 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera Alignment and Weighted Contrastive Learning for Domain Adaptation in Video Person ReID
Nov 07, 2022



Systems for person re-identification (ReID) can achieve a high accuracy when trained on large fully-labeled image datasets. However, the domain shift typically associated with diverse operational capture conditions (e.g., camera viewpoints and lighting) may translate to a significant decline in performance. This paper focuses on unsupervised domain adaptation (UDA) for video-based ReID - a relevant scenario that is less explored in the literature. In this scenario, the ReID model must adapt to a complex target domain defined by a network of diverse video cameras based on tracklet information. State-of-art methods cluster unlabeled target data, yet domain shifts across target cameras (sub-domains) can lead to poor initialization of clustering methods that propagates noise across epochs, thus preventing the ReID model to accurately associate samples of same identity. In this paper, an UDA method is introduced for video person ReID that leverages knowledge on video tracklets, and on the distribution of frames captured over target cameras to improve the performance of CNN backbones trained using pseudo-labels. Our method relies on an adversarial approach, where a camera-discriminator network is introduced to extract discriminant camera-independent representations, facilitating the subsequent clustering. In addition, a weighted contrastive loss is proposed to leverage the confidence of clusters, and mitigate the risk of incorrect identity associations. Experimental results obtained on three challenging video-based person ReID datasets - PRID2011, iLIDS-VID, and MARS - indicate that our proposed method can outperform related state-of-the-art methods. Our code is available at: \url{https://github.com/dmekhazni/CAWCL-ReID}
Knowledge Distillation for Multi-Target Domain Adaptation in Real-Time Person Re-Identification
May 12, 2022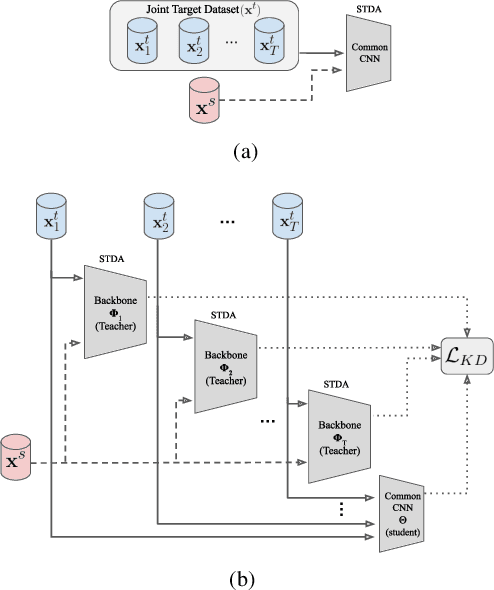
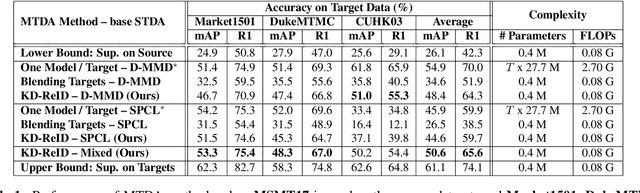
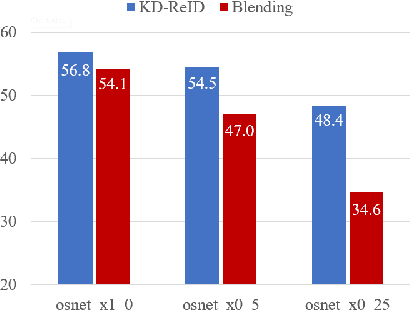
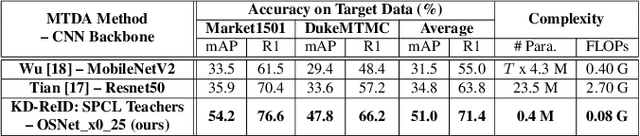
Despite the recent success of deep learning architectures, person re-identification (ReID) remains a challenging problem in real-word applications. Several unsupervised single-target domain adaptation (STDA) methods have recently been proposed to limit the decline in ReID accuracy caused by the domain shift that typically occurs between source and target video data. Given the multimodal nature of person ReID data (due to variations across camera viewpoints and capture conditions), training a common CNN backbone to address domain shifts across multiple target domains, can provide an efficient solution for real-time ReID applications. Although multi-target domain adaptation (MTDA) has not been widely addressed in the ReID literature, a straightforward approach consists in blending different target datasets, and performing STDA on the mixture to train a common CNN. However, this approach may lead to poor generalization, especially when blending a growing number of distinct target domains to train a smaller CNN. To alleviate this problem, we introduce a new MTDA method based on knowledge distillation (KD-ReID) that is suitable for real-time person ReID applications. Our method adapts a common lightweight student backbone CNN over the target domains by alternatively distilling from multiple specialized teacher CNNs, each one adapted on data from a specific target domain. Extensive experiments conducted on several challenging person ReID datasets indicate that our approach outperforms state-of-art methods for MTDA, including blending methods, particularly when training a compact CNN backbone like OSNet. Results suggest that our flexible MTDA approach can be employed to design cost-effective ReID systems for real-time video surveillance applications.
Unsupervised Domain Adaptation in the Dissimilarity Space for Person Re-identification
Jul 27, 2020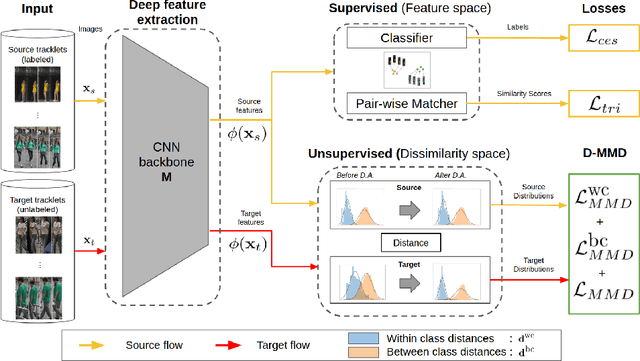
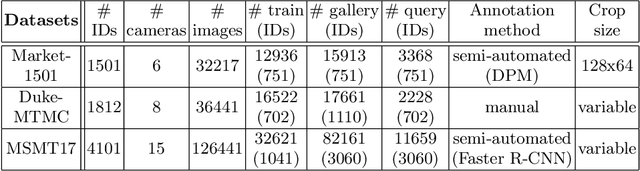
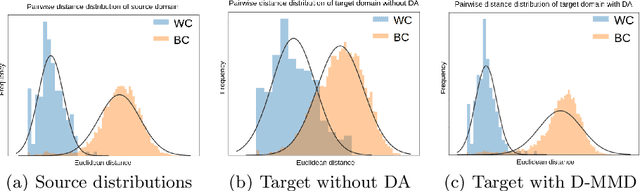
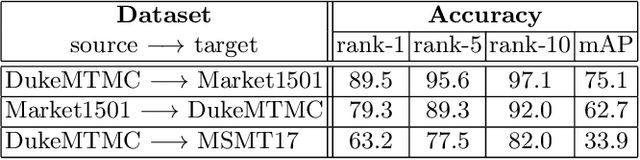
Person re-identification (ReID) remains a challenging task in many real-word video analytics and surveillance applications, even though state-of-the-art accuracy has improved considerably with the advent of deep learning (DL) models trained on large image datasets. Given the shift in distributions that typically occurs between video data captured from the source and target domains, and absence of labeled data from the target domain, it is difficult to adapt a DL model for accurate recognition of target data. We argue that for pair-wise matchers that rely on metric learning, e.g., Siamese networks for person ReID, the unsupervised domain adaptation (UDA) objective should consist in aligning pair-wise dissimilarity between domains, rather than aligning feature representations. Moreover, dissimilarity representations are more suitable for designing open-set ReID systems, where identities differ in the source and target domains. In this paper, we propose a novel Dissimilarity-based Maximum Mean Discrepancy (D-MMD) loss for aligning pair-wise distances that can be optimized via gradient descent. From a person ReID perspective, the evaluation of D-MMD loss is straightforward since the tracklet information allows to label a distance vector as being either within-class or between-class. This allows approximating the underlying distribution of target pair-wise distances for D-MMD loss optimization, and accordingly align source and target distance distributions. Empirical results with three challenging benchmark datasets show that the proposed D-MMD loss decreases as source and domain distributions become more similar. Extensive experimental evaluation also indicates that UDA methods that rely on the D-MMD loss can significantly outperform baseline and state-of-the-art UDA methods for person ReID without the common requirement for data augmentation and/or complex networks.