 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Triplet Metric Learning for Unsupervised Domain Adaptation in Video-Based Face Recognition
Paper and Code
Feb 11, 2020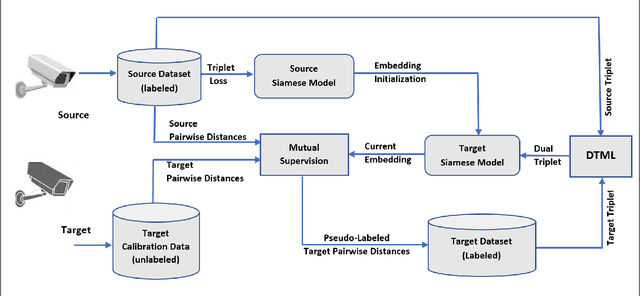
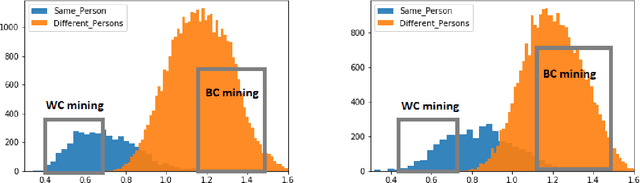
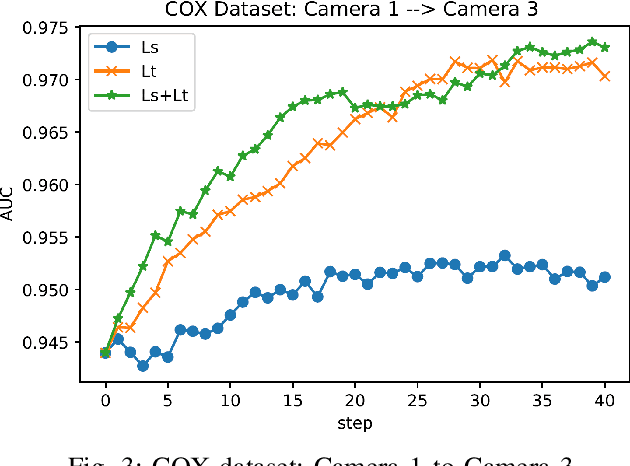
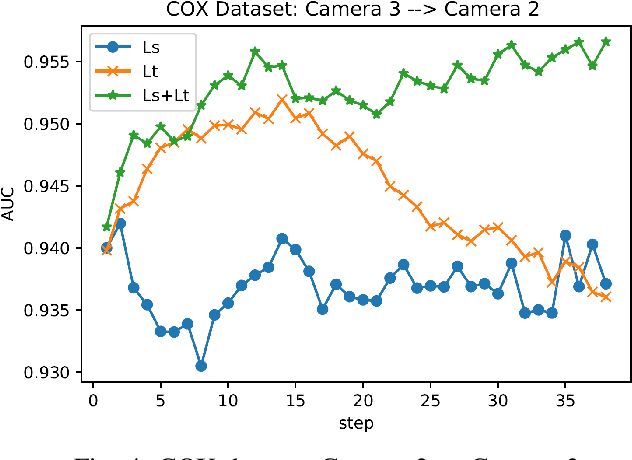
The scalability and complexity of deep learning models remains a key issue in many of visual recognition applications like, e.g., video surveillance, where fine tuning with labeled image data from each new camera is required to reduce the domain shift between videos captured from the source domain, e.g., a laboratory setting, and the target domain, i.e, an operational environment. In many video surveillance applications, like face recognition (FR) and person re-identification, a pair-wise matcher is used to assign a query image captured using a video camera to the corresponding reference images in a gallery. The different configurations and operational conditions of video cameras can introduce significant shifts in the pair-wise distance distributions, resulting in degraded recognition performance for new cameras. In this paper, a new deep domain adaptation (DA) method is proposed to adapt the CNN embedding of a Siamese network using unlabeled tracklets captured with a new video cameras. To this end, a dual-triplet loss is introduced for metric learning, where two triplets are constructed using video data from a source camera, and a new target camera. In order to constitute the dual triplets, a mutual-supervised learning approach is introduced where the source camera acts as a teacher, providing the target camera with an initial embedding. Then, the student relies on the teacher to iteratively label the positive and negative pairs collected during, e.g., initial camera calibration. Both source and target embeddings continue to simultaneously learn such that their pair-wise distance distributions become aligned. For validation, the proposed metric learning technique is used to train deep Siamese networks under different training scenarios, and is compared to state-of-the-art techniques for still-to-video FR on the COX-S2V and a private video-based FR dataset.