 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation: Do LVLM Judges Generalize Across Languages?
Apr 21, 2026Automatic evaluators such as reward models play a central role in the alignment and evaluation of large vision-language models (LVLMs). Despite their growing importance, these evaluators are almost exclusively assessed on English-centric benchmarks, leaving open the question of how well these evaluators generalize across languages. To answer this question, we introduce MM-JudgeBench, the first large-scale benchmark for multilingual and multimodal judge model evaluation, which includes over 60K pairwise preference instances spanning 25 typologically diverse languages. MM-JudgeBench integrates two complementary subsets: a general vision-language preference evaluation subset extending VL-RewardBench, and a chart-centric visual-text reasoning subset derived from OpenCQA, enabling systematic analysis of reward models (i.e., LVLM judges) across diverse settings. We additionally release a multilingual training set derived from MM-RewardBench, disjoint from our evaluation data, to support domain adaptation. By evaluating 22 LVLMs (15 open-source, 7 proprietary), we uncover substantial cross-lingual performance variance in our proposed benchmark. Our analysis further shows that model size and architecture are poor predictors of multilingual robustness, and that even state-of-the-art LVLM judges exhibit inconsistent behavior across languages. Together, these findings expose fundamental limitations of current reward modeling and underscore the necessity of multilingual, multimodal benchmarks for developing reliable automated evaluators.
Learning to Fast Unrank in Collaborative Filtering Recommendation
Nov 10, 2025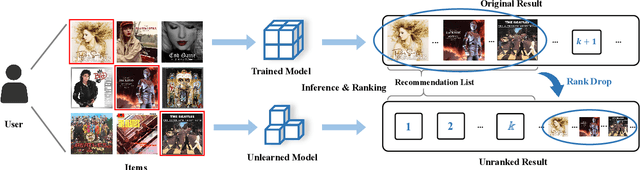
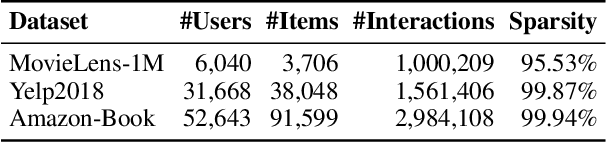
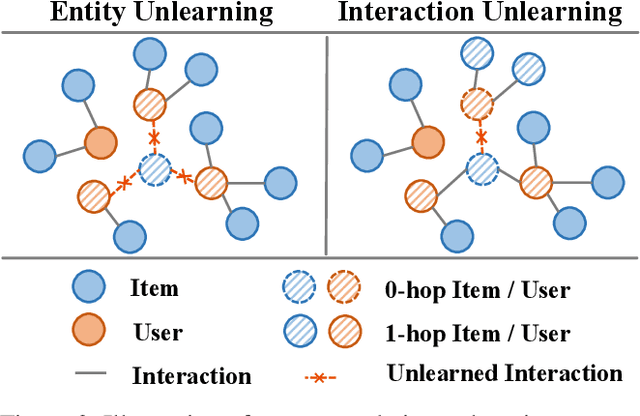
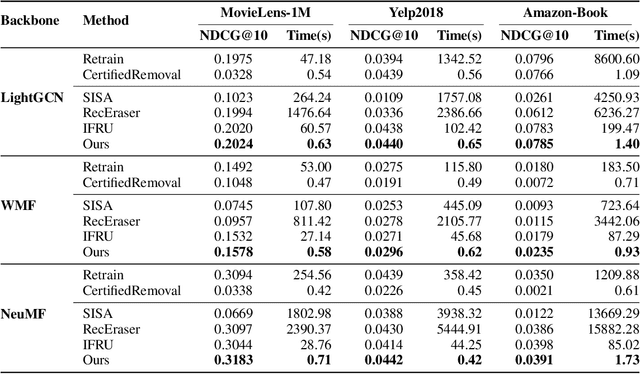
Modern data-driven recommendation systems risk memorizing sensitive user behavioral patterns, raising privacy concerns. Existing recommendation unlearning methods, while capable of removing target data influence, suffer from inefficient unlearning speed and degraded performance, failing to meet real-time unlearning demands. Considering the ranking-oriented nature of recommendation systems, we present unranking, the process of reducing the ranking positions of target items while ensuring the formal guarantees of recommendation unlearning. To achieve efficient unranking, we propose Learning to Fast Unrank in Collaborative Filtering Recommendation (L2UnRank), which operates through three key stages: (a) identifying the influenced scope via interaction-based p-hop propagation, (b) computing structural and semantic influences for entities within this scope, and (c) performing efficient, ranking-aware parameter updates guided by influence information. Extensive experiments across multiple datasets and backbone models demonstrate L2UnRank's model-agnostic nature, achieving state-of-the-art unranking effectiveness and maintaining recommendation quality comparable to retraining, while also delivering a 50x speedup over existing methods. Codes are available at https://github.com/Juniper42/L2UnRank.
Evolution of ReID: From Early Methods to LLM Integration
Jun 16, 2025



Person re-identification (ReID) has evolved from handcrafted feature-based methods to deep learning approaches and, more recently, to models incorporating large language models (LLMs). Early methods struggled with variations in lighting, pose, and viewpoint, but deep learning addressed these issues by learning robust visual features. Building on this, LLMs now enable ReID systems to integrate semantic and contextual information through natural language. This survey traces that full evolution and offers one of the first comprehensive reviews of ReID approaches that leverage LLMs, where textual descriptions are used as privileged information to improve visual matching. A key contribution is the use of dynamic, identity-specific prompts generated by GPT-4o, which enhance the alignment between images and text in vision-language ReID systems. Experimental results show that these descriptions improve accuracy, especially in complex or ambiguous cases. To support further research, we release a large set of GPT-4o-generated descriptions for standard ReID datasets. By bridging computer vision and natural language processing, this survey offers a unified perspective on the field's development and outlines key future directions such as better prompt design, cross-modal transfer learning, and real-world adaptability.
Judging the Judges: Can Large Vision-Language Models Fairly Evaluate Chart Comprehension and Reasoning?
May 13, 2025Charts are ubiquitous as they help people understand and reason with data. Recently, various downstream tasks, such as chart question answering, chart2text, and fact-checking, have emerged. Large Vision-Language Models (LVLMs) show promise in tackling these tasks, but their evaluation is costly and time-consuming, limiting real-world deployment. While using LVLMs as judges to assess the chart comprehension capabilities of other LVLMs could streamline evaluation processes, challenges like proprietary datasets, restricted access to powerful models, and evaluation costs hinder their adoption in industrial settings. To this end, we present a comprehensive evaluation of 13 open-source LVLMs as judges for diverse chart comprehension and reasoning tasks. We design both pairwise and pointwise evaluation tasks covering criteria like factual correctness, informativeness, and relevancy. Additionally, we analyze LVLM judges based on format adherence, positional consistency, length bias, and instruction-following. We focus on cost-effective LVLMs (<10B parameters) suitable for both research and commercial use, following a standardized evaluation protocol and rubric to measure the LVLM judge's accuracy. Experimental results reveal notable variability: while some open LVLM judges achieve GPT-4-level evaluation performance (about 80% agreement with GPT-4 judgments), others struggle (below ~10% agreement). Our findings highlight that state-of-the-art open-source LVLMs can serve as cost-effective automatic evaluators for chart-related tasks, though biases such as positional preference and length bias persist.
A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Recommendations
Jul 04, 2024



Large Language Models (LLMs) have recently gained significant attention due to their remarkable capabilities in performing diverse tasks across various domains. However, a thorough evaluation of these models is crucial before deploying them in real-world applications to ensure they produce reliable performance. Despite the well-established importance of evaluating LLMs in the community, the complexity of the evaluation process has led to varied evaluation setups, causing inconsistencies in findings and interpretations. To address this, we systematically review the primary challenges and limitations causing these inconsistencies and unreliable evaluations in various steps of LLM evaluation. Based on our critical review, we present our perspectives and recommendations to ensure LLM evaluations are reproducible, reliable, and robust.
Flow-Guided Attention Networks for Video-Based Person Re-Identification
Aug 09, 2020
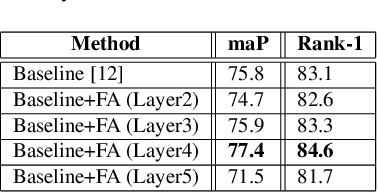

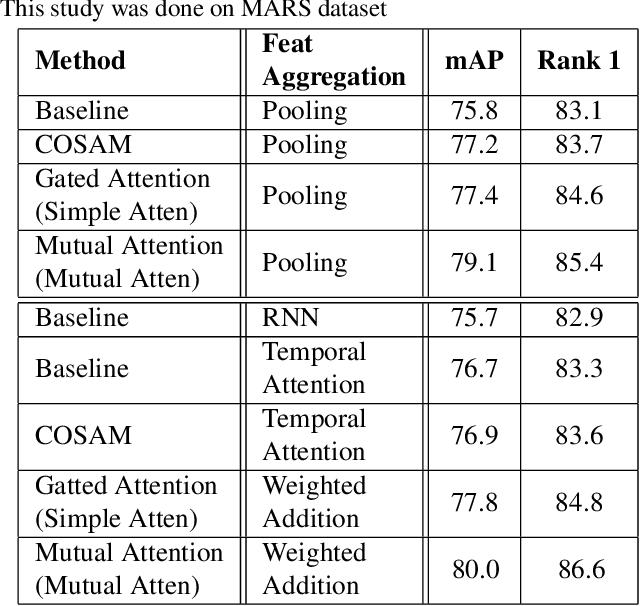
Person Re-Identification (ReID) is an important problem in many video analytics and surveillance applications,where a person's identity must be associated across a distributed network of cameras. Video-based person ReID has recently gained much interest because it can capture discriminant spatio-temporal information that is unavailable for image-based ReID. Despite recent advances, deep learning models for video ReID often fail to leverage this information to improve the robustness of feature representations. In this paper, the motion pattern of a person is explored as an additional cue for ReID. In particular, two different flow-guided attention networks are proposed for fusion with any 2D-CNN backbone, allowing to encode temporal information along with spatial appearance information.Our first proposed network called Gated Attention relies on optical flow to generate gated attention with video-based feature that embed spatially. Hence the proposed framework allows to activate a common set of salient features across multiple frames. In contrast, our second network called Mutual Attention relies on the joint attention between image and optical flow features. This enables spatial attention between both sources of features, across motion and appearance cues. Both methods introduce a feature aggregation method that produce video features by identifying salient spatio-temporal information.Extensive experiments on two challenging video datasets indicate that using the proposed flow-guided spatio-temporal attention networks allows to improve recognition accuracy considerably, outperforming state-of-the-art methods for video-based person ReID. Additionally, our Mutual Attention network is able to process longer frame sequences with a wider range of appearance variations for highly accurate recognition.
Unsupervised Domain Adaptation in the Dissimilarity Space for Person Re-identification
Jul 27, 2020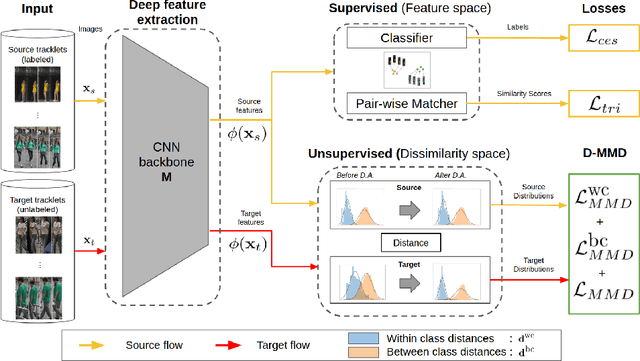
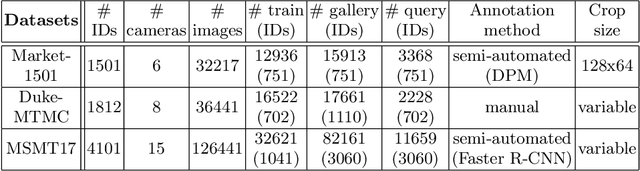
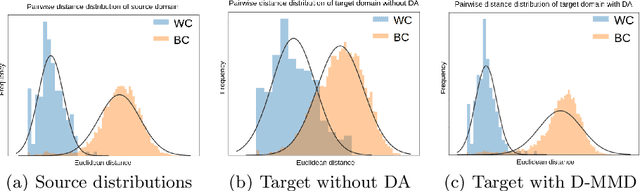
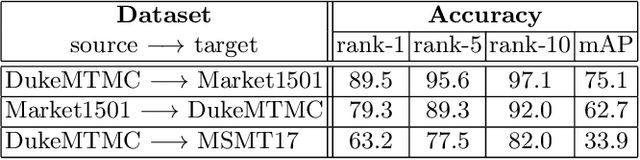
Person re-identification (ReID) remains a challenging task in many real-word video analytics and surveillance applications, even though state-of-the-art accuracy has improved considerably with the advent of deep learning (DL) models trained on large image datasets. Given the shift in distributions that typically occurs between video data captured from the source and target domains, and absence of labeled data from the target domain, it is difficult to adapt a DL model for accurate recognition of target data. We argue that for pair-wise matchers that rely on metric learning, e.g., Siamese networks for person ReID, the unsupervised domain adaptation (UDA) objective should consist in aligning pair-wise dissimilarity between domains, rather than aligning feature representations. Moreover, dissimilarity representations are more suitable for designing open-set ReID systems, where identities differ in the source and target domains. In this paper, we propose a novel Dissimilarity-based Maximum Mean Discrepancy (D-MMD) loss for aligning pair-wise distances that can be optimized via gradient descent. From a person ReID perspective, the evaluation of D-MMD loss is straightforward since the tracklet information allows to label a distance vector as being either within-class or between-class. This allows approximating the underlying distribution of target pair-wise distances for D-MMD loss optimization, and accordingly align source and target distance distributions. Empirical results with three challenging benchmark datasets show that the proposed D-MMD loss decreases as source and domain distributions become more similar. Extensive experimental evaluation also indicates that UDA methods that rely on the D-MMD loss can significantly outperform baseline and state-of-the-art UDA methods for person ReID without the common requirement for data augmentation and/or complex networks.
A Survey of Pruning Methods for Efficient Person Re-identification Across Domains
Jul 04, 2019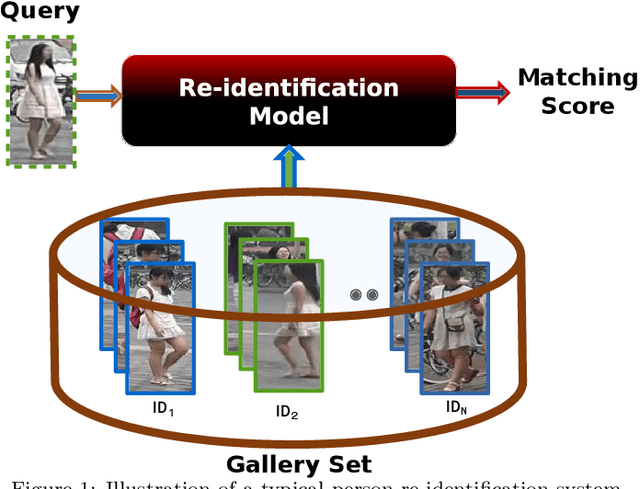
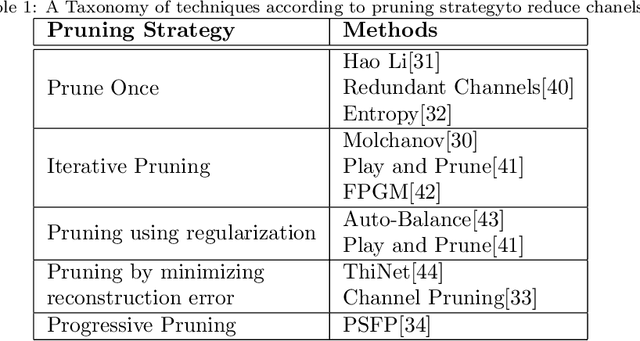
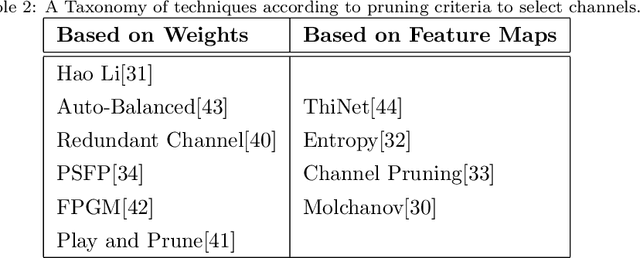
Recent years have witnessed a substantial increase in the deep learning architectures proposed for visual recognition tasks like person re-identification, where individuals must be recognized over multiple distributed cameras. Although deep Siamese networks have greatly improved the state-of-the-art accuracy, the computational complexity of the CNNs used for feature extraction remains an issue, hindering their deployment on platforms with with limited resources, or in applications with real-time constraints. Thus, there is an obvious advantage to compressing these architectures without significantly decreasing their accuracy. This paper provides a survey of state-of-the-art pruning techniques that are suitable for compressing deep Siamese networks applied to person re-identification. These techniques are analysed according to their pruning criteria and strategy, and according to different design scenarios for exploiting pruning methods to fine-tuning networks for target applications. Experimental results obtained using Siamese networks with ResNet feature extractors, and multiple benchmarks re-identification datasets, indicate that pruning can considerably reduce network complexity while maintaining a high level of accuracy. In scenarios where pruning is performed with large pre-training or fine-tuning datasets, the number of FLOPS required by the ResNet feature extractor is reduced by half, while maintaining a comparable rank-1 accuracy (within 1\% of the original model). Pruning while training a larger CNNs can also provide a significantly better performance than fine-tuning smaller ones.
A Cross-Modal Distillation Network for Person Re-identification in RGB-Depth
Nov 05, 2018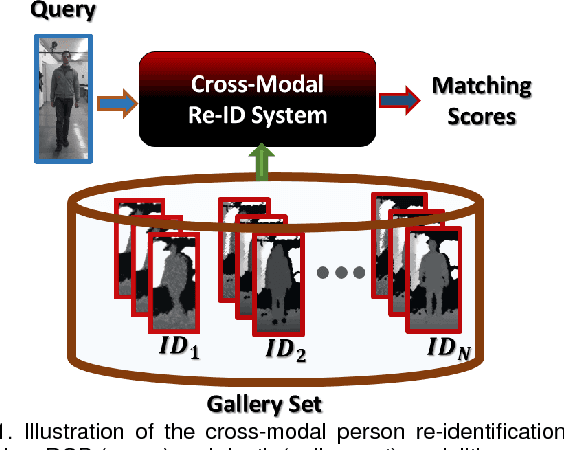
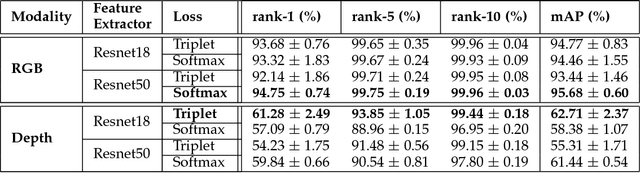
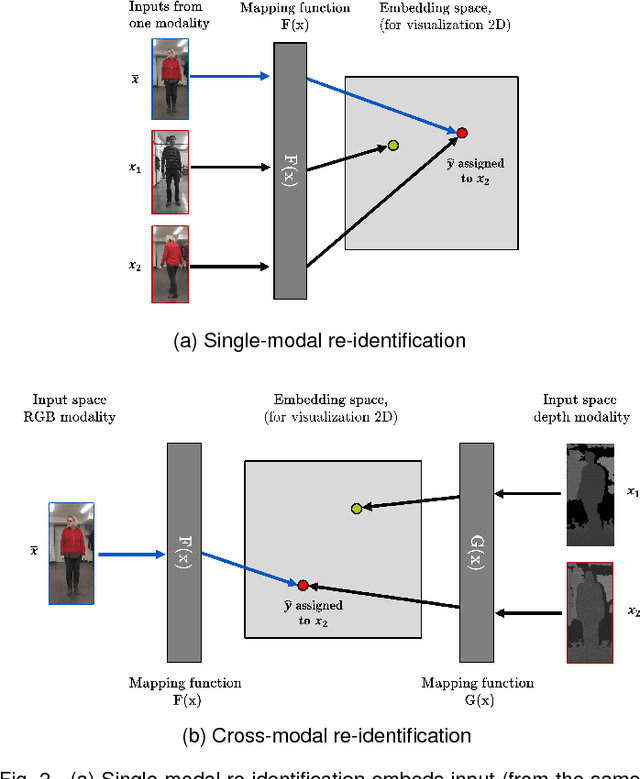
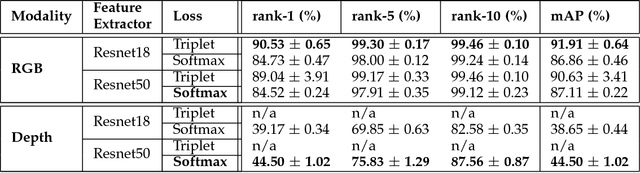
Person re-identification involves the recognition over time of individuals captured using multiple distributed sensors. With the advent of powerful deep learning methods able to learn discriminant representations for visual recognition, cross-modal person re-identification based on different sensor modalities has become viable in many challenging applications in, e.g., autonomous driving, robotics and video surveillance. Although some methods have been proposed for re-identification between infrared and RGB images, few address depth and RGB images. In addition to the challenges for each modality associated with occlusion, clutter, misalignment, and variations in pose and illumination, there is a considerable shift across modalities since data from RGB and depth images are heterogeneous. In this paper, a new cross-modal distillation network is proposed for robust person re-identification between RGB and depth sensors. Using a two-step optimization process, the proposed method transfers supervision between modalities such that similar structural features are extracted from both RGB and depth modalities, yielding a discriminative mapping to a common feature space. Our experiments investigate the influence of the dimensionality of the embedding space, compares transfer learning from depth to RGB and vice versa, and compares against other state-of-the-art cross-modal re-identification methods. Results obtained with BIWI and RobotPKU datasets indicate that the proposed method can successfully transfer descriptive structural features from the depth modality to the RGB modality. It can significantly outperform state-of-the-art conventional methods and deep neural networks for cross-modal sensing between RGB and depth, with no impact on computational complexity.
Unsupervised Adaptive Re-identification in Open World Dynamic Camera Networks
Jun 09, 2017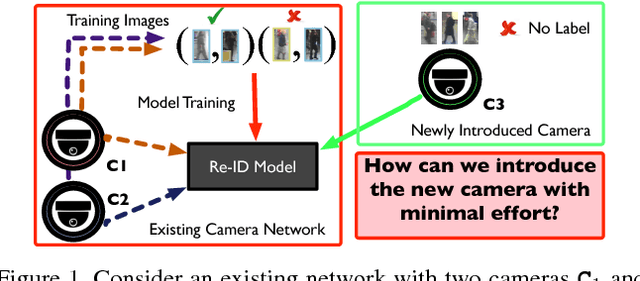
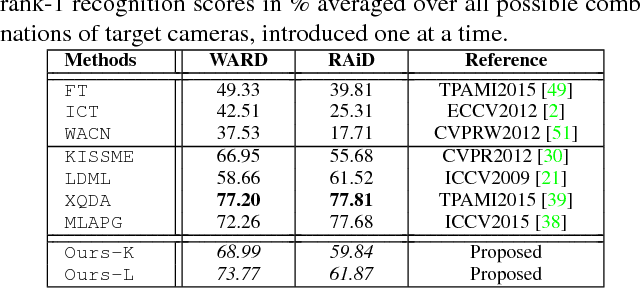
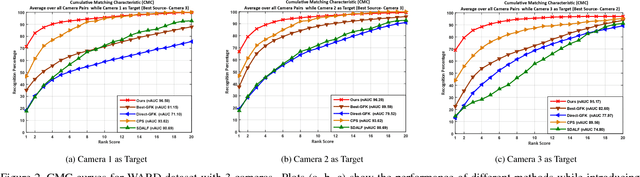
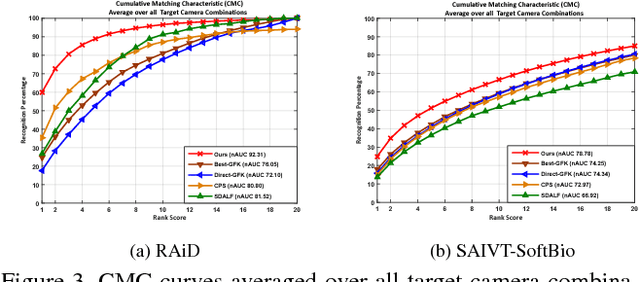
Person re-identification is an open and challenging problem in computer vision. Existing approaches have concentrated on either designing the best feature representation or learning optimal matching metrics in a static setting where the number of cameras are fixed in a network. Most approaches have neglected the dynamic and open world nature of the re-identification problem, where a new camera may be temporarily inserted into an existing system to get additional information. To address such a novel and very practical problem, we propose an unsupervised adaptation scheme for re-identification models in a dynamic camera network. First, we formulate a domain perceptive re-identification method based on geodesic flow kernel that can effectively find the best source camera (already installed) to adapt with a newly introduced target camera, without requiring a very expensive training phase. Second, we introduce a transitive inference algorithm for re-identification that can exploit the information from best source camera to improve the accuracy across other camera pairs in a network of multiple cameras. Extensive experiments on four benchmark datasets demonstrate that the proposed approach significantly outperforms the state-of-the-art unsupervised learning based alternatives whilst being extremely efficient to compute.