 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Matching Related Objects with One Proposal Multiple Predictions
Apr 23, 2021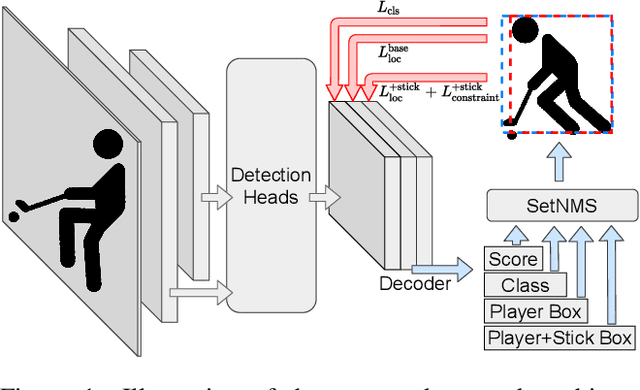
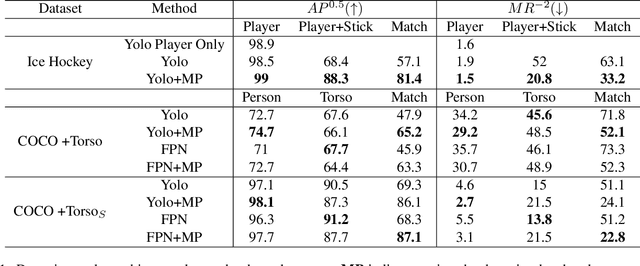
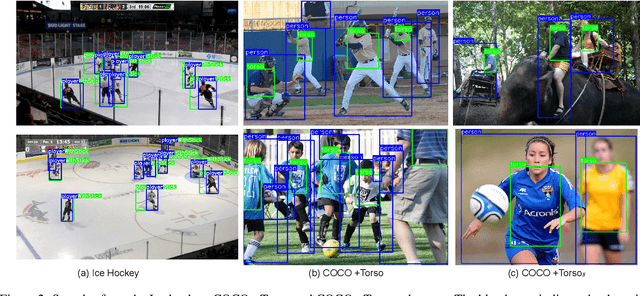
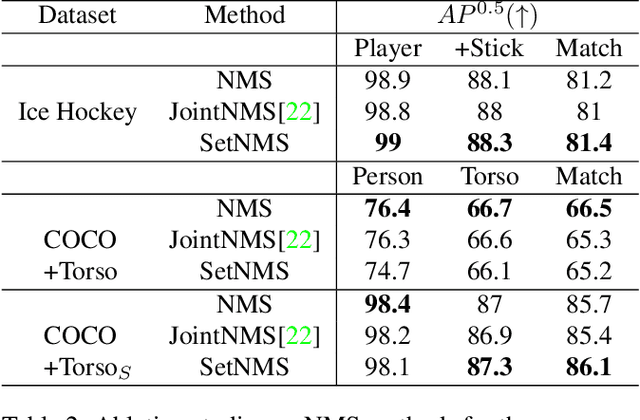
Tracking players in sports videos is commonly done in a tracking-by-detection framework, first detecting players in each frame, and then performing association over time. While for some sports tracking players is sufficient for game analysis, sports like hockey, tennis and polo may require additional detections, that include the object the player is holding (e.g. racket, stick). The baseline solution for this problem involves detecting these objects as separate classes, and matching them to player detections based on the intersection over union (IoU). This approach, however, leads to poor matching performance in crowded situations, as it does not model the relationship between players and objects. In this paper, we propose a simple yet efficient way to detect and match players and related objects at once without extra cost, by considering an implicit association for prediction of multiple objects through the same proposal box. We evaluate the method on a dataset of broadcast ice hockey videos, and also a new public dataset we introduce called COCO +Torso. On the ice hockey dataset, the proposed method boosts matching performance from 57.1% to 81.4%, while also improving the meanAP of player+stick detections from 68.4% to 88.3%. On the COCO +Torso dataset, we see matching improving from 47.9% to 65.2%. The COCO +Torso dataset, code and pre-trained models will be released at https://github.com/foreverYoungGitHub/detect-and-match-related-objects.
An Evaluation of Deep CNN Baselines for Scene-Independent Person Re-Identification
May 16, 2018
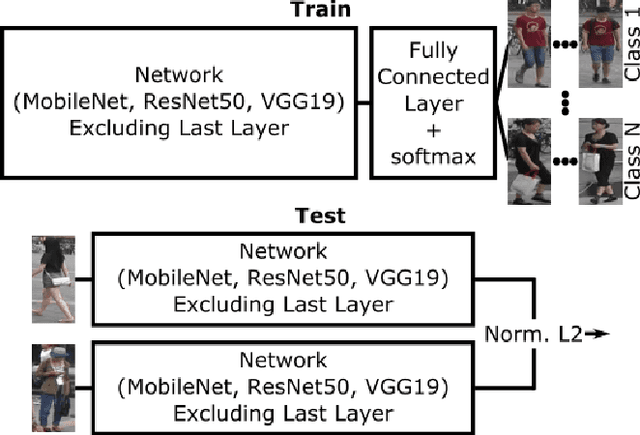

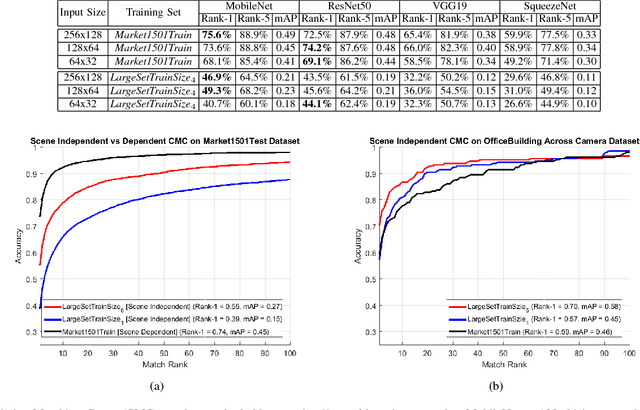
In recent years, a variety of proposed methods based on deep convolutional neural networks (CNNs) have improved the state of the art for large-scale person re-identification (ReID). While a large number of optimizations and network improvements have been proposed, there has been relatively little evaluation of the influence of training data and baseline network architecture. In particular, it is usually assumed either that networks are trained on labeled data from the deployment location (scene-dependent), or else adapted with unlabeled data, both of which complicate system deployment. In this paper, we investigate the feasibility of achieving scene-independent person ReID by forming a large composite dataset for training. We present an in-depth comparison of several CNN baseline architectures for both scene-dependent and scene-independent ReID, across a range of training dataset sizes. We show that scene-independent ReID can produce leading-edge results, competitive with unsupervised domain adaption techniques. Finally, we introduce a new dataset for comparing within-camera and across-camera person ReID.