 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross-Modal Distillation Network for Person Re-identification in RGB-Depth
Paper and Code
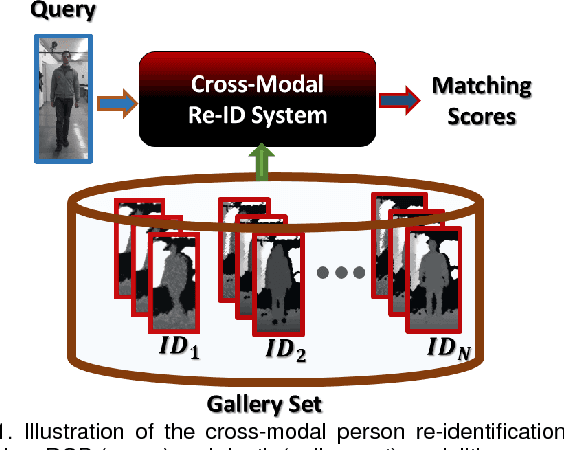
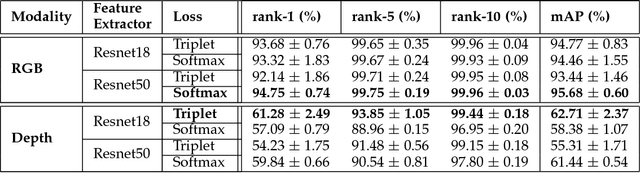
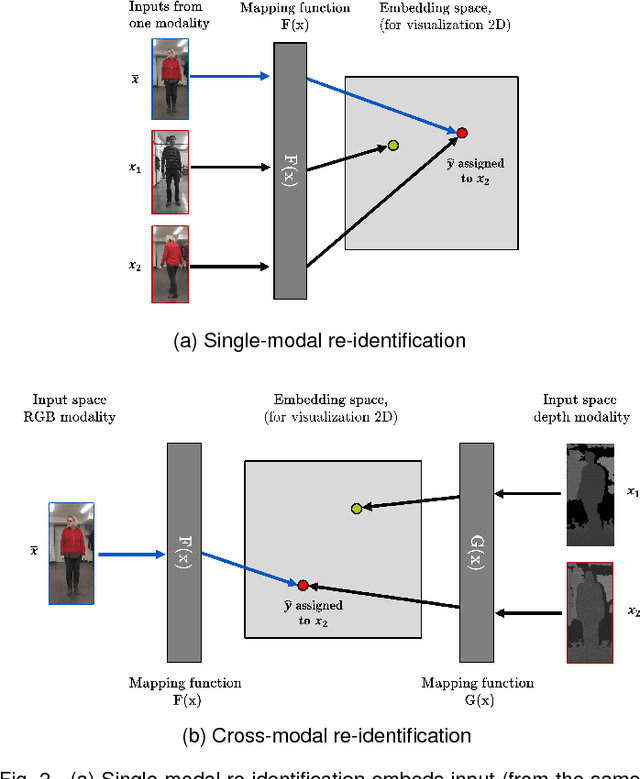
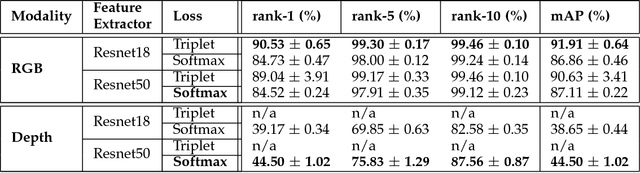
Person re-identification involves the recognition over time of individuals captured using multiple distributed sensors. With the advent of powerful deep learning methods able to learn discriminant representations for visual recognition, cross-modal person re-identification based on different sensor modalities has become viable in many challenging applications in, e.g., autonomous driving, robotics and video surveillance. Although some methods have been proposed for re-identification between infrared and RGB images, few address depth and RGB images. In addition to the challenges for each modality associated with occlusion, clutter, misalignment, and variations in pose and illumination, there is a considerable shift across modalities since data from RGB and depth images are heterogeneous. In this paper, a new cross-modal distillation network is proposed for robust person re-identification between RGB and depth sensors. Using a two-step optimization process, the proposed method transfers supervision between modalities such that similar structural features are extracted from both RGB and depth modalities, yielding a discriminative mapping to a common feature space. Our experiments investigate the influence of the dimensionality of the embedding space, compares transfer learning from depth to RGB and vice versa, and compares against other state-of-the-art cross-modal re-identification methods. Results obtained with BIWI and RobotPKU datasets indicate that the proposed method can successfully transfer descriptive structural features from the depth modality to the RGB modality. It can significantly outperform state-of-the-art conventional methods and deep neural networks for cross-modal sensing between RGB and depth, with no impact on computational complexity.