 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Multi-Target Domain Adaptation in Real-Time Person Re-Identification
May 12, 2022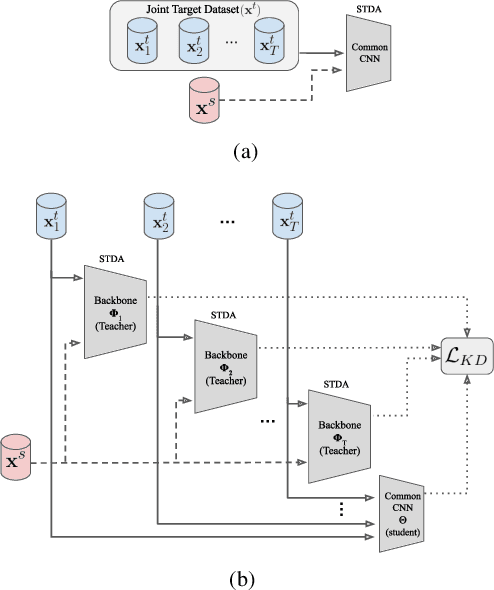
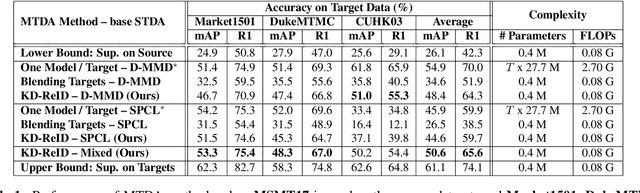
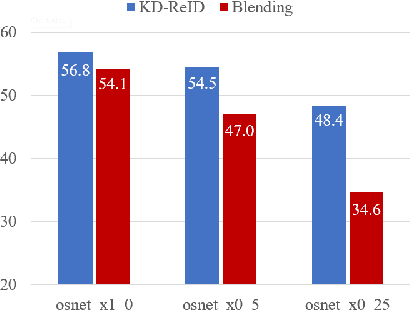
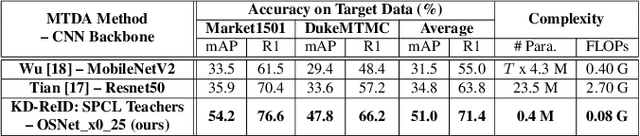
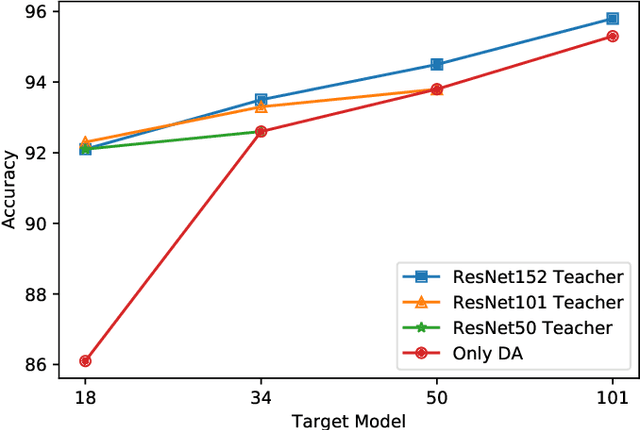
Despite the recent success of deep learning architectures, person re-identification (ReID) remains a challenging problem in real-word applications. Several unsupervised single-target domain adaptation (STDA) methods have recently been proposed to limit the decline in ReID accuracy caused by the domain shift that typically occurs between source and target video data. Given the multimodal nature of person ReID data (due to variations across camera viewpoints and capture conditions), training a common CNN backbone to address domain shifts across multiple target domains, can provide an efficient solution for real-time ReID applications. Although multi-target domain adaptation (MTDA) has not been widely addressed in the ReID literature, a straightforward approach consists in blending different target datasets, and performing STDA on the mixture to train a common CNN. However, this approach may lead to poor generalization, especially when blending a growing number of distinct target domains to train a smaller CNN. To alleviate this problem, we introduce a new MTDA method based on knowledge distillation (KD-ReID) that is suitable for real-time person ReID applications. Our method adapts a common lightweight student backbone CNN over the target domains by alternatively distilling from multiple specialized teacher CNNs, each one adapted on data from a specific target domain. Extensive experiments conducted on several challenging person ReID datasets indicate that our approach outperforms state-of-art methods for MTDA, including blending methods, particularly when training a compact CNN backbone like OSNet. Results suggest that our flexible MTDA approach can be employed to design cost-effective ReID systems for real-time video surveillance applications.
Dynamic Template Selection Through Change Detection for Adaptive Siamese Tracking
Mar 07, 2022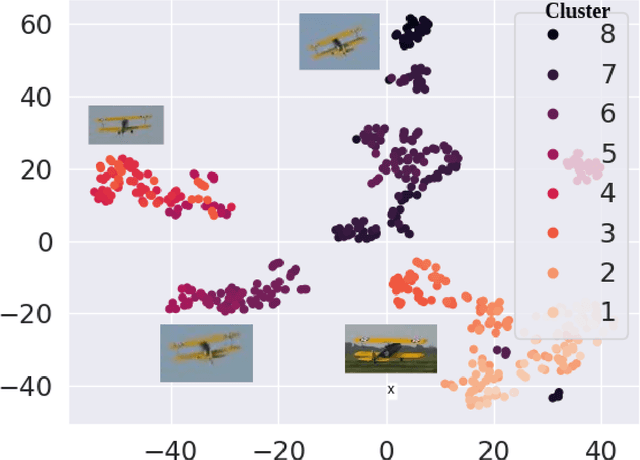

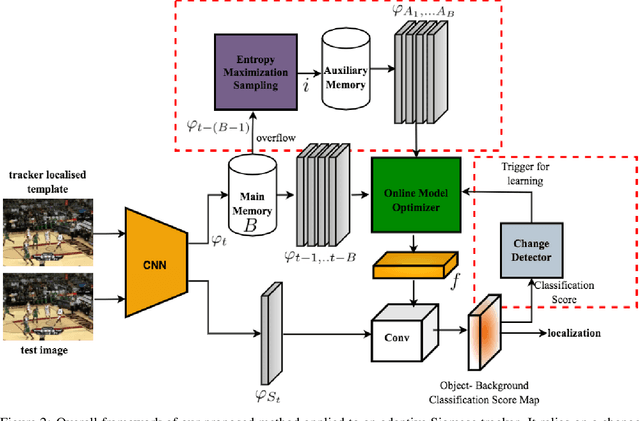
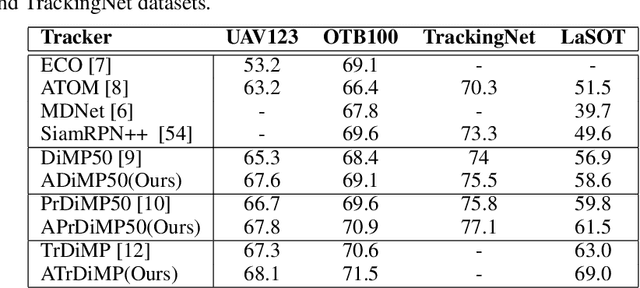
Deep Siamese trackers have recently gained much attention in recent years since they can track visual objects at high speeds. Additionally, adaptive tracking methods, where target samples collected by the tracker are employed for online learning, have achieved state-of-the-art accuracy. However, single object tracking (SOT) remains a challenging task in real-world application due to changes and deformations in a target object's appearance. Learning on all the collected samples may lead to catastrophic forgetting, and thereby corrupt the tracking model. In this paper, SOT is formulated as an online incremental learning problem. A new method is proposed for dynamic sample selection and memory replay, preventing template corruption. In particular, we propose a change detection mechanism to detect gradual changes in object appearance and select the corresponding samples for online adaption. In addition, an entropy-based sample selection strategy is introduced to maintain a diversified auxiliary buffer for memory replay. Our proposed method can be integrated into any object tracking algorithm that leverages online learning for model adaptation. Extensive experiments conducted on the OTB-100, LaSOT, UAV123, and TrackingNet datasets highlight the cost-effectiveness of our method, along with the contribution of its key components. Results indicate that integrating our proposed method into state-of-art adaptive Siamese trackers can increase the potential benefits of a template update strategy, and significantly improve performance.
Generative Target Update for Adaptive Siamese Tracking
Feb 21, 2022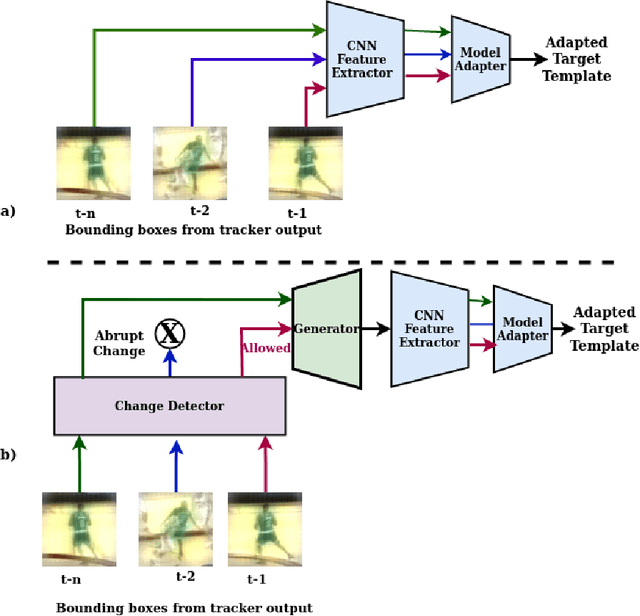
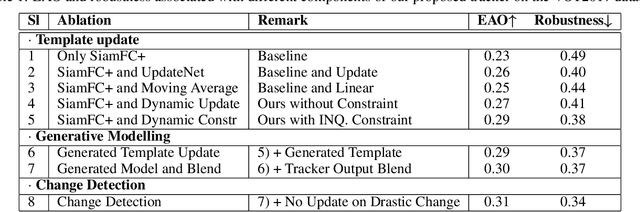
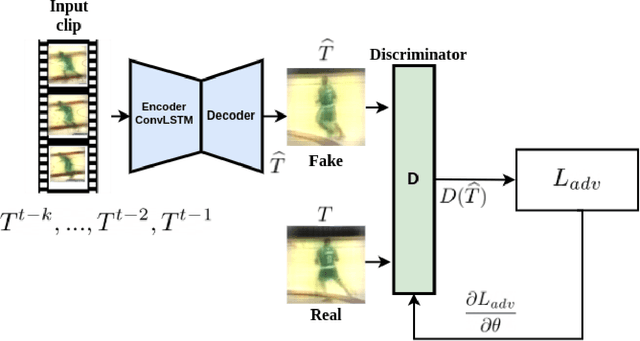
Siamese trackers perform similarity matching with templates (i.e., target models) to recursively localize objects within a search region. Several strategies have been proposed in the literature to update a template based on the tracker output, typically extracted from the target search region in the current frame, and thereby mitigate the effects of target drift. However, this may lead to corrupted templates, limiting the potential benefits of a template update strategy. This paper proposes a model adaptation method for Siamese trackers that uses a generative model to produce a synthetic template from the object search regions of several previous frames, rather than directly using the tracker output. Since the search region encompasses the target, attention from the search region is used for robust model adaptation. In particular, our approach relies on an auto-encoder trained through adversarial learning to detect changes in a target object's appearance and predict a future target template, using a set of target templates localized from tracker outputs at previous frames. To prevent template corruption during the update, the proposed tracker also performs change detection using the generative model to suspend updates until the tracker stabilizes, and robust matching can resume through dynamic template fusion. Extensive experiments conducted on VOT-16, VOT-17, OTB-50, and OTB-100 datasets highlight the effectiveness of our method, along with the impact of its key components. Results indicate that our proposed approach can outperform state-of-art trackers, and its overall robustness allows tracking for a longer time before failure.
Incremental Multi-Target Domain Adaptation for Object Detection with Efficient Domain Transfer
Apr 19, 2021
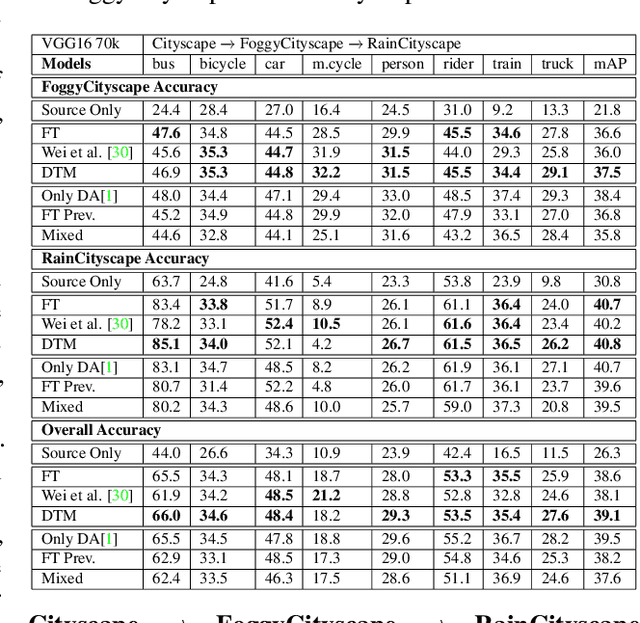
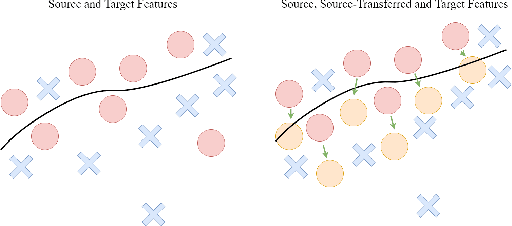
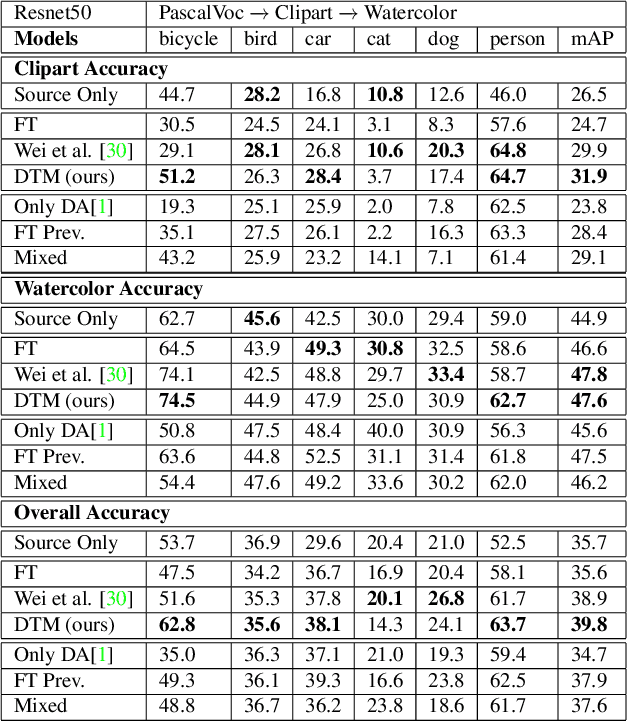
Techniques for multi-target domain adaptation (MTDA) seek to adapt a recognition model such that it can generalize well across multiple target domains. While several successful techniques have been proposed for unsupervised single-target domain adaptation (STDA) in object detection, adapting a model to multiple target domains using unlabeled image data remains a challenging and largely unexplored problem. Key challenges include the lack of bounding box annotations for target data, knowledge corruption, and the growing resource requirements needed to train accurate deep detection models. The later requirements are augmented by the need to retraining a model with previous-learned target data when adapting to each new target domain. Currently, the only MTDA technique in literature for object detection relies on distillation with a duplicated model to avoid knowledge corruption but does not leverage the source-target feature alignment after UDA. To address these challenges, we propose a new Incremental MTDA technique for object detection that can adapt a detector to multiple target domains, one at a time, without having to retain data of previously-learned target domains. Instead of distillation, our technique efficiently transfers source images to a joint target domains' space, on the fly, thereby preserving knowledge during incremental MTDA. Using adversarial training, our Domain Transfer Module (DTM) is optimized to trick the domain classifiers into classifying source images as though transferred into the target domain, thus allowing the DTM to generate samples close to a joint distribution of target domains. Our proposed technique is validated on different MTDA detection benchmarks, and results show it improving accuracy across multiple domains, despite the considerable reduction in complexity.
Holistic Guidance for Occluded Person Re-Identification
Apr 13, 2021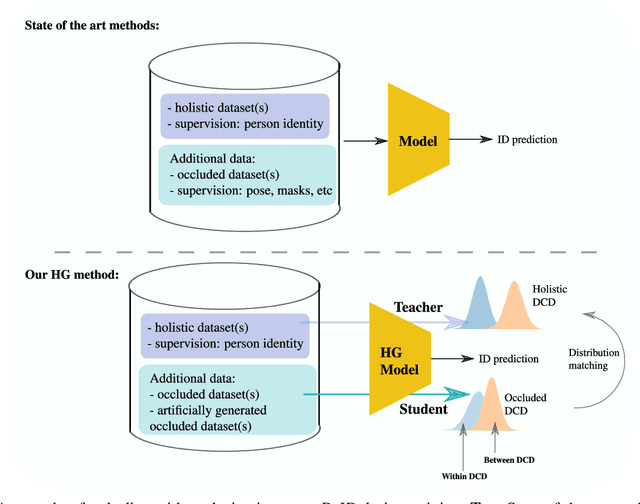
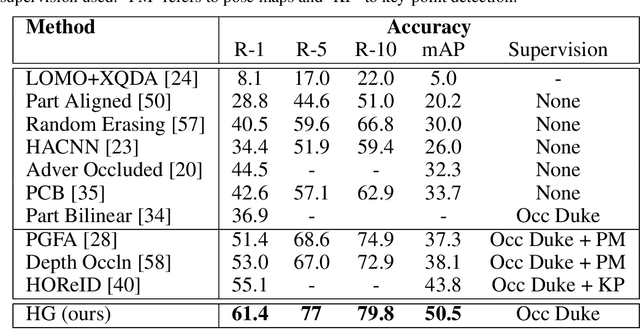
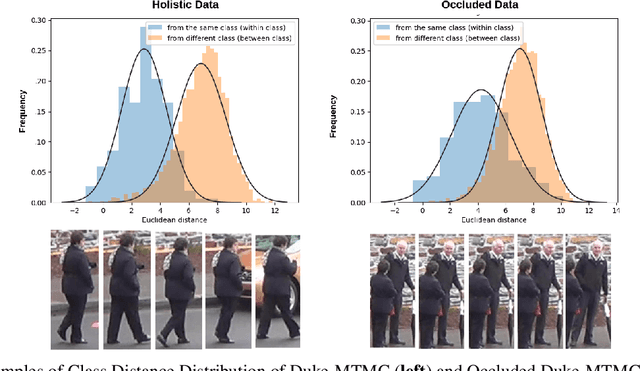
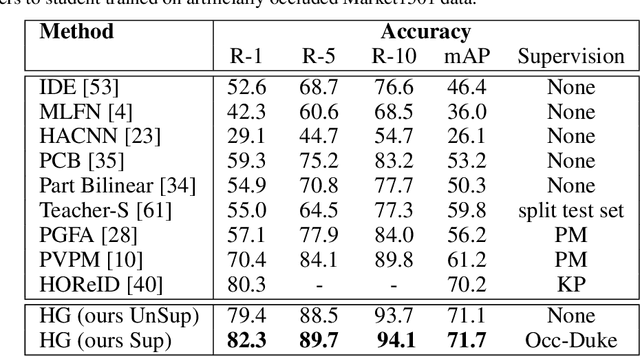
In real-world video surveillance applications, person re-identification (ReID) suffers from the effects of occlusions and detection errors. Despite recent advances, occlusions continue to corrupt the features extracted by state-of-art CNN backbones, and thereby deteriorate the accuracy of ReID systems. To address this issue, methods in the literature use an additional costly process such as pose estimation, where pose maps provide supervision to exclude occluded regions. In contrast, we introduce a novel Holistic Guidance (HG) method that relies only on person identity labels, and on the distribution of pairwise matching distances of datasets to alleviate the problem of occlusion, without requiring additional supervision. Hence, our proposed student-teacher framework is trained to address the occlusion problem by matching the distributions of between- and within-class distances (DCDs) of occluded samples with that of holistic (non-occluded) samples, thereby using the latter as a soft labeled reference to learn well separated DCDs. This approach is supported by our empirical study where the distribution of between- and within-class distances between images have more overlap in occluded than holistic datasets. In particular, features extracted from both datasets are jointly learned using the student model to produce an attention map that allows separating visible regions from occluded ones. In addition to this, a joint generative-discriminative backbone is trained with a denoising autoencoder, allowing the system to self-recover from occlusions. Extensive experiments on several challenging public datasets indicate that the proposed approach can outperform state-of-the-art methods on both occluded and holistic datasets
Knowledge Distillation Methods for Efficient Unsupervised Adaptation Across Multiple Domains
Jan 18, 2021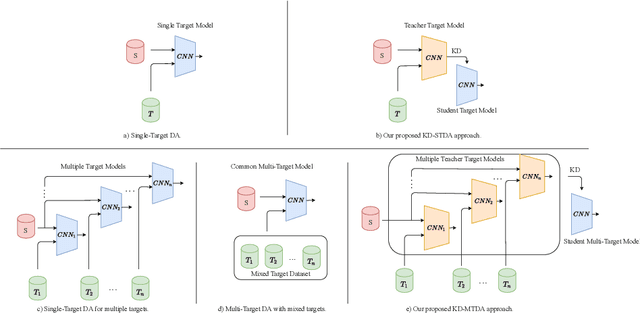
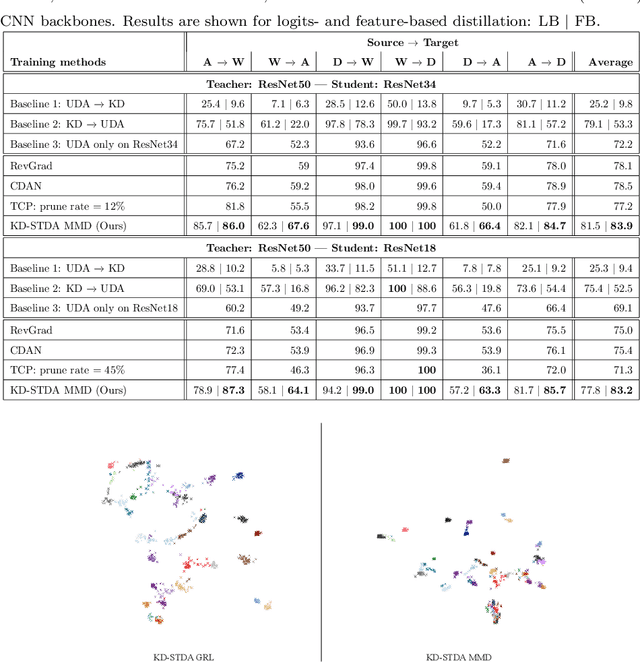
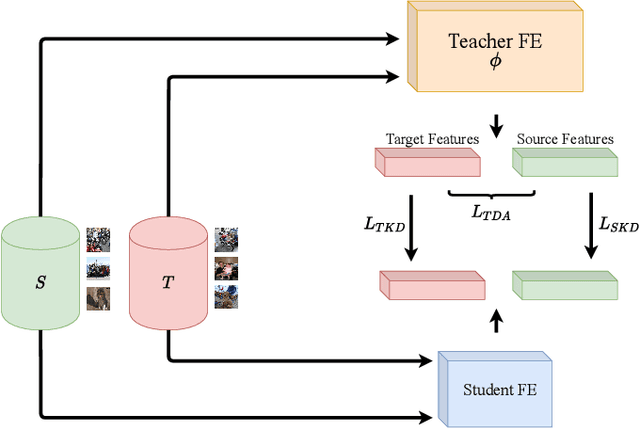
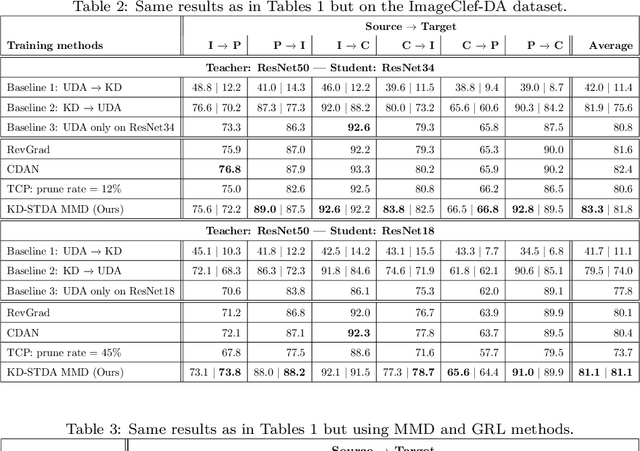
Beyond the complexity of CNNs that require training on large annotated datasets, the domain shift between design and operational data has limited the adoption of CNNs in many real-world applications. For instance, in person re-identification, videos are captured over a distributed set of cameras with non-overlapping viewpoints. The shift between the source (e.g. lab setting) and target (e.g. cameras) domains may lead to a significant decline in recognition accuracy. Additionally, state-of-the-art CNNs may not be suitable for such real-time applications given their computational requirements. Although several techniques have recently been proposed to address domain shift problems through unsupervised domain adaptation (UDA), or to accelerate/compress CNNs through knowledge distillation (KD), we seek to simultaneously adapt and compress CNNs to generalize well across multiple target domains. In this paper, we propose a progressive KD approach for unsupervised single-target DA (STDA) and multi-target DA (MTDA) of CNNs. Our method for KD-STDA adapts a CNN to a single target domain by distilling from a larger teacher CNN, trained on both target and source domain data in order to maintain its consistency with a common representation. Our proposed approach is compared against state-of-the-art methods for compression and STDA of CNNs on the Office31 and ImageClef-DA image classification datasets. It is also compared against state-of-the-art methods for MTDA on Digits, Office31, and OfficeHome. In both settings -- KD-STDA and KD-MTDA -- results indicate that our approach can achieve the highest level of accuracy across target domains, while requiring a comparable or lower CNN complexity.
Unsupervised Multi-Target Domain Adaptation Through Knowledge Distillation
Jul 20, 2020
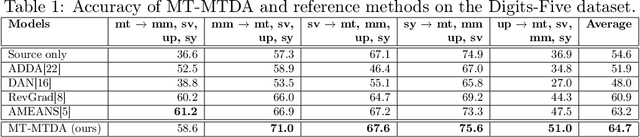


Unsupervised domain adaptation (UDA) seeks to alleviate the problem of domain shift between the distribution of unlabeled data from the target domain w.r.t labeled data from source domain. While the single-target domain scenario is well studied in UDA literature, the Multi-Target Domain Adaptation (MTDA) setting remains largely unexplored despite its importance. For instance, in video surveillance, each camera can corresponds to a different viewpoint (target domain). MTDA problem can be addressed by adapting one specialized model per target domain, although this solution is too costly in many applications. It has also been addressed by blending target data for multi-domain adaptation to train a common model, yet this may lead to a reduction in performance. In this paper, we propose a new unsupervised MTDA approach to train a common CNN that can generalize across multiple target domains. Our approach the Multi-Teacher MTDA (MT-MTDA) relies on multi-teacher knowledge distillation (KD) in order to distill target domain knowledge from multiple teachers to a common student. Inspired by a common education scenario, a different target domain is assigned to each teacher model for UDA, and these teachers alternatively distill their knowledge to one common student model. The KD process is performed in a progressive manner, where the student is trained by each teacher on how to perform UDA, instead of directly learning domain adapted features. Finally, instead of directly combining the knowledge from each teacher, MT-MTDA alternates between teachers that distill knowledge in order to preserve the specificity of each target (teacher) when learning to adapt the student. MT-MTDA is compared against state-of-the-art methods on OfficeHome, Office31 and Digits-5 datasets, and empirical results show that our proposed model can provide a considerably higher level of accuracy across multiple target domains.
Joint Progressive Knowledge Distillation and Unsupervised Domain Adaptation
May 16, 2020


Currently, the divergence in distributions of design and operational data, and large computational complexity are limiting factors in the adoption of CNNs in real-world applications. For instance, person re-identification systems typically rely on a distributed set of cameras, where each camera has different capture conditions. This can translate to a considerable shift between source (e.g. lab setting) and target (e.g. operational camera) domains. Given the cost of annotating image data captured for fine-tuning in each target domain, unsupervised domain adaptation (UDA) has become a popular approach to adapt CNNs. Moreover, state-of-the-art deep learning models that provide a high level of accuracy often rely on architectures that are too complex for real-time applications. Although several compression and UDA approaches have recently been proposed to overcome these limitations, they do not allow optimizing a CNN to simultaneously address both. In this paper, we propose an unexplored direction -- the joint optimization of CNNs to provide a compressed model that is adapted to perform well for a given target domain. In particular, the proposed approach performs unsupervised knowledge distillation (KD) from a complex teacher model to a compact student model, by leveraging both source and target data. It also improves upon existing UDA techniques by progressively teaching the student about domain-invariant features, instead of directly adapting a compact model on target domain data. Our method is compared against state-of-the-art compression and UDA techniques, using two popular classification datasets for UDA -- Office31 and ImageClef-DA. In both datasets, results indicate that our method can achieve the highest level of accuracy while requiring a comparable or lower time complexity.
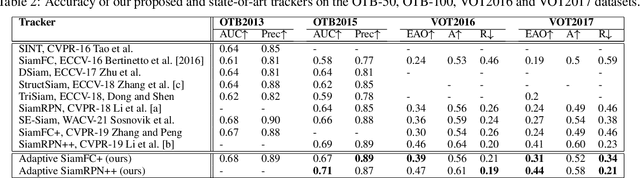
On the Interaction Between Deep Detectors and Siamese Trackers in Video Surveillance
Oct 31, 2019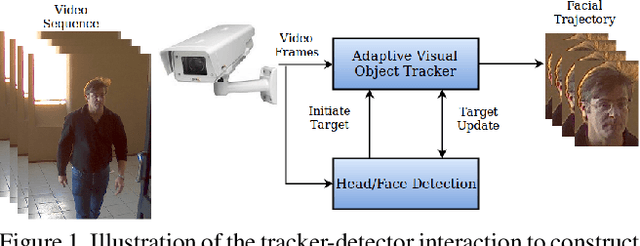

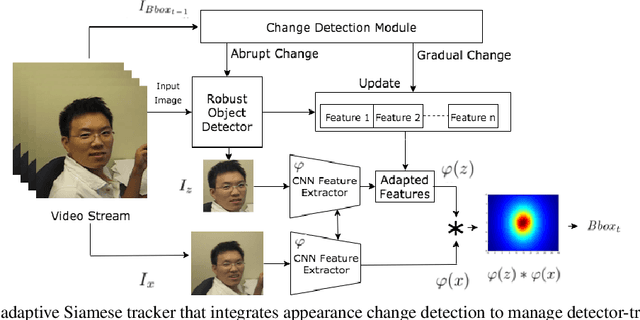
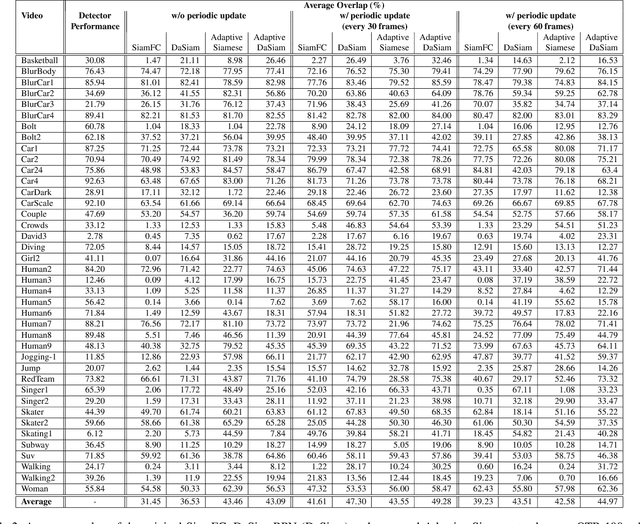
Visual object tracking is an important function in many real-time video surveillance applications, such as localization and spatio-temporal recognition of persons. In real-world applications, an object detector and tracker must interact on a periodic basis to discover new objects, and thereby to initiate tracks. Periodic interactions with the detector can also allow the tracker to validate and/or update its object template with new bounding boxes. However, bounding boxes provided by a state-of-the-art detector are noisy, due to changes in appearance, background and occlusion, which can cause the tracker to drift. Moreover, CNN-based detectors can provide a high level of accuracy at the expense of computational complexity, so interactions should be minimized for real-time applications. In this paper, a new approach is proposed to manage detector-tracker interactions for trackers from the Siamese-FC family. By integrating a change detection mechanism into a deep Siamese-FC tracker, its template can be adapted in response to changes in a target's appearance that lead to drifts during tracking. An abrupt change detection triggers an update of tracker template using the bounding box produced by the detector, while in the case of a gradual change, the detector is used to update an evolving set of templates for robust matching. Experiments were performed using state-of-the-art Siamese-FC trackers and the YOLOv3 detector on a subset of videos from the OTB-100 dataset that mimic video surveillance scenarios. Results highlight the importance for reliable VOT of using accurate detectors. They also indicate that our adaptive Siamese trackers are robust to noisy object detections, and can significantly improve the performance of Siamese-FC tracking.
An Improved Trade-off Between Accuracy and Complexity with Progressive Gradient Pruning
Aug 12, 2019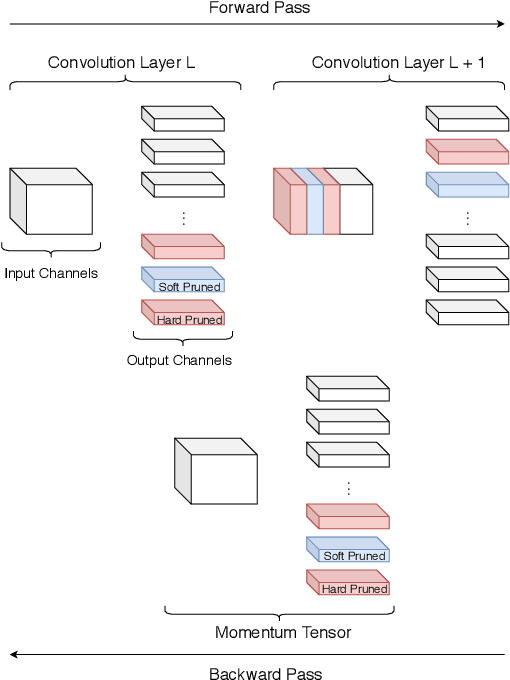
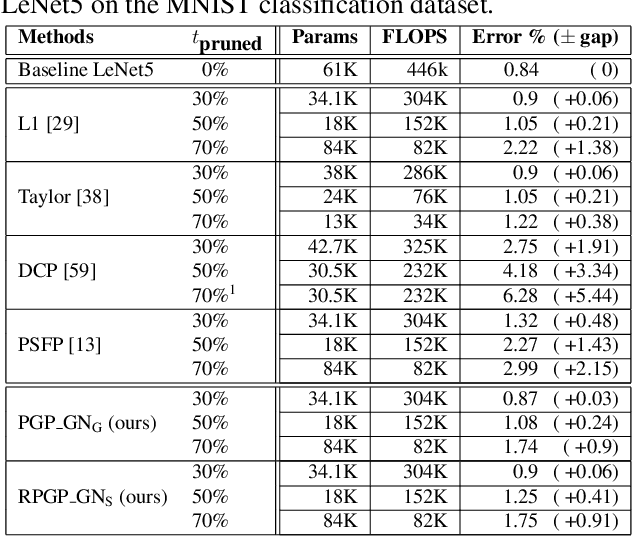

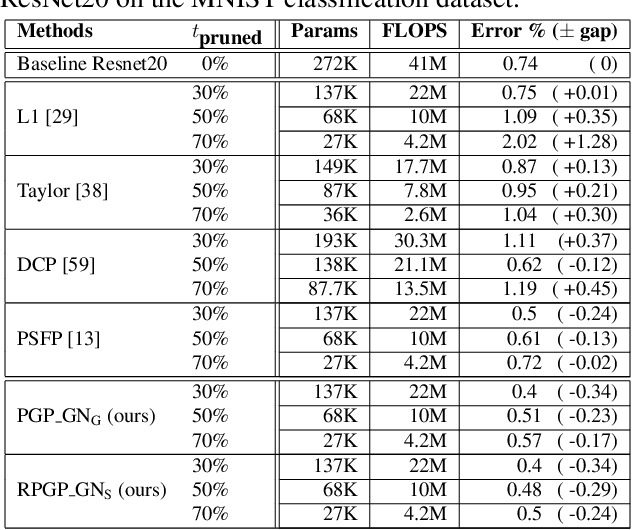
Although deep neural networks (NNs) have achieved state-of-the-art accuracy in many visual recognition tasks ,the growing computational complexity and energy consumption of networks remains an issue, especially for applications on platforms with limited resources and requiring real-time processing. Channel pruning techniques have recently shown promising results for the compression of convolutional NNs (CNNs). However, these techniques can result in low accuracy and complex optimisations because some only prune after training CNNs, while others prune from scratch during training by integrating sparsity constraints or modifying the loss function. The progressive soft filter pruning technique provides greater training efficiency, but its soft pruning strategy does no thandle the backward pass which is needed for better optimization. In this paper, a new Progressive Gradient Pruning (PGP) technique is proposed for iterative channel pruning during training. It relies on a criterion that measures the change in channel weights that improves existing progressive pruning, and on an effective hard and soft pruning strategies to adapt momentum tensors during the backward propagation pass. Experimental results obtained after training various CNNs on the MNIST and CIFAR10 datasets indicate that the PGP technique canachieve a better tradeoff between classification accuracy and network (time and memory) complexity than state-of-the-art channel pruning techniques