 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation in the Dissimilarity Space for Person Re-identification
Jul 27, 2020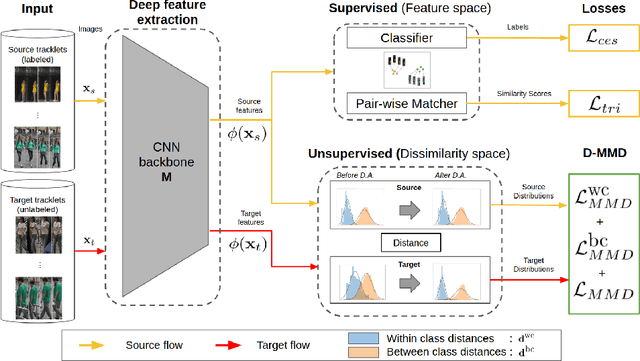
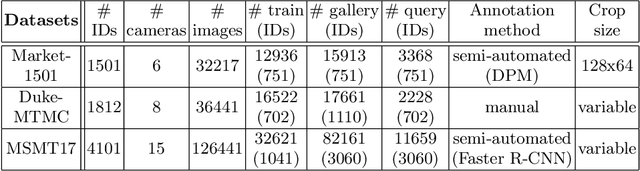
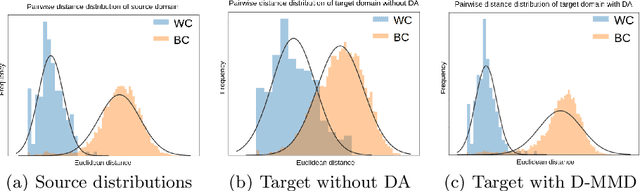
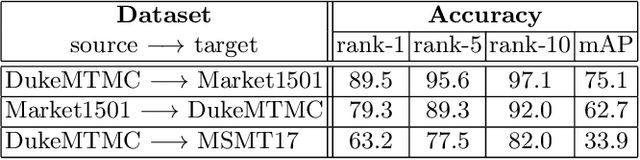
Person re-identification (ReID) remains a challenging task in many real-word video analytics and surveillance applications, even though state-of-the-art accuracy has improved considerably with the advent of deep learning (DL) models trained on large image datasets. Given the shift in distributions that typically occurs between video data captured from the source and target domains, and absence of labeled data from the target domain, it is difficult to adapt a DL model for accurate recognition of target data. We argue that for pair-wise matchers that rely on metric learning, e.g., Siamese networks for person ReID, the unsupervised domain adaptation (UDA) objective should consist in aligning pair-wise dissimilarity between domains, rather than aligning feature representations. Moreover, dissimilarity representations are more suitable for designing open-set ReID systems, where identities differ in the source and target domains. In this paper, we propose a novel Dissimilarity-based Maximum Mean Discrepancy (D-MMD) loss for aligning pair-wise distances that can be optimized via gradient descent. From a person ReID perspective, the evaluation of D-MMD loss is straightforward since the tracklet information allows to label a distance vector as being either within-class or between-class. This allows approximating the underlying distribution of target pair-wise distances for D-MMD loss optimization, and accordingly align source and target distance distributions. Empirical results with three challenging benchmark datasets show that the proposed D-MMD loss decreases as source and domain distributions become more similar. Extensive experimental evaluation also indicates that UDA methods that rely on the D-MMD loss can significantly outperform baseline and state-of-the-art UDA methods for person ReID without the common requirement for data augmentation and/or complex networks.
Dual-Triplet Metric Learning for Unsupervised Domain Adaptation in Video-Based Face Recognition
Feb 11, 2020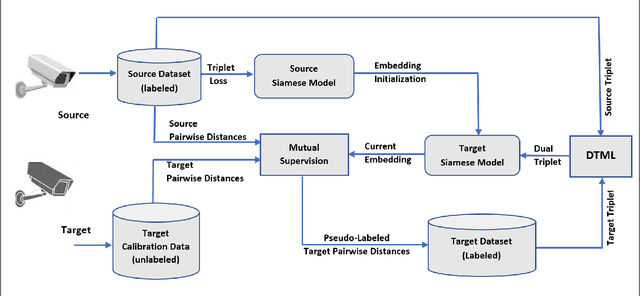
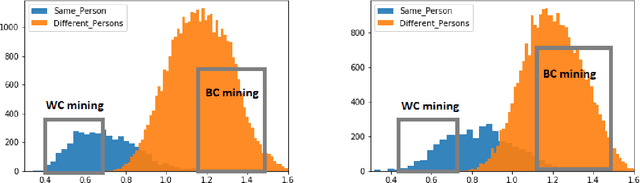
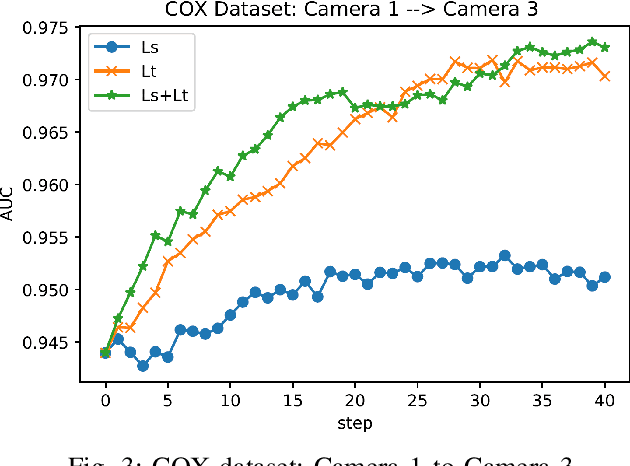
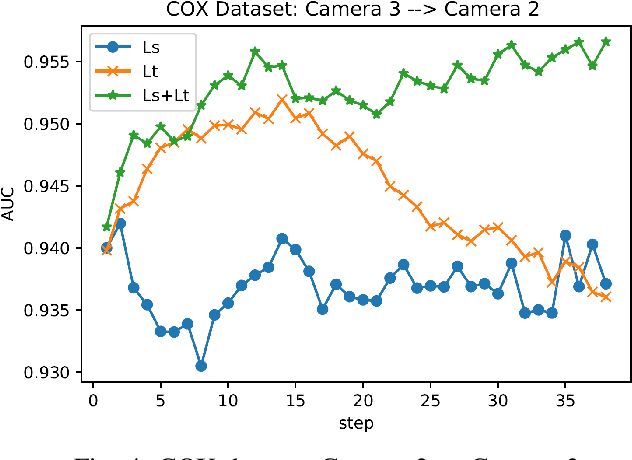
The scalability and complexity of deep learning models remains a key issue in many of visual recognition applications like, e.g., video surveillance, where fine tuning with labeled image data from each new camera is required to reduce the domain shift between videos captured from the source domain, e.g., a laboratory setting, and the target domain, i.e, an operational environment. In many video surveillance applications, like face recognition (FR) and person re-identification, a pair-wise matcher is used to assign a query image captured using a video camera to the corresponding reference images in a gallery. The different configurations and operational conditions of video cameras can introduce significant shifts in the pair-wise distance distributions, resulting in degraded recognition performance for new cameras. In this paper, a new deep domain adaptation (DA) method is proposed to adapt the CNN embedding of a Siamese network using unlabeled tracklets captured with a new video cameras. To this end, a dual-triplet loss is introduced for metric learning, where two triplets are constructed using video data from a source camera, and a new target camera. In order to constitute the dual triplets, a mutual-supervised learning approach is introduced where the source camera acts as a teacher, providing the target camera with an initial embedding. Then, the student relies on the teacher to iteratively label the positive and negative pairs collected during, e.g., initial camera calibration. Both source and target embeddings continue to simultaneously learn such that their pair-wise distance distributions become aligned. For validation, the proposed metric learning technique is used to train deep Siamese networks under different training scenarios, and is compared to state-of-the-art techniques for still-to-video FR on the COX-S2V and a private video-based FR dataset.