 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Matching Related Objects with One Proposal Multiple Predictions
Apr 23, 2021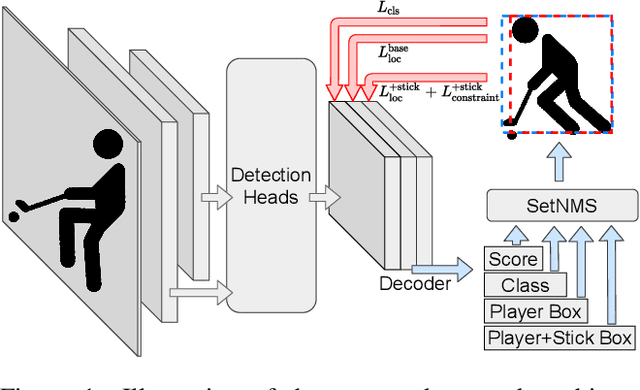
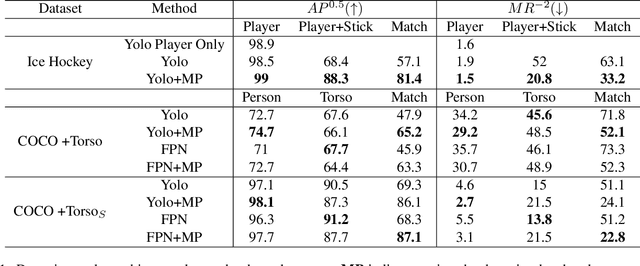
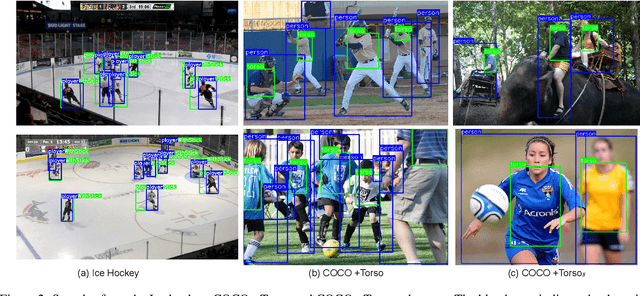
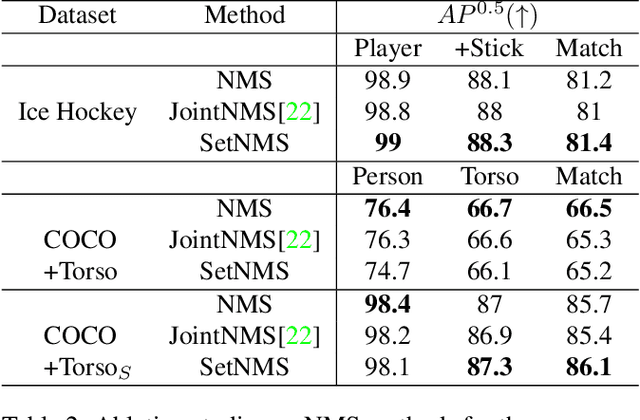
Tracking players in sports videos is commonly done in a tracking-by-detection framework, first detecting players in each frame, and then performing association over time. While for some sports tracking players is sufficient for game analysis, sports like hockey, tennis and polo may require additional detections, that include the object the player is holding (e.g. racket, stick). The baseline solution for this problem involves detecting these objects as separate classes, and matching them to player detections based on the intersection over union (IoU). This approach, however, leads to poor matching performance in crowded situations, as it does not model the relationship between players and objects. In this paper, we propose a simple yet efficient way to detect and match players and related objects at once without extra cost, by considering an implicit association for prediction of multiple objects through the same proposal box. We evaluate the method on a dataset of broadcast ice hockey videos, and also a new public dataset we introduce called COCO +Torso. On the ice hockey dataset, the proposed method boosts matching performance from 57.1% to 81.4%, while also improving the meanAP of player+stick detections from 68.4% to 88.3%. On the COCO +Torso dataset, we see matching improving from 47.9% to 65.2%. The COCO +Torso dataset, code and pre-trained models will be released at https://github.com/foreverYoungGitHub/detect-and-match-related-objects.
Player Identification in Hockey Broadcast Videos
Sep 14, 2020



We present a deep recurrent convolutional neural network (CNN) approach to solve the problem of hockey player identification in NHL broadcast videos. Player identification is a difficult computer vision problem mainly because of the players' similar appearance, occlusion, and blurry facial and physical features. However, we can observe players' jersey numbers over time by processing variable length image sequences of players (aka 'tracklets'). We propose an end-to-end trainable ResNet+LSTM network, with a residual network (ResNet) base and a long short-term memory (LSTM) layer, to discover spatio-temporal features of jersey numbers over time and learn long-term dependencies. For this work, we created a new hockey player tracklet dataset that contains sequences of hockey player bounding boxes. Additionally, we employ a secondary 1-dimensional convolutional neural network classifier as a late score-level fusion method to classify the output of the ResNet+LSTM network. This achieves an overall player identification accuracy score over 87% on the test split of our new dataset.
Flow-Guided Attention Networks for Video-Based Person Re-Identification
Aug 09, 2020
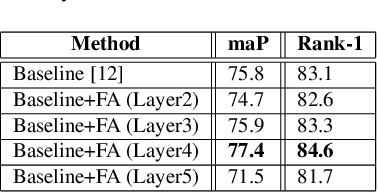

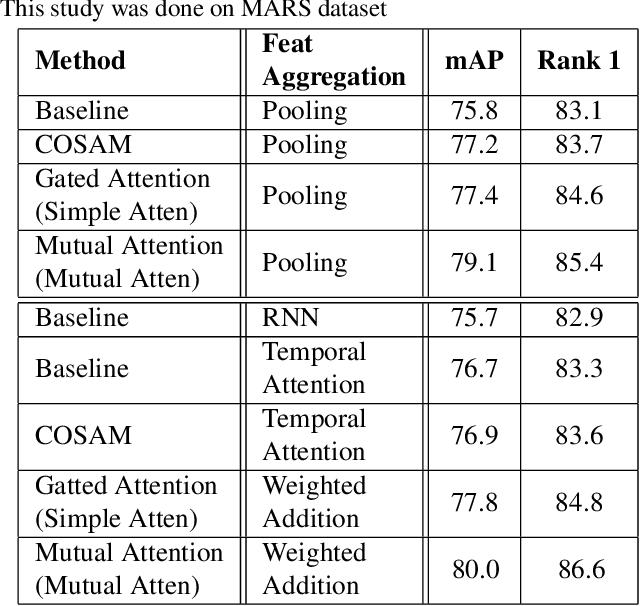
Person Re-Identification (ReID) is an important problem in many video analytics and surveillance applications,where a person's identity must be associated across a distributed network of cameras. Video-based person ReID has recently gained much interest because it can capture discriminant spatio-temporal information that is unavailable for image-based ReID. Despite recent advances, deep learning models for video ReID often fail to leverage this information to improve the robustness of feature representations. In this paper, the motion pattern of a person is explored as an additional cue for ReID. In particular, two different flow-guided attention networks are proposed for fusion with any 2D-CNN backbone, allowing to encode temporal information along with spatial appearance information.Our first proposed network called Gated Attention relies on optical flow to generate gated attention with video-based feature that embed spatially. Hence the proposed framework allows to activate a common set of salient features across multiple frames. In contrast, our second network called Mutual Attention relies on the joint attention between image and optical flow features. This enables spatial attention between both sources of features, across motion and appearance cues. Both methods introduce a feature aggregation method that produce video features by identifying salient spatio-temporal information.Extensive experiments on two challenging video datasets indicate that using the proposed flow-guided spatio-temporal attention networks allows to improve recognition accuracy considerably, outperforming state-of-the-art methods for video-based person ReID. Additionally, our Mutual Attention network is able to process longer frame sequences with a wider range of appearance variations for highly accurate recognition.
Group Activity Detection from Trajectory and Video Data in Soccer
Apr 21, 2020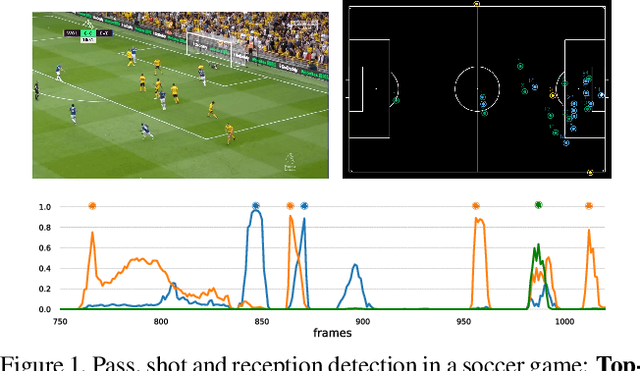
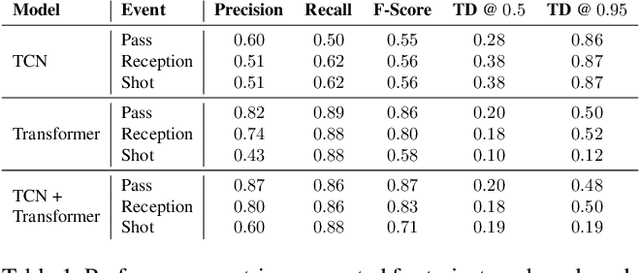
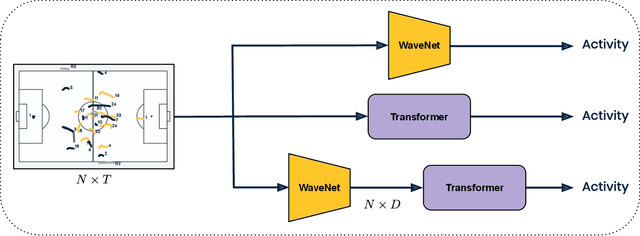
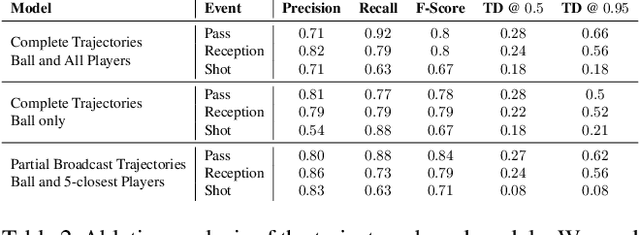
Group activity detection in soccer can be done by using either video data or player and ball trajectory data. In current soccer activity datasets, activities are labelled as atomic events without a duration. Given that the state-of-the-art activity detection methods are not well-defined for atomic actions, these methods cannot be used. In this work, we evaluated the effectiveness of activity recognition models for detecting such events, by using an intuitive non-maximum suppression process and evaluation metrics. We also considered the problem of explicitly modeling interactions between players and ball. For this, we propose self-attention models to learn and extract relevant information from a group of soccer players for activity detection from both trajectory and video data. We conducted an extensive study on the use of visual features and trajectory data for group activity detection in sports using a large scale soccer dataset provided by Sportlogiq. Our results show that most events can be detected using either vision or trajectory-based approaches with a temporal resolution of less than 0.5 seconds, and that each approach has unique challenges.
Actor-Transformers for Group Activity Recognition
Mar 28, 2020
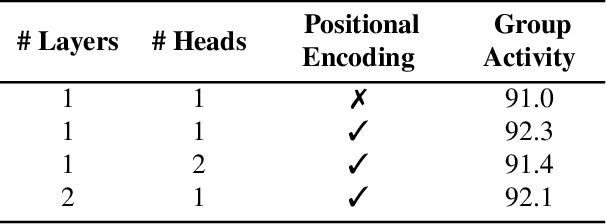
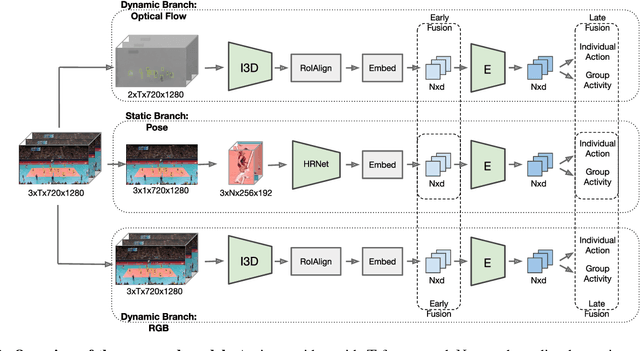
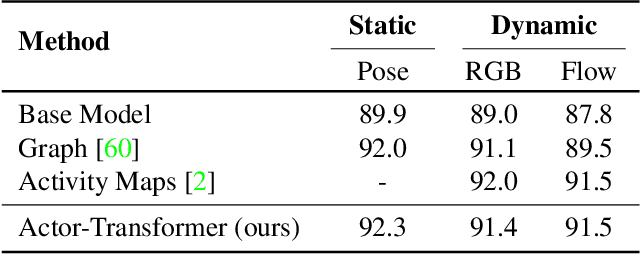
This paper strives to recognize individual actions and group activities from videos. While existing solutions for this challenging problem explicitly model spatial and temporal relationships based on location of individual actors, we propose an actor-transformer model able to learn and selectively extract information relevant for group activity recognition. We feed the transformer with rich actor-specific static and dynamic representations expressed by features from a 2D pose network and 3D CNN, respectively. We empirically study different ways to combine these representations and show their complementary benefits. Experiments show what is important to transform and how it should be transformed. What is more, actor-transformers achieve state-of-the-art results on two publicly available benchmarks for group activity recognition, outperforming the previous best published results by a considerable margin.
Optimizing Through Learned Errors for Accurate Sports Field Registration
Sep 17, 2019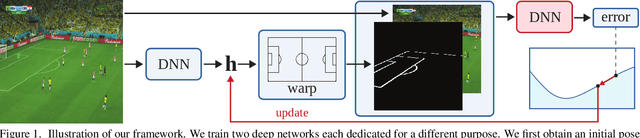
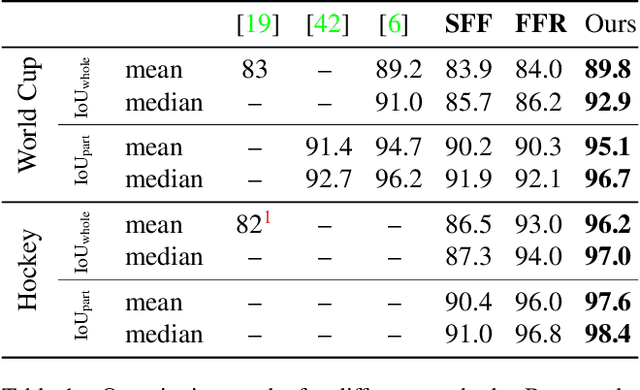
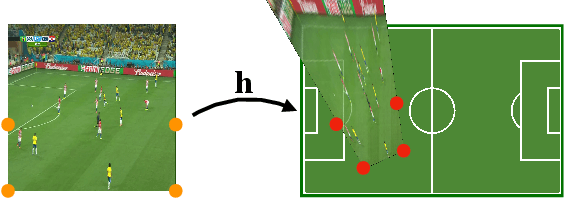
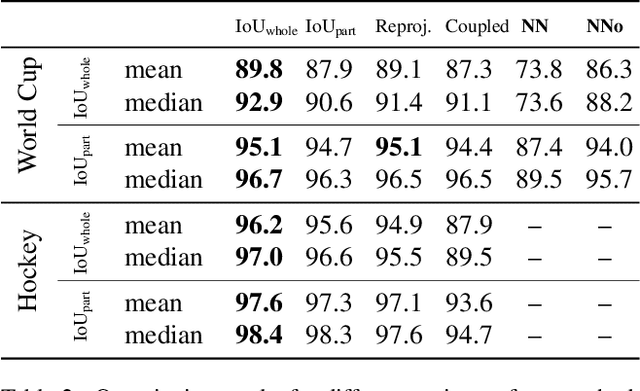
We propose an optimization-based framework to register sports field templates onto broadcast videos. For accurate registration we go beyond the prevalent feed-forward paradigm. Instead, we propose to train a deep network that regresses the registration error, and then register images by finding the registration parameters that minimize the regressed error. We demonstrate the effectiveness of our method by applying it to real-world sports broadcast videos, outperforming the state of the art. We further apply our method on a synthetic toy example and demonstrate that our method brings significant gains even when the problem is simplified and unlimited training data is available.
A Survey of Pruning Methods for Efficient Person Re-identification Across Domains
Jul 04, 2019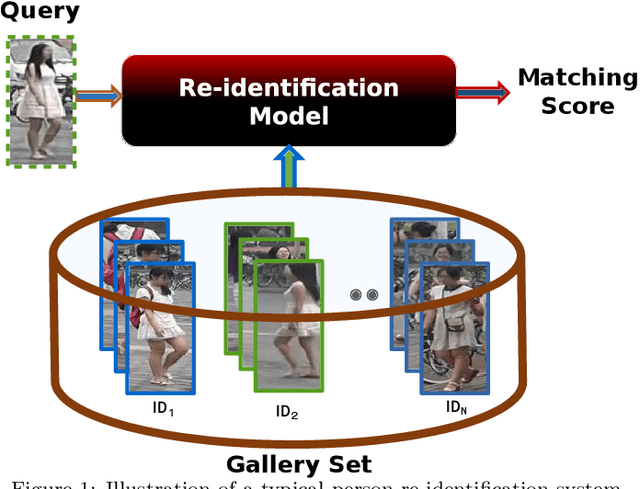
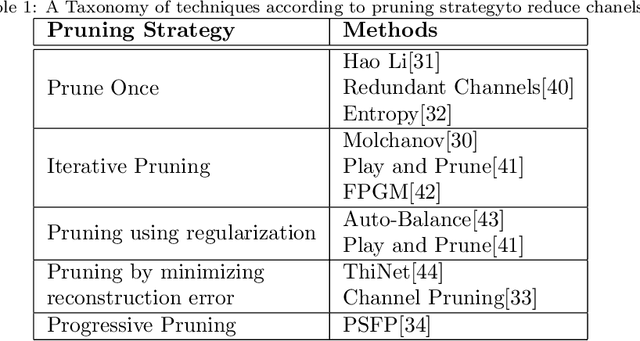
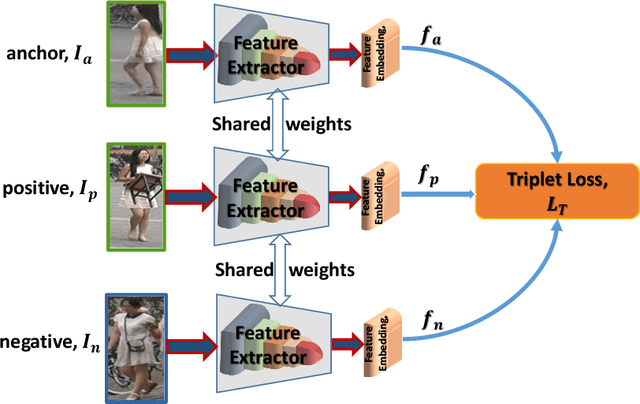
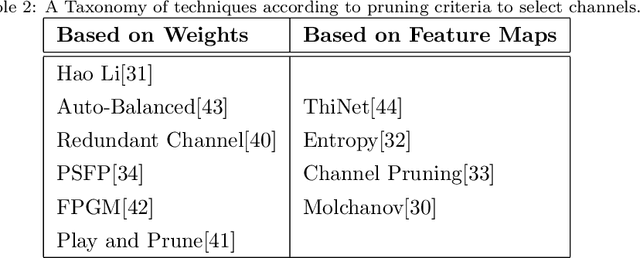
Recent years have witnessed a substantial increase in the deep learning architectures proposed for visual recognition tasks like person re-identification, where individuals must be recognized over multiple distributed cameras. Although deep Siamese networks have greatly improved the state-of-the-art accuracy, the computational complexity of the CNNs used for feature extraction remains an issue, hindering their deployment on platforms with with limited resources, or in applications with real-time constraints. Thus, there is an obvious advantage to compressing these architectures without significantly decreasing their accuracy. This paper provides a survey of state-of-the-art pruning techniques that are suitable for compressing deep Siamese networks applied to person re-identification. These techniques are analysed according to their pruning criteria and strategy, and according to different design scenarios for exploiting pruning methods to fine-tuning networks for target applications. Experimental results obtained using Siamese networks with ResNet feature extractors, and multiple benchmarks re-identification datasets, indicate that pruning can considerably reduce network complexity while maintaining a high level of accuracy. In scenarios where pruning is performed with large pre-training or fine-tuning datasets, the number of FLOPS required by the ResNet feature extractor is reduced by half, while maintaining a comparable rank-1 accuracy (within 1\% of the original model). Pruning while training a larger CNNs can also provide a significantly better performance than fine-tuning smaller ones.