 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset for Real-World Human Action Detection Using FMCW mmWave Radar
Dec 23, 2024Human action detection using privacy-preserving mmWave radar sensors is studied for its applications in healthcare and home automation. Unlike existing research, limited to simulations in controlled environments, we present a real-world mmWave radar dataset with baseline results for human action detection.
Step length measurement in the wild using FMCW radar
Jan 03, 2024With an aging population, numerous assistive and monitoring technologies are under development to enable older adults to age in place. To facilitate aging in place predicting risk factors such as falls, and hospitalization and providing early interventions are important. Much of the work on ambient monitoring for risk prediction has centered on gait speed analysis, utilizing privacy-preserving sensors like radar. Despite compelling evidence that monitoring step length, in addition to gait speed, is crucial for predicting risk, radar-based methods have not explored step length measurement in the home. Furthermore, laboratory experiments on step length measurement using radars are limited to proof of concept studies with few healthy subjects. To address this gap, a radar-based step length measurement system for the home is proposed based on detection and tracking using radar point cloud, followed by Doppler speed profiling of the torso to obtain step lengths in the home. The proposed method was evaluated in a clinical environment, involving 35 frail older adults, to establish its validity. Additionally, the method was assessed in people's homes, with 21 frail older adults who had participated in the clinical assessment. The proposed radar-based step length measurement method was compared to the gold standard Zeno Walkway Gait Analysis System, revealing a 4.5cm/8.3% error in a clinical setting. Furthermore, it exhibited excellent reliability (ICC(2,k)=0.91, 95% CI 0.82 to 0.96) in uncontrolled home settings. The method also proved accurate in uncontrolled home settings, as indicated by a strong agreement (ICC(3,k)=0.81 (95% CI 0.53 to 0.92)) between home measurements and in-clinic assessments.
Unsupervised Domain Adaptation in Person re-ID via k-Reciprocal Clustering and Large-Scale Heterogeneous Environment Synthesis
Jan 14, 2020
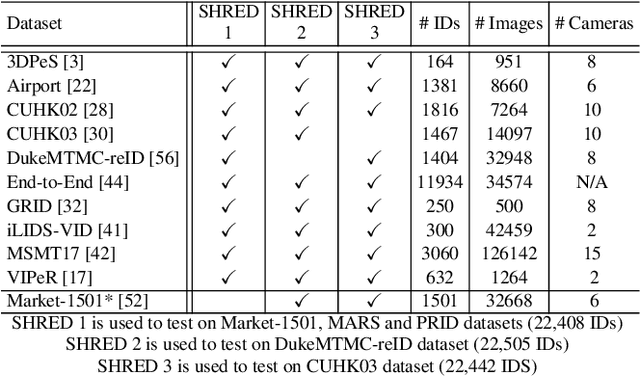
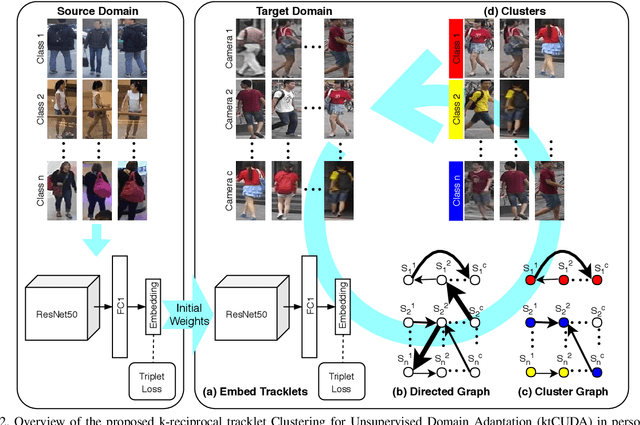
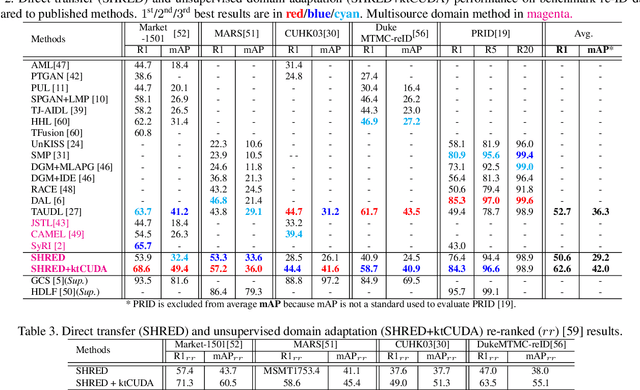
An ongoing major challenge in computer vision is the task of person re-identification, where the goal is to match individuals across different, non-overlapping camera views. While recent success has been achieved via supervised learning using deep neural networks, such methods have limited widespread adoption due to the need for large-scale, customized data annotation. As such, there has been a recent focus on unsupervised learning approaches to mitigate the data annotation issue; however, current approaches in literature have limited performance compared to supervised learning approaches as well as limited applicability for adoption in new environments. In this paper, we address the aforementioned challenges faced in person re-identification for real-world, practical scenarios by introducing a novel, unsupervised domain adaptation approach for person re-identification. This is accomplished through the introduction of: i) k-reciprocal tracklet Clustering for Unsupervised Domain Adaptation (ktCUDA) (for pseudo-label generation on target domain), and ii) Synthesized Heterogeneous RE-id Domain (SHRED) composed of large-scale heterogeneous independent source environments (for improving robustness and adaptability to a wide diversity of target environments). Experimental results across four different image and video benchmark datasets show that the proposed ktCUDA and SHRED approach achieves an average improvement of +5.7 mAP in re-identification performance when compared to existing state-of-the-art methods, as well as demonstrate better adaptability to different types of environments.
Fairest of Them All: Establishing a Strong Baseline for Cross-Domain Person ReID
Jul 28, 2019
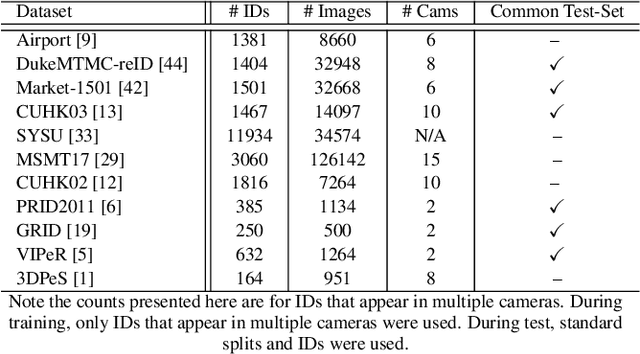

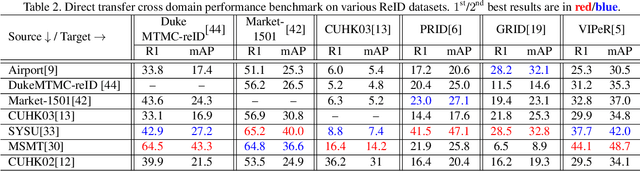
Person re-identification (ReID) remains a very difficult challenge in computer vision, and critical for large-scale video surveillance scenarios where an individual could appear in different camera views at different times. There has been recent interest in tackling this challenge using cross-domain approaches, which leverages data from source domains that are different than the target domain. Such approaches are more practical for real-world widespread deployment given that they don't require on-site training (as with unsupervised or domain transfer approaches) or on-site manual annotation and training (as with supervised approaches). In this study, we take a systematic approach to establishing a large baseline source domain and target domain for cross-domain person ReID. We accomplish this by conducting a comprehensive analysis to study the similarities between source domains proposed in literature, and studying the effects of incrementally increasing the size of the source domain. This allows us to establish a balanced source domain and target domain split that promotes variety in both source and target domains. Furthermore, using lessons learned from the state-of-the-art supervised person re-identification methods, we establish a strong baseline method for cross-domain person ReID. Experiments show that a source domain composed of two of the largest person ReID domains (SYSU and MSMT) performs well across six commonly-used target domains. Furthermore, we show that, surprisingly, two of the recent commonly-used domains (PRID and GRID) have too few query images to provide meaningful insights. As such, based on our findings, we propose the following balanced baseline for cross-domain person ReID consisting of: i) a fixed multi-source domain consisting of SYSU, MSMT, Airport and 3DPeS, and ii) a multi-target domain consisting of Market-1501, DukeMTMC-reID, CUHK03, PRID, GRID and VIPeR.
A Survey of Pruning Methods for Efficient Person Re-identification Across Domains
Jul 04, 2019
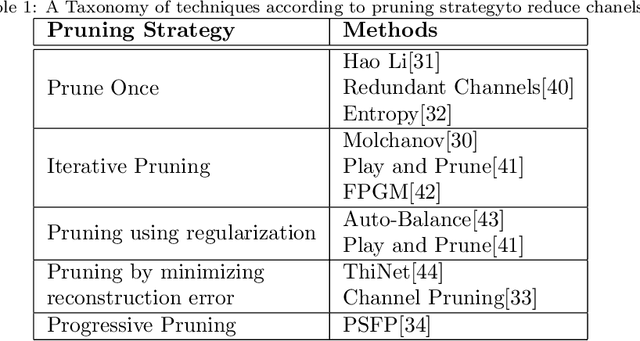
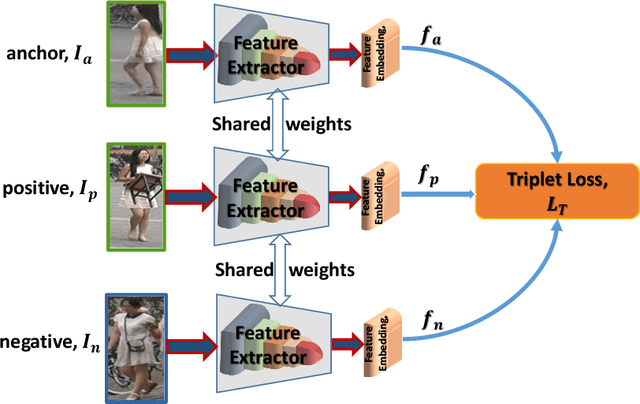
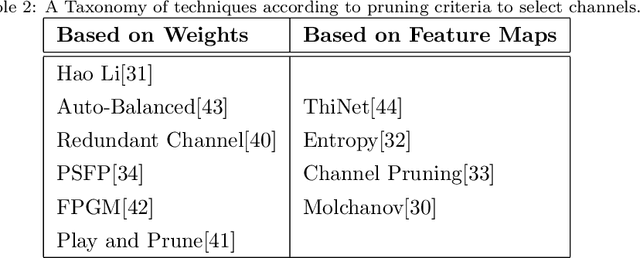
Recent years have witnessed a substantial increase in the deep learning architectures proposed for visual recognition tasks like person re-identification, where individuals must be recognized over multiple distributed cameras. Although deep Siamese networks have greatly improved the state-of-the-art accuracy, the computational complexity of the CNNs used for feature extraction remains an issue, hindering their deployment on platforms with with limited resources, or in applications with real-time constraints. Thus, there is an obvious advantage to compressing these architectures without significantly decreasing their accuracy. This paper provides a survey of state-of-the-art pruning techniques that are suitable for compressing deep Siamese networks applied to person re-identification. These techniques are analysed according to their pruning criteria and strategy, and according to different design scenarios for exploiting pruning methods to fine-tuning networks for target applications. Experimental results obtained using Siamese networks with ResNet feature extractors, and multiple benchmarks re-identification datasets, indicate that pruning can considerably reduce network complexity while maintaining a high level of accuracy. In scenarios where pruning is performed with large pre-training or fine-tuning datasets, the number of FLOPS required by the ResNet feature extractor is reduced by half, while maintaining a comparable rank-1 accuracy (within 1\% of the original model). Pruning while training a larger CNNs can also provide a significantly better performance than fine-tuning smaller ones.
An Evaluation of Deep CNN Baselines for Scene-Independent Person Re-Identification
May 16, 2018
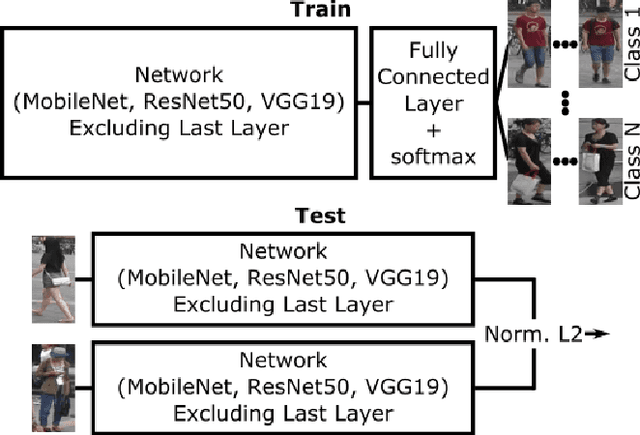

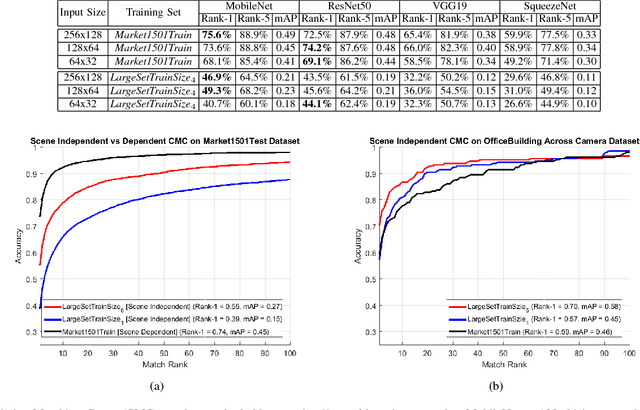
In recent years, a variety of proposed methods based on deep convolutional neural networks (CNNs) have improved the state of the art for large-scale person re-identification (ReID). While a large number of optimizations and network improvements have been proposed, there has been relatively little evaluation of the influence of training data and baseline network architecture. In particular, it is usually assumed either that networks are trained on labeled data from the deployment location (scene-dependent), or else adapted with unlabeled data, both of which complicate system deployment. In this paper, we investigate the feasibility of achieving scene-independent person ReID by forming a large composite dataset for training. We present an in-depth comparison of several CNN baseline architectures for both scene-dependent and scene-independent ReID, across a range of training dataset sizes. We show that scene-independent ReID can produce leading-edge results, competitive with unsupervised domain adaption techniques. Finally, we introduce a new dataset for comparing within-camera and across-camera person ReID.
Transfer Learning by Ranking for Weakly Supervised Object Annotation
May 02, 2017Most existing approaches to training object detectors rely on fully supervised learning, which requires the tedious manual annotation of object location in a training set. Recently there has been an increasing interest in developing weakly supervised approach to detector training where the object location is not manually annotated but automatically determined based on binary (weak) labels indicating if a training image contains the object. This is a challenging problem because each image can contain many candidate object locations which partially overlaps the object of interest. Existing approaches focus on how to best utilise the binary labels for object location annotation. In this paper we propose to solve this problem from a very different perspective by casting it as a transfer learning problem. Specifically, we formulate a novel transfer learning based on learning to rank, which effectively transfers a model for automatic annotation of object location from an auxiliary dataset to a target dataset with completely unrelated object categories. We show that our approach outperforms existing state-of-the-art weakly supervised approach to annotating objects in the challenging VOC dataset.
Scene Invariant Crowd Segmentation and Counting Using Scale-Normalized Histogram of Moving Gradients (HoMG)
Feb 01, 2016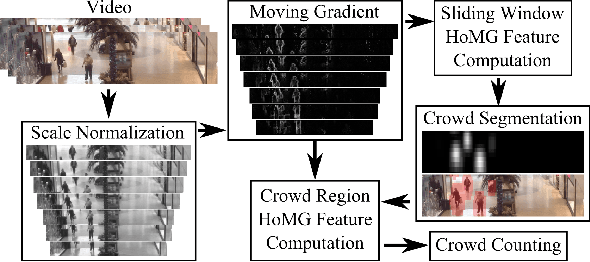
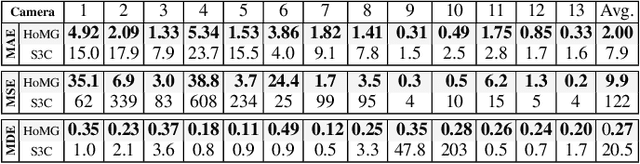

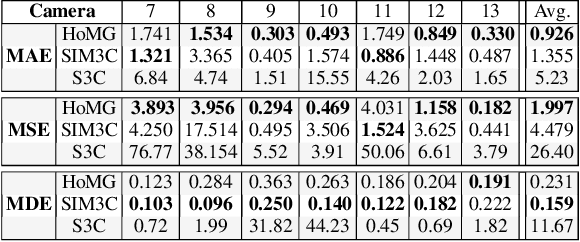
The problem of automated crowd segmentation and counting has garnered significant interest in the field of video surveillance. This paper proposes a novel scene invariant crowd segmentation and counting algorithm designed with high accuracy yet low computational complexity in mind, which is key for widespread industrial adoption. A novel low-complexity, scale-normalized feature called Histogram of Moving Gradients (HoMG) is introduced for highly effective spatiotemporal representation of individuals and crowds within a video. Real-time crowd segmentation is achieved via boosted cascade of weak classifiers based on sliding-window HoMG features, while linear SVM regression of crowd-region HoMG features is employed for real-time crowd counting. Experimental results using multi-camera crowd datasets show that the proposed algorithm significantly outperform state-of-the-art crowd counting algorithms, as well as achieve very promising crowd segmentation results, thus demonstrating the efficacy of the proposed method for highly-accurate, real-time video-driven crowd analysis.
Domain Adaptation and Transfer Learning in StochasticNets
Dec 18, 2015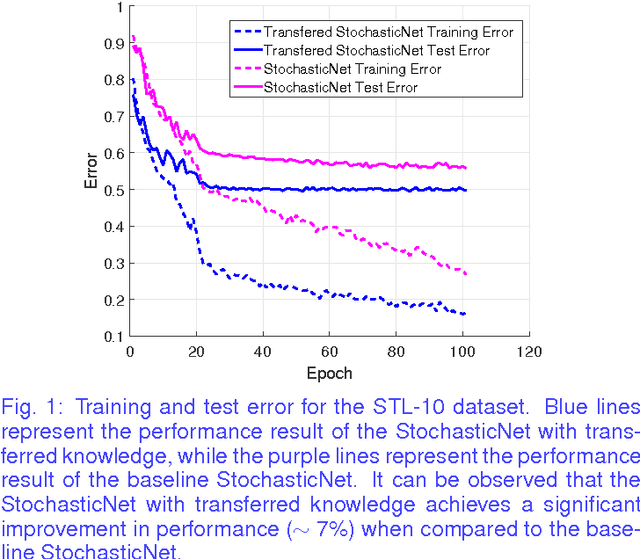
Transfer learning is a recent field of machine learning research that aims to resolve the challenge of dealing with insufficient training data in the domain of interest. This is a particular issue with traditional deep neural networks where a large amount of training data is needed. Recently, StochasticNets was proposed to take advantage of sparse connectivity in order to decrease the number of parameters that needs to be learned, which in turn may relax training data size requirements. In this paper, we study the efficacy of transfer learning on StochasticNet frameworks. Experimental results show ~7% improvement on StochasticNet performance when the transfer learning is applied in training step.
Efficient Deep Feature Learning and Extraction via StochasticNets
Dec 11, 2015

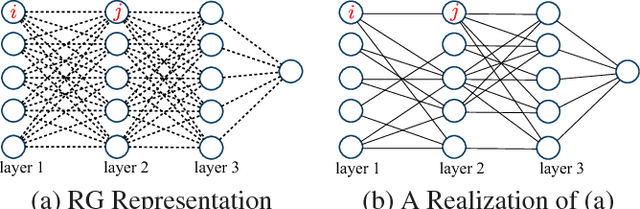
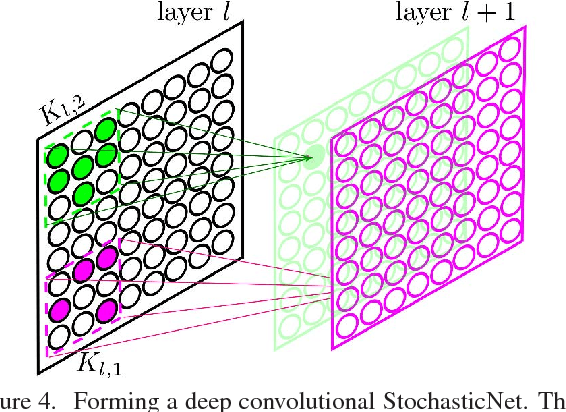
Deep neural networks are a powerful tool for feature learning and extraction given their ability to model high-level abstractions in highly complex data. One area worth exploring in feature learning and extraction using deep neural networks is efficient neural connectivity formation for faster feature learning and extraction. Motivated by findings of stochastic synaptic connectivity formation in the brain as well as the brain's uncanny ability to efficiently represent information, we propose the efficient learning and extraction of features via StochasticNets, where sparsely-connected deep neural networks can be formed via stochastic connectivity between neurons. To evaluate the feasibility of such a deep neural network architecture for feature learning and extraction, we train deep convolutional StochasticNets to learn abstract features using the CIFAR-10 dataset, and extract the learned features from images to perform classification on the SVHN and STL-10 datasets. Experimental results show that features learned using deep convolutional StochasticNets, with fewer neural connections than conventional deep convolutional neural networks, can allow for better or comparable classification accuracy than conventional deep neural networks: relative test error decrease of ~4.5% for classification on the STL-10 dataset and ~1% for classification on the SVHN dataset. Furthermore, it was shown that the deep features extracted using deep convolutional StochasticNets can provide comparable classification accuracy even when only 10% of the training data is used for feature learning. Finally, it was also shown that significant gains in feature extraction speed can be achieved in embedded applications using StochasticNets. As such, StochasticNets allow for faster feature learning and extraction performance while facilitate for better or comparable accuracy performances.