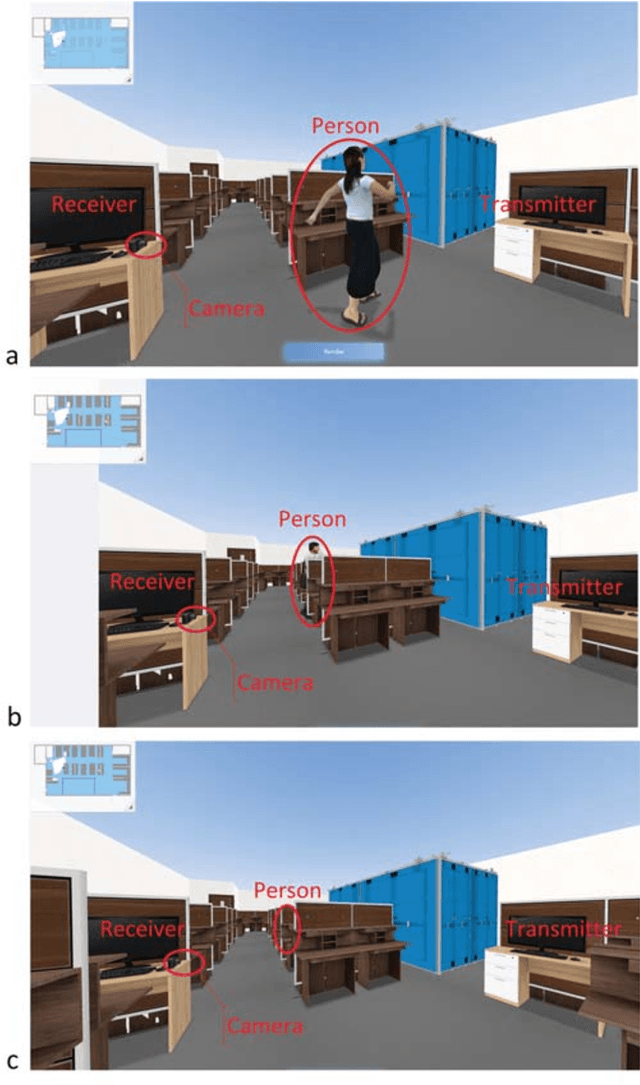
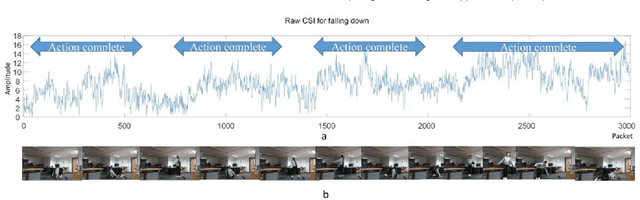
Human Activity Recognition (HAR) has recently received remarkable attention in numerous applications such as assisted living and remote monitoring. Existing solutions based on sensors and vision technologies have obtained achievements but still suffering from considerable limitations in the environmental requirement. Wireless signals like WiFi-based sensing have emerged as a new paradigm since it is convenient and not restricted in the environment. In this paper, a new WiFi-based and video-based neural network (WiNN) is proposed to improve the robustness of activity recognition where the synchronized video serves as the supplement for the wireless data. Moreover, a wireless-vision benchmark (WiVi) is collected for 9 class actions recognition in three different visual conditions, including the scenes without occlusion, with partial occlusion, and with full occlusion. Both machine learning methods - support vector machine (SVM) as well as deep learning methods are used for the accuracy verification of the data set. Our results show that WiVi data set satisfies the primary demand and all three branches in the proposed pipeline keep more than $80\%$ of activity recognition accuracy over multiple action segmentation from 1s to 3s. In particular, WiNN is the most robust method in terms of all the actions on three action segmentation compared to the others.
GraSens: A Gabor Residual Anti-aliasing Sensing Framework for Action Recognition using WiFi
May 24, 2022
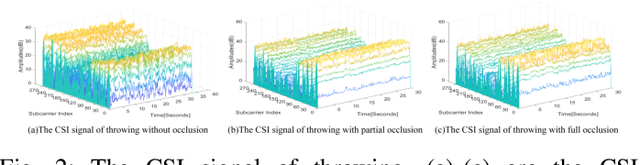


WiFi-based human action recognition (HAR) has been regarded as a promising solution in applications such as smart living and remote monitoring due to the pervasive and unobtrusive nature of WiFi signals. However, the efficacy of WiFi signals is prone to be influenced by the change in the ambient environment and varies over different sub-carriers. To remedy this issue, we propose an end-to-end Gabor residual anti-aliasing sensing network (GraSens) to directly recognize the actions using the WiFi signals from the wireless devices in diverse scenarios. In particular, a new Gabor residual block is designed to address the impact of the changing surrounding environment with a focus on learning reliable and robust temporal-frequency representations of WiFi signals. In each block, the Gabor layer is integrated with the anti-aliasing layer in a residual manner to gain the shift-invariant features. Furthermore, fractal temporal and frequency self-attention are proposed in a joint effort to explicitly concentrate on the efficacy of WiFi signals and thus enhance the quality of output features scattered in different subcarriers. Experimental results throughout our wireless-vision action recognition dataset (WVAR) and three public datasets demonstrate that our proposed GraSens scheme outperforms state-of-the-art methods with respect to recognition accuracy.
Weakly Supervised Image Annotation and Segmentation with Objects and Attributes
Aug 08, 2017
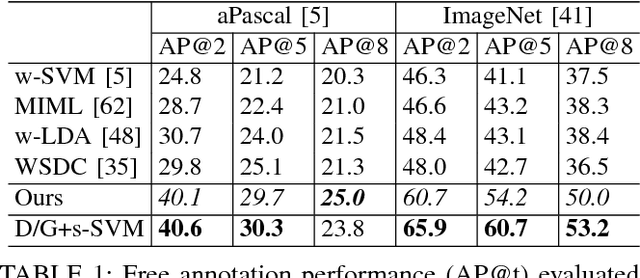

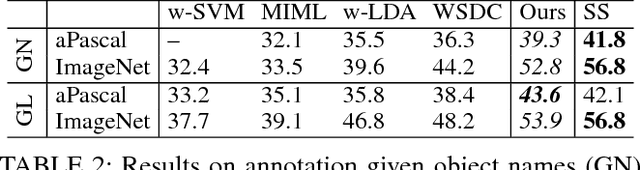
We propose to model complex visual scenes using a non-parametric Bayesian model learned from weakly labelled images abundant on media sharing sites such as Flickr. Given weak image-level annotations of objects and attributes without locations or associations between them, our model aims to learn the appearance of object and attribute classes as well as their association on each object instance. Once learned, given an image, our model can be deployed to tackle a number of vision problems in a joint and coherent manner, including recognising objects in the scene (automatic object annotation), describing objects using their attributes (attribute prediction and association), and localising and delineating the objects (object detection and semantic segmentation). This is achieved by developing a novel Weakly Supervised Markov Random Field Stacked Indian Buffet Process (WS-MRF-SIBP) that models objects and attributes as latent factors and explicitly captures their correlations within and across superpixels. Extensive experiments on benchmark datasets demonstrate that our weakly supervised model significantly outperforms weakly supervised alternatives and is often comparable with existing strongly supervised models on a variety of tasks including semantic segmentation, automatic image annotation and retrieval based on object-attribute associations.
Learning and Refining of Privileged Information-based RNNs for Action Recognition from Depth Sequences
Aug 08, 2017
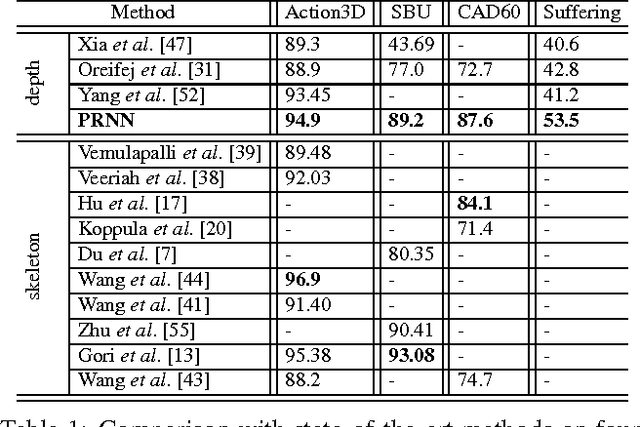

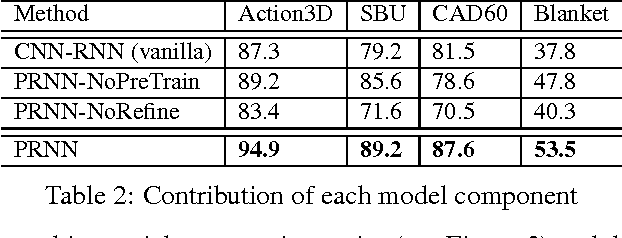
Existing RNN-based approaches for action recognition from depth sequences require either skeleton joints or hand-crafted depth features as inputs. An end-to-end manner, mapping from raw depth maps to action classes, is non-trivial to design due to the fact that: 1) single channel map lacks texture thus weakens the discriminative power; 2) relatively small set of depth training data. To address these challenges, we propose to learn an RNN driven by privileged information (PI) in three-steps: An encoder is pre-trained to learn a joint embedding of depth appearance and PI (i.e. skeleton joints). The learned embedding layers are then tuned in the learning step, aiming to optimize the network by exploiting PI in a form of multi-task loss. However, exploiting PI as a secondary task provides little help to improve the performance of a primary task (i.e. classification) due to the gap between them. Finally, a bridging matrix is defined to connect two tasks by discovering latent PI in the refining step. Our PI-based classification loss maintains a consistency between latent PI and predicted distribution. The latent PI and network are iteratively estimated and updated in an expectation-maximization procedure. The proposed learning process provides greater discriminative power to model subtle depth difference, while helping avoid overfitting the scarcer training data. Our experiments show significant performance gains over state-of-the-art methods on three public benchmark datasets and our newly collected Blanket dataset.
Bayesian Joint Modelling for Object Localisation in Weakly Labelled Images
Jun 19, 2017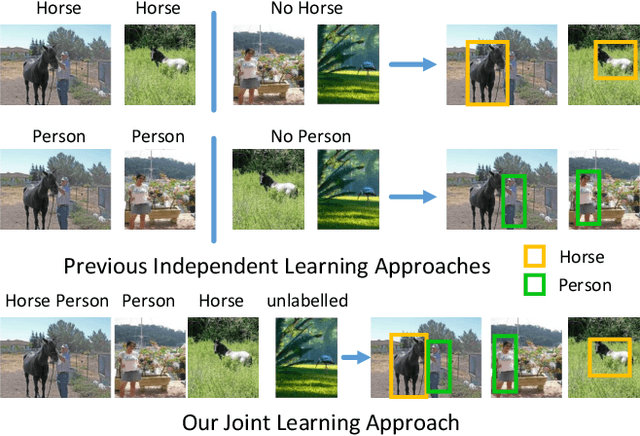


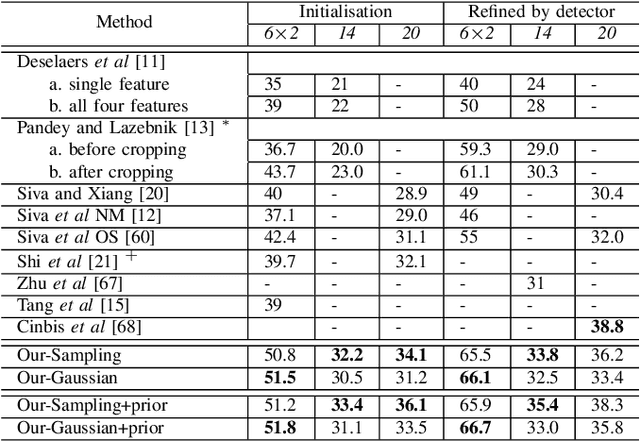
We address the problem of localisation of objects as bounding boxes in images and videos with weak labels. This weakly supervised object localisation problem has been tackled in the past using discriminative models where each object class is localised independently from other classes. In this paper, a novel framework based on Bayesian joint topic modelling is proposed, which differs significantly from the existing ones in that: (1) All foreground object classes are modelled jointly in a single generative model that encodes multiple object co-existence so that "explaining away" inference can resolve ambiguity and lead to better learning and localisation. (2) Image backgrounds are shared across classes to better learn varying surroundings and "push out" objects of interest. (3) Our model can be learned with a mixture of weakly labelled and unlabelled data, allowing the large volume of unlabelled images on the Internet to be exploited for learning. Moreover, the Bayesian formulation enables the exploitation of various types of prior knowledge to compensate for the limited supervision offered by weakly labelled data, as well as Bayesian domain adaptation for transfer learning. Extensive experiments on the PASCAL VOC, ImageNet and YouTube-Object videos datasets demonstrate the effectiveness of our Bayesian joint model for weakly supervised object localisation.
Transferring a Semantic Representation for Person Re-Identification and Search
Jun 12, 2017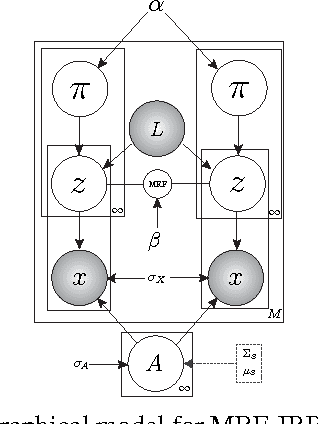

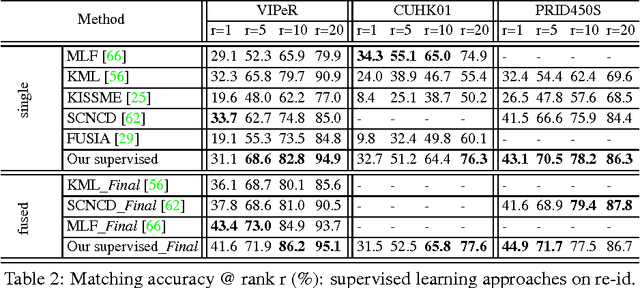

Learning semantic attributes for person re-identification and description-based person search has gained increasing interest due to attributes' great potential as a pose and view-invariant representation. However, existing attribute-centric approaches have thus far underperformed state-of-the-art conventional approaches. This is due to their non-scalable need for extensive domain (camera) specific annotation. In this paper we present a new semantic attribute learning approach for person re-identification and search. Our model is trained on existing fashion photography datasets -- either weakly or strongly labelled. It can then be transferred and adapted to provide a powerful semantic description of surveillance person detections, without requiring any surveillance domain supervision. The resulting representation is useful for both unsupervised and supervised person re-identification, achieving state-of-the-art and near state-of-the-art performance respectively. Furthermore, as a semantic representation it allows description-based person search to be integrated within the same framework.