 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Matching Related Objects with One Proposal Multiple Predictions
Apr 23, 2021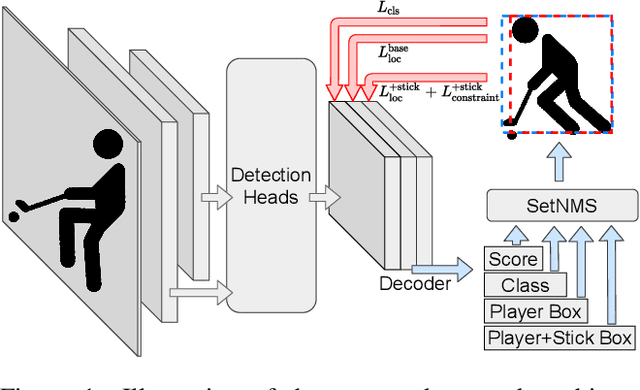
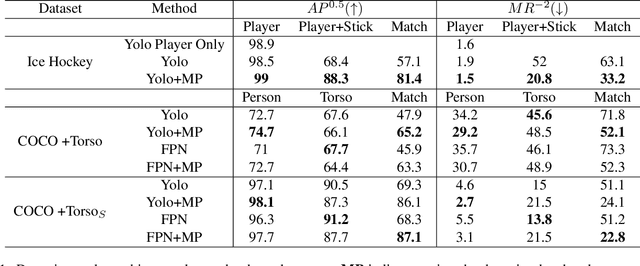
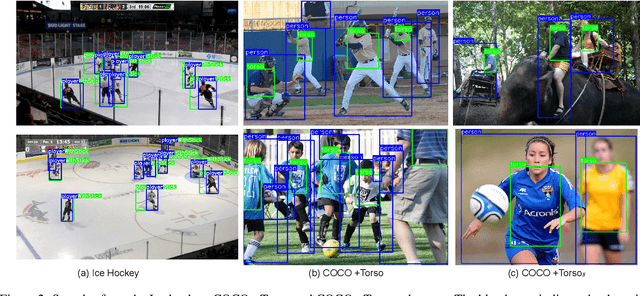
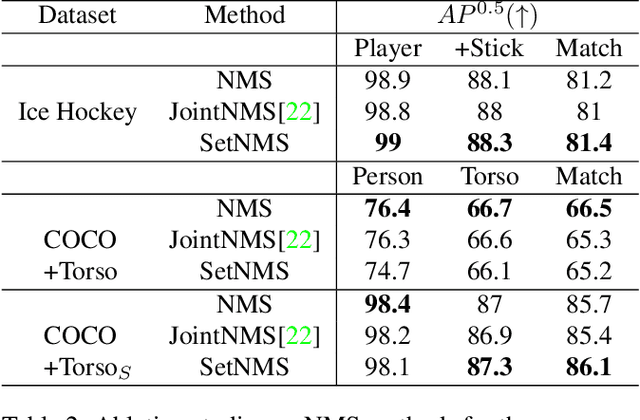
Tracking players in sports videos is commonly done in a tracking-by-detection framework, first detecting players in each frame, and then performing association over time. While for some sports tracking players is sufficient for game analysis, sports like hockey, tennis and polo may require additional detections, that include the object the player is holding (e.g. racket, stick). The baseline solution for this problem involves detecting these objects as separate classes, and matching them to player detections based on the intersection over union (IoU). This approach, however, leads to poor matching performance in crowded situations, as it does not model the relationship between players and objects. In this paper, we propose a simple yet efficient way to detect and match players and related objects at once without extra cost, by considering an implicit association for prediction of multiple objects through the same proposal box. We evaluate the method on a dataset of broadcast ice hockey videos, and also a new public dataset we introduce called COCO +Torso. On the ice hockey dataset, the proposed method boosts matching performance from 57.1% to 81.4%, while also improving the meanAP of player+stick detections from 68.4% to 88.3%. On the COCO +Torso dataset, we see matching improving from 47.9% to 65.2%. The COCO +Torso dataset, code and pre-trained models will be released at https://github.com/foreverYoungGitHub/detect-and-match-related-objects.
Group Activity Detection from Trajectory and Video Data in Soccer
Apr 21, 2020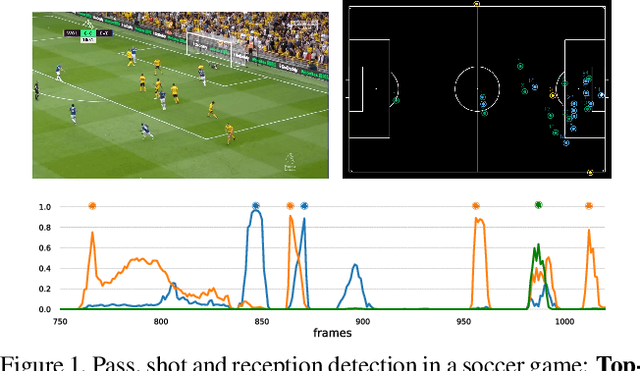
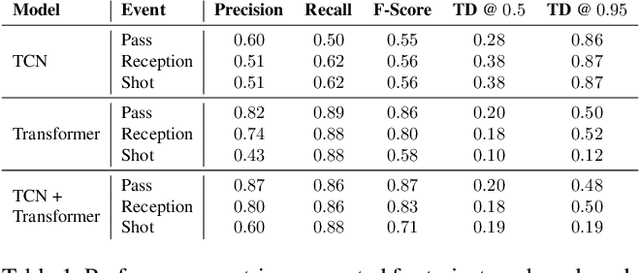
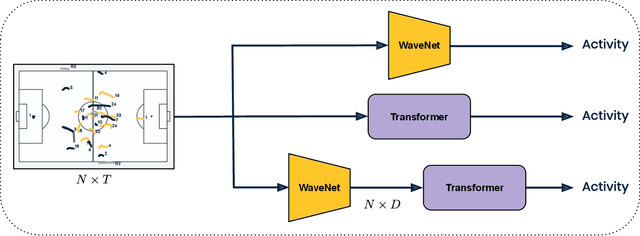
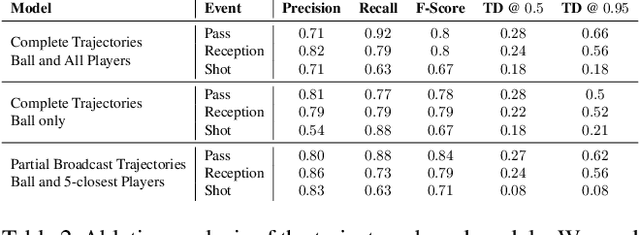
Group activity detection in soccer can be done by using either video data or player and ball trajectory data. In current soccer activity datasets, activities are labelled as atomic events without a duration. Given that the state-of-the-art activity detection methods are not well-defined for atomic actions, these methods cannot be used. In this work, we evaluated the effectiveness of activity recognition models for detecting such events, by using an intuitive non-maximum suppression process and evaluation metrics. We also considered the problem of explicitly modeling interactions between players and ball. For this, we propose self-attention models to learn and extract relevant information from a group of soccer players for activity detection from both trajectory and video data. We conducted an extensive study on the use of visual features and trajectory data for group activity detection in sports using a large scale soccer dataset provided by Sportlogiq. Our results show that most events can be detected using either vision or trajectory-based approaches with a temporal resolution of less than 0.5 seconds, and that each approach has unique challenges.
Meta-learning for fast classifier adaptation to new users of Signature Verification systems
Oct 17, 2019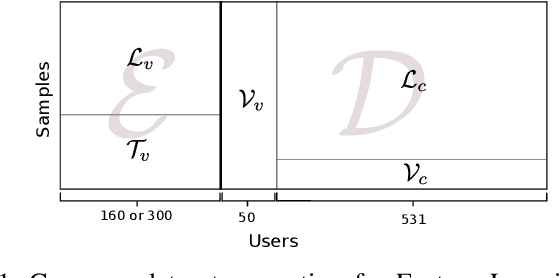
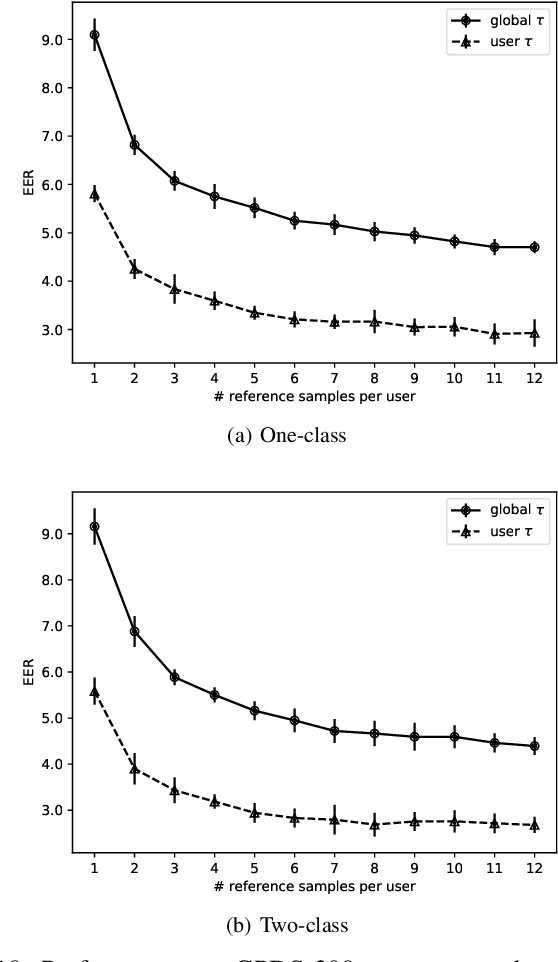


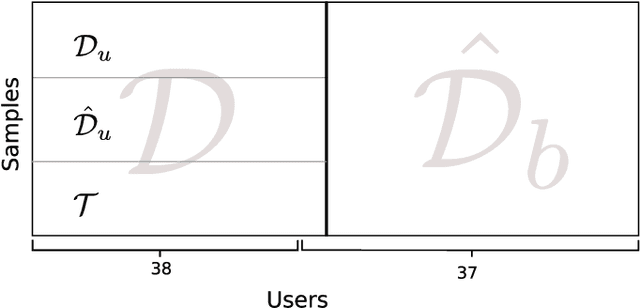
Offline Handwritten Signature verification presents a challenging Pattern Recognition problem, where only knowledge of the positive class is available for training. While classifiers have access to a few genuine signatures for training, during generalization they also need to discriminate forgeries. This is particularly challenging for skilled forgeries, where a forger practices imitating the user's signature, and often is able to create forgeries visually close to the original signatures. Most work in the literature address this issue by training for a surrogate objective: discriminating genuine signatures of a user and random forgeries (signatures from other users). In this work, we propose a solution for this problem based on meta-learning, where there are two levels of learning: a task-level (where a task is to learn a classifier for a given user) and a meta-level (learning across tasks). In particular, the meta-learner guides the adaptation (learning) of a classifier for each user, which is a lightweight operation that only requires genuine signatures. The meta-learning procedure learns what is common for the classification across different users. In a scenario where skilled forgeries from a subset of users are available, the meta-learner can guide classifiers to be discriminative of skilled forgeries even if the classifiers themselves do not use skilled forgeries for learning. Experiments conducted on the GPDS-960 dataset show improved performance compared to Writer-Independent systems, and achieve results comparable to state-of-the-art Writer-Dependent systems in the regime of few samples per user (5 reference signatures).
Universal Adversarial Audio Perturbations
Aug 12, 2019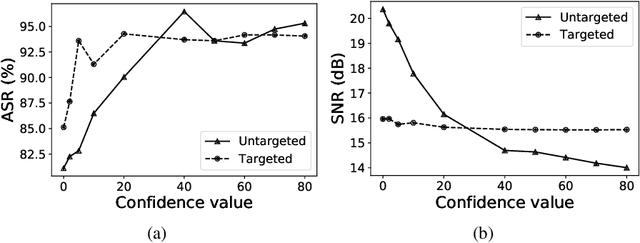
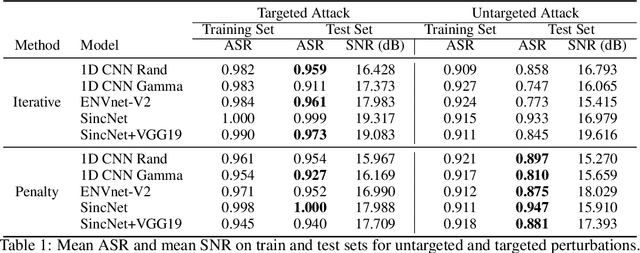
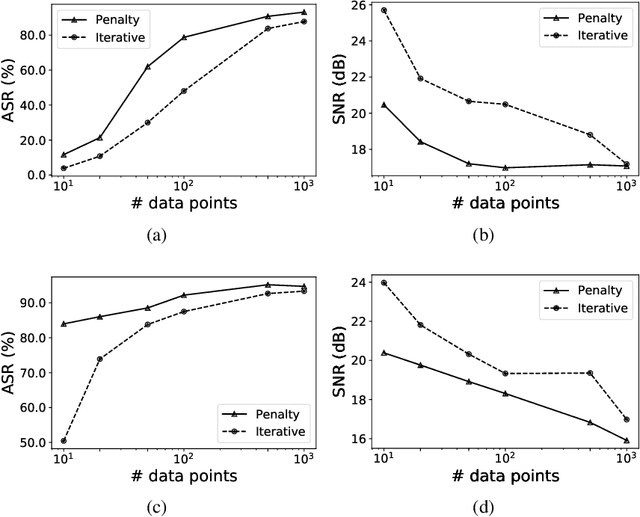
We demonstrate the existence of universal adversarial perturbations, which can fool a family of audio processing architectures, for both targeted and untargeted attacks. To the best of our knowledge, this is the first study on generating universal adversarial perturbations for audio processing systems. We propose two methods for finding such perturbations. The first method is based on an iterative, greedy approach that is well-known in computer vision: it aggregates small perturbations to the input so as to push it to the decision boundary. The second method, which is the main technical contribution of this work, is a novel penalty formulation, which finds targeted and untargeted universal adversarial perturbations. Differently from the greedy approach, the penalty method minimizes an appropriate objective function on a batch of samples. Therefore, it produces more successful attacks when the number of training samples is limited. Moreover, we provide a proof that the proposed penalty method theoretically converges to a solution that corresponds to universal adversarial perturbations. We report comprehensive experiments, showing attack success rates higher than 91.1% and 74.7% for targeted and untargeted attacks, respectively.
Characterizing and evaluating adversarial examples for Offline Handwritten Signature Verification
Jan 10, 2019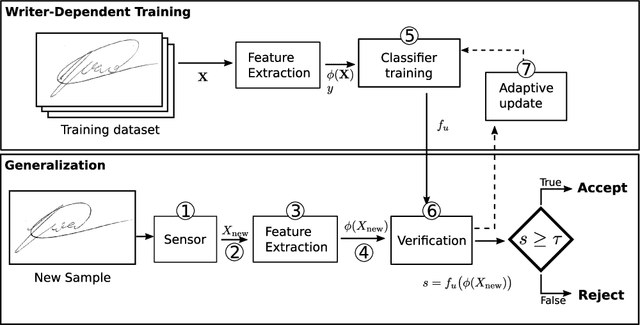
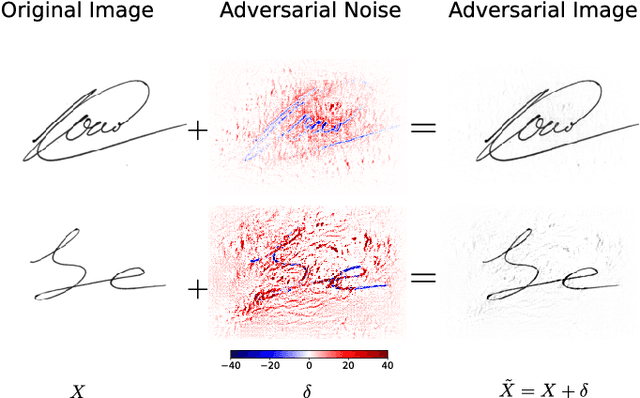

The phenomenon of Adversarial Examples is attracting increasing interest from the Machine Learning community, due to its significant impact to the security of Machine Learning systems. Adversarial examples are similar (from a perceptual notion of similarity) to samples from the data distribution, that "fool" a machine learning classifier. For computer vision applications, these are images with carefully crafted but almost imperceptible changes, that are misclassified. In this work, we characterize this phenomenon under an existing taxonomy of threats to biometric systems, in particular identifying new attacks for Offline Handwritten Signature Verification systems. We conducted an extensive set of experiments on four widely used datasets: MCYT-75, CEDAR, GPDS-160 and the Brazilian PUC-PR, considering both a CNN-based system and a system using a handcrafted feature extractor (CLBP). We found that attacks that aim to get a genuine signature rejected are easy to generate, even in a limited knowledge scenario, where the attacker does not have access to the trained classifier nor the signatures used for training. Attacks that get a forgery to be accepted are harder to produce, and often require a higher level of noise - in most cases, no longer "imperceptible" as previous findings in object recognition. We also evaluated the impact of two countermeasures on the success rate of the attacks and the amount of noise required for generating successful attacks.
Decoupling Direction and Norm for Efficient Gradient-Based L2 Adversarial Attacks and Defenses
Nov 26, 2018
Research on adversarial examples in computer vision tasks has shown that small, often imperceptible changes to an image can induce misclassification, which has security implications for a wide range of image processing systems. Considering $L_2$ norm distortions, the Carlini and Wagner attack is presently the most effective white-box attack in the literature. However, this method is slow since it performs a line-search for one of the optimization terms, and often requires thousands of iterations. In this paper, an efficient approach is proposed to generate gradient-based attacks that induce misclassifications with low $L_2$ norm, by decoupling the direction and the norm of the adversarial perturbation that is added to the image. Experiments conducted on the MNIST, CIFAR-10 and ImageNet datasets indicate that our attack achieves comparable results to the state-of-the-art (in terms of $L_2$ norm) with considerably fewer iterations (as few as 100 iterations), which opens the possibility of using these attacks for adversarial training. Models trained with our attack achieve state-of-the-art robustness against white-box gradient-based $L_2$ attacks on the MNIST and CIFAR-10 datasets, outperforming the Madry defense when the attacks are limited to a maximum norm.
Fixed-sized representation learning from Offline Handwritten Signatures of different sizes
Apr 24, 2018
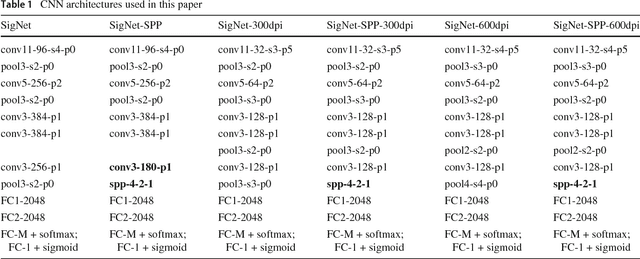
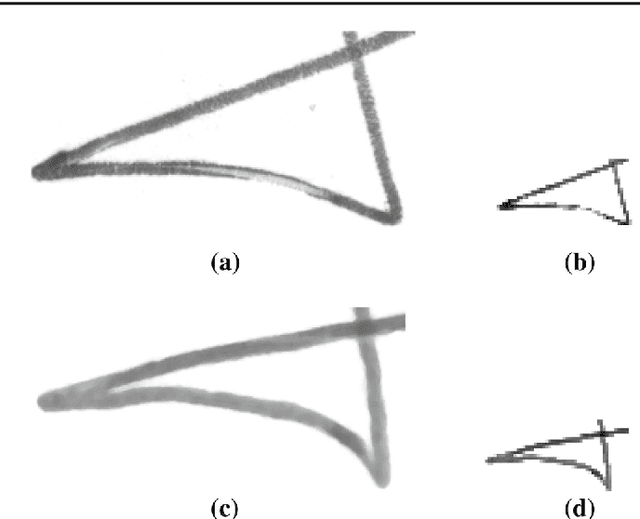
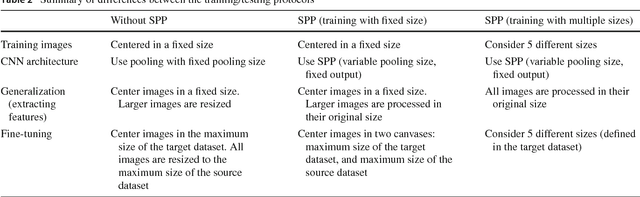
Methods for learning feature representations for Offline Handwritten Signature Verification have been successfully proposed in recent literature, using Deep Convolutional Neural Networks to learn representations from signature pixels. Such methods reported large performance improvements compared to handcrafted feature extractors. However, they also introduced an important constraint: the inputs to the neural networks must have a fixed size, while signatures vary significantly in size between different users. In this paper we propose addressing this issue by learning a fixed-sized representation from variable-sized signatures by modifying the network architecture, using Spatial Pyramid Pooling. We also investigate the impact of the resolution of the images used for training, and the impact of adapting (fine-tuning) the representations to new operating conditions (different acquisition protocols, such as writing instruments and scan resolution). On the GPDS dataset, we achieve results comparable with the state-of-the-art, while removing the constraint of having a maximum size for the signatures to be processed. We also show that using higher resolutions (300 or 600dpi) can improve performance when skilled forgeries from a subset of users are available for feature learning, but lower resolutions (around 100dpi) can be used if only genuine signatures are used. Lastly, we show that fine-tuning can improve performance when the operating conditions change.
DESlib: A Dynamic ensemble selection library in Python
Feb 16, 2018

DESlib is an open-source python library providing the implementation of several dynamic selection techniques. The library is divided into three modules: (i) dcs, containing the implementation of dynamic classifier selection methods (DCS); (ii) des, containing the implementation of dynamic ensemble selection methods (DES); (iii) static, with the implementation of static ensemble techniques. The library is fully documented (documentation available online on Read the Docs), with a high test coverage (cover.io) as well as code quality (Landscape). Documentation, code and examples can be found on its GitHub page: https://github.com/Menelau/DESlib.
Offline Handwritten Signature Verification - Literature Review
Oct 16, 2017
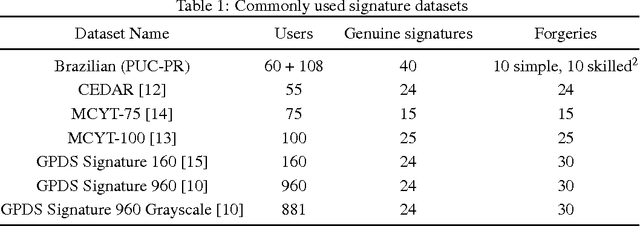

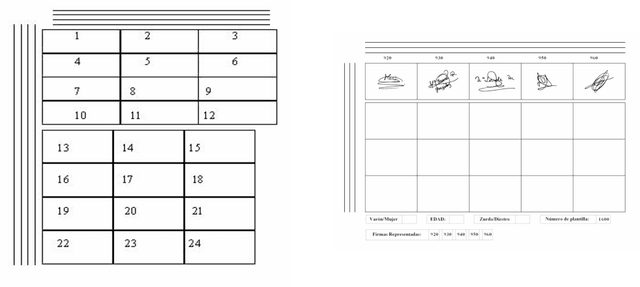
The area of Handwritten Signature Verification has been broadly researched in the last decades, but remains an open research problem. The objective of signature verification systems is to discriminate if a given signature is genuine (produced by the claimed individual), or a forgery (produced by an impostor). This has demonstrated to be a challenging task, in particular in the offline (static) scenario, that uses images of scanned signatures, where the dynamic information about the signing process is not available. Many advancements have been proposed in the literature in the last 5-10 years, most notably the application of Deep Learning methods to learn feature representations from signature images. In this paper, we present how the problem has been handled in the past few decades, analyze the recent advancements in the field, and the potential directions for future research.
Learning Features for Offline Handwritten Signature Verification using Deep Convolutional Neural Networks
May 16, 2017
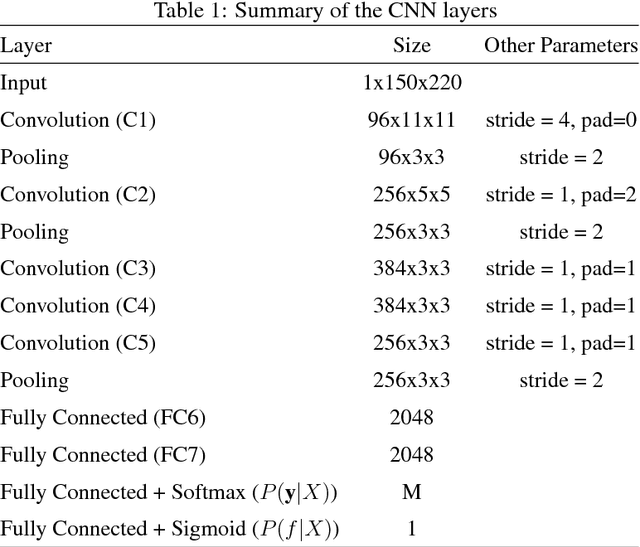
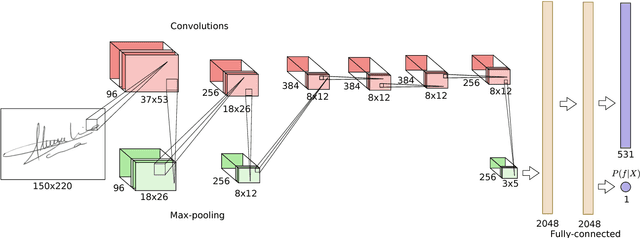

Verifying the identity of a person using handwritten signatures is challenging in the presence of skilled forgeries, where a forger has access to a person's signature and deliberately attempt to imitate it. In offline (static) signature verification, the dynamic information of the signature writing process is lost, and it is difficult to design good feature extractors that can distinguish genuine signatures and skilled forgeries. This reflects in a relatively poor performance, with verification errors around 7% in the best systems in the literature. To address both the difficulty of obtaining good features, as well as improve system performance, we propose learning the representations from signature images, in a Writer-Independent format, using Convolutional Neural Networks. In particular, we propose a novel formulation of the problem that includes knowledge of skilled forgeries from a subset of users in the feature learning process, that aims to capture visual cues that distinguish genuine signatures and forgeries regardless of the user. Extensive experiments were conducted on four datasets: GPDS, MCYT, CEDAR and Brazilian PUC-PR datasets. On GPDS-160, we obtained a large improvement in state-of-the-art performance, achieving 1.72% Equal Error Rate, compared to 6.97% in the literature. We also verified that the features generalize beyond the GPDS dataset, surpassing the state-of-the-art performance in the other datasets, without requiring the representation to be fine-tuned to each particular dataset.