 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInconsistency-Aware Cross-Attention for Audio-Visual Fusion in Dimensional Emotion Recognition
May 21, 2024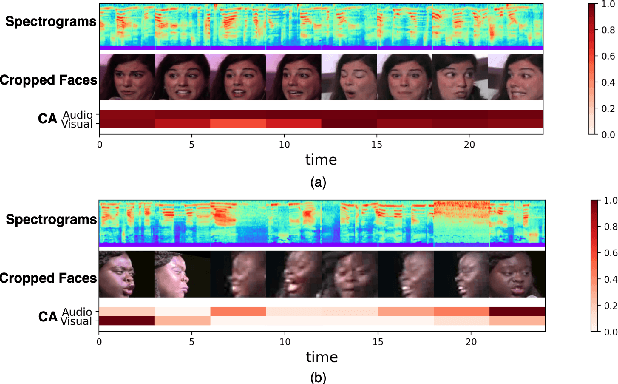
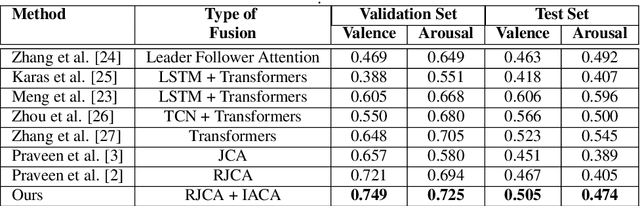
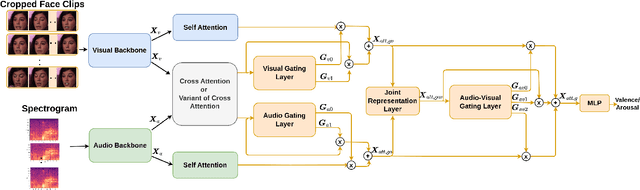
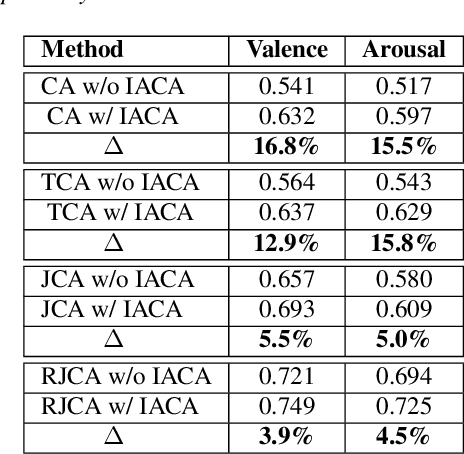
Leveraging complementary relationships across modalities has recently drawn a lot of attention in multimodal emotion recognition. Most of the existing approaches explored cross-attention to capture the complementary relationships across the modalities. However, the modalities may also exhibit weak complementary relationships, which may deteriorate the cross-attended features, resulting in poor multimodal feature representations. To address this problem, we propose Inconsistency-Aware Cross-Attention (IACA), which can adaptively select the most relevant features on-the-fly based on the strong or weak complementary relationships across audio and visual modalities. Specifically, we design a two-stage gating mechanism that can adaptively select the appropriate relevant features to deal with weak complementary relationships. Extensive experiments are conducted on the challenging Aff-Wild2 dataset to show the robustness of the proposed model.
Recursive Joint Attention for Audio-Visual Fusion in Regression based Emotion Recognition
Apr 17, 2023In video-based emotion recognition (ER), it is important to effectively leverage the complementary relationship among audio (A) and visual (V) modalities, while retaining the intra-modal characteristics of individual modalities. In this paper, a recursive joint attention model is proposed along with long short-term memory (LSTM) modules for the fusion of vocal and facial expressions in regression-based ER. Specifically, we investigated the possibility of exploiting the complementary nature of A and V modalities using a joint cross-attention model in a recursive fashion with LSTMs to capture the intra-modal temporal dependencies within the same modalities as well as among the A-V feature representations. By integrating LSTMs with recursive joint cross-attention, our model can efficiently leverage both intra- and inter-modal relationships for the fusion of A and V modalities. The results of extensive experiments performed on the challenging Affwild2 and Fatigue (private) datasets indicate that the proposed A-V fusion model can significantly outperform state-of-art-methods.
Audio-Visual Fusion for Emotion Recognition in the Valence-Arousal Space Using Joint Cross-Attention
Sep 19, 2022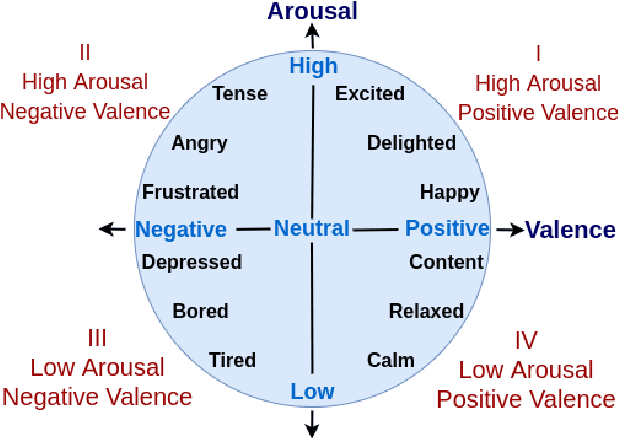
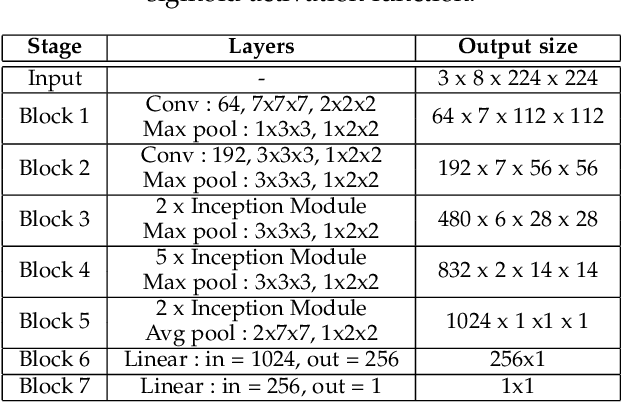
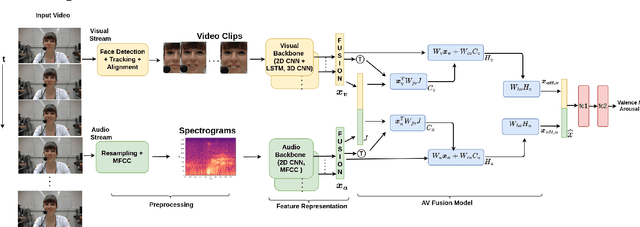
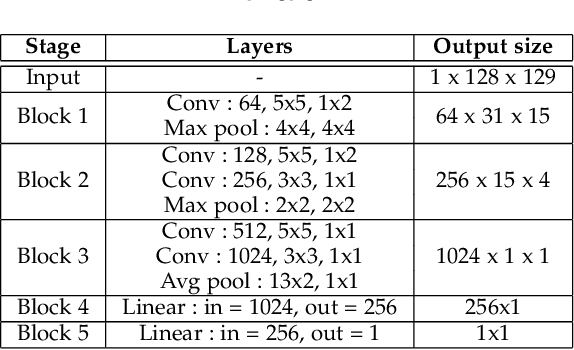
Automatic emotion recognition (ER) has recently gained lot of interest due to its potential in many real-world applications. In this context, multimodal approaches have been shown to improve performance (over unimodal approaches) by combining diverse and complementary sources of information, providing some robustness to noisy and missing modalities. In this paper, we focus on dimensional ER based on the fusion of facial and vocal modalities extracted from videos, where complementary audio-visual (A-V) relationships are explored to predict an individual's emotional states in valence-arousal space. Most state-of-the-art fusion techniques rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complementary nature of A-V modalities. To address this problem, we introduce a joint cross-attentional model for A-V fusion that extracts the salient features across A-V modalities, that allows to effectively leverage the inter-modal relationships, while retaining the intra-modal relationships. In particular, it computes the cross-attention weights based on correlation between the joint feature representation and that of the individual modalities. By deploying the joint A-V feature representation into the cross-attention module, it helps to simultaneously leverage both the intra and inter modal relationships, thereby significantly improving the performance of the system over the vanilla cross-attention module. The effectiveness of our proposed approach is validated experimentally on challenging videos from the RECOLA and AffWild2 datasets. Results indicate that our joint cross-attentional A-V fusion model provides a cost-effective solution that can outperform state-of-the-art approaches, even when the modalities are noisy or absent.
Holistic Guidance for Occluded Person Re-Identification
Apr 13, 2021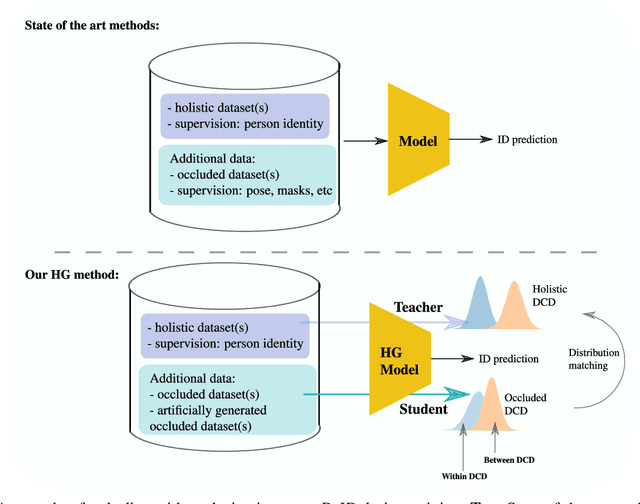
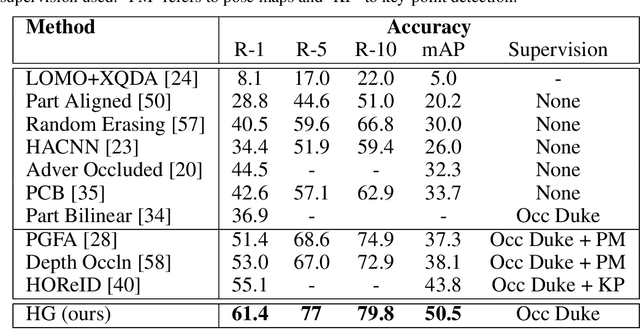
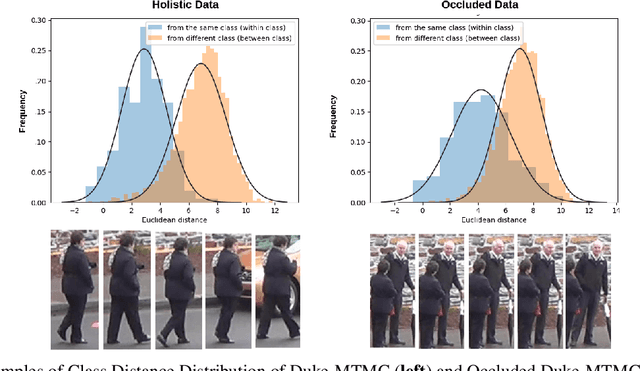
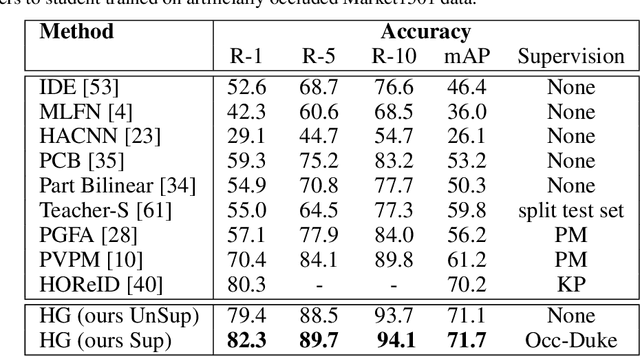
In real-world video surveillance applications, person re-identification (ReID) suffers from the effects of occlusions and detection errors. Despite recent advances, occlusions continue to corrupt the features extracted by state-of-art CNN backbones, and thereby deteriorate the accuracy of ReID systems. To address this issue, methods in the literature use an additional costly process such as pose estimation, where pose maps provide supervision to exclude occluded regions. In contrast, we introduce a novel Holistic Guidance (HG) method that relies only on person identity labels, and on the distribution of pairwise matching distances of datasets to alleviate the problem of occlusion, without requiring additional supervision. Hence, our proposed student-teacher framework is trained to address the occlusion problem by matching the distributions of between- and within-class distances (DCDs) of occluded samples with that of holistic (non-occluded) samples, thereby using the latter as a soft labeled reference to learn well separated DCDs. This approach is supported by our empirical study where the distribution of between- and within-class distances between images have more overlap in occluded than holistic datasets. In particular, features extracted from both datasets are jointly learned using the student model to produce an attention map that allows separating visible regions from occluded ones. In addition to this, a joint generative-discriminative backbone is trained with a denoising autoencoder, allowing the system to self-recover from occlusions. Extensive experiments on several challenging public datasets indicate that the proposed approach can outperform state-of-the-art methods on both occluded and holistic datasets