 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIPES: A Meta-dataset of Machine Learning Pipelines
Sep 11, 2025Solutions to the Algorithm Selection Problem (ASP) in machine learning face the challenge of high computational costs associated with evaluating various algorithms' performances on a given dataset. To mitigate this cost, the meta-learning field can leverage previously executed experiments shared in online repositories such as OpenML. OpenML provides an extensive collection of machine learning experiments. However, an analysis of OpenML's records reveals limitations. It lacks diversity in pipelines, specifically when exploring data preprocessing steps/blocks, such as scaling or imputation, resulting in limited representation. Its experiments are often focused on a few popular techniques within each pipeline block, leading to an imbalanced sample. To overcome the observed limitations of OpenML, we propose PIPES, a collection of experiments involving multiple pipelines designed to represent all combinations of the selected sets of techniques, aiming at diversity and completeness. PIPES stores the results of experiments performed applying 9,408 pipelines to 300 datasets. It includes detailed information on the pipeline blocks, training and testing times, predictions, performances, and the eventual error messages. This comprehensive collection of results allows researchers to perform analyses across diverse and representative pipelines and datasets. PIPES also offers potential for expansion, as additional data and experiments can be incorporated to support the meta-learning community further. The data, code, supplementary material, and all experiments can be found at https://github.com/cynthiamaia/PIPES.git.
Resampling strategies for imbalanced regression: a survey and empirical analysis
Jul 16, 2025Imbalanced problems can arise in different real-world situations, and to address this, certain strategies in the form of resampling or balancing algorithms are proposed. This issue has largely been studied in the context of classification, and yet, the same problem features in regression tasks, where target values are continuous. This work presents an extensive experimental study comprising various balancing and predictive models, and wich uses metrics to capture important elements for the user and to evaluate the predictive model in an imbalanced regression data context. It also proposes a taxonomy for imbalanced regression approaches based on three crucial criteria: regression model, learning process, and evaluation metrics. The study offers new insights into the use of such strategies, highlighting the advantages they bring to each model's learning process, and indicating directions for further studies. The code, data and further information related to the experiments performed herein can be found on GitHub: https://github.com/JusciAvelino/imbalancedRegression.
Imbalanced Regression Pipeline Recommendation
Jul 16, 2025Imbalanced problems are prevalent in various real-world scenarios and are extensively explored in classification tasks. However, they also present challenges for regression tasks due to the rarity of certain target values. A common alternative is to employ balancing algorithms in preprocessing to address dataset imbalance. However, due to the variety of resampling methods and learning models, determining the optimal solution requires testing many combinations. Furthermore, the learning model, dataset, and evaluation metric affect the best strategies. This work proposes the Meta-learning for Imbalanced Regression (Meta-IR) framework, which diverges from existing literature by training meta-classifiers to recommend the best pipeline composed of the resampling strategy and learning model per task in a zero-shot fashion. The meta-classifiers are trained using a set of meta-features to learn how to map the meta-features to the classes indicating the best pipeline. We propose two formulations: Independent and Chained. Independent trains the meta-classifiers to separately indicate the best learning algorithm and resampling strategy. Chained involves a sequential procedure where the output of one meta-classifier is used as input for another to model intrinsic relationship factors. The Chained scenario showed superior performance, suggesting a relationship between the learning algorithm and the resampling strategy per task. Compared with AutoML frameworks, Meta-IR obtained better results. Moreover, compared with baselines of six learning algorithms and six resampling algorithms plus no resampling, totaling 42 (6 X 7) configurations, Meta-IR outperformed all of them. The code, data, and further information of the experiments can be found on GitHub: https://github.com/JusciAvelino/Meta-IR.
Multi-view autoencoders for Fake News Detection
Apr 10, 2025Given the volume and speed at which fake news spreads across social media, automatic fake news detection has become a highly important task. However, this task presents several challenges, including extracting textual features that contain relevant information about fake news. Research about fake news detection shows that no single feature extraction technique consistently outperforms the others across all scenarios. Nevertheless, different feature extraction techniques can provide complementary information about the textual data and enable a more comprehensive representation of the content. This paper proposes using multi-view autoencoders to generate a joint feature representation for fake news detection by integrating several feature extraction techniques commonly used in the literature. Experiments on fake news datasets show a significant improvement in classification performance compared to individual views (feature representations). We also observed that selecting a subset of the views instead of composing a latent space with all the views can be advantageous in terms of accuracy and computational effort. For further details, including source codes, figures, and datasets, please refer to the project's repository: https://github.com/ingrydpereira/multiview-fake-news.
A post-selection algorithm for improving dynamic ensemble selection methods
Sep 26, 2023



Dynamic Ensemble Selection (DES) is a Multiple Classifier Systems (MCS) approach that aims to select an ensemble for each query sample during the selection phase. Even with the proposal of several DES approaches, no particular DES technique is the best choice for different problems. Thus, we hypothesize that selecting the best DES approach per query instance can lead to better accuracy. To evaluate this idea, we introduce the Post-Selection Dynamic Ensemble Selection (PS-DES) approach, a post-selection scheme that evaluates ensembles selected by several DES techniques using different metrics. Experimental results show that using accuracy as a metric to select the ensembles, PS-DES performs better than individual DES techniques. PS-DES source code is available in a GitHub repository
The choice of scaling technique matters for classification performance
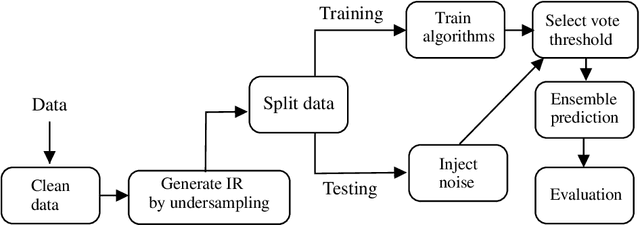
Dec 23, 2022Dataset scaling, also known as normalization, is an essential preprocessing step in a machine learning pipeline. It is aimed at adjusting attributes scales in a way that they all vary within the same range. This transformation is known to improve the performance of classification models, but there are several scaling techniques to choose from, and this choice is not generally done carefully. In this paper, we execute a broad experiment comparing the impact of 5 scaling techniques on the performances of 20 classification algorithms among monolithic and ensemble models, applying them to 82 publicly available datasets with varying imbalance ratios. Results show that the choice of scaling technique matters for classification performance, and the performance difference between the best and the worst scaling technique is relevant and statistically significant in most cases. They also indicate that choosing an inadequate technique can be more detrimental to classification performance than not scaling the data at all. We also show how the performance variation of an ensemble model, considering different scaling techniques, tends to be dictated by that of its base model. Finally, we discuss the relationship between a model's sensitivity to the choice of scaling technique and its performance and provide insights into its applicability on different model deployment scenarios. Full results and source code for the experiments in this paper are available in a GitHub repository.\footnote{https://github.com/amorimlb/scaling\_matters}
Local overlap reduction procedure for dynamic ensemble selection
Jun 16, 2022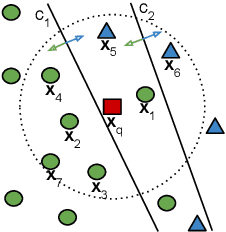
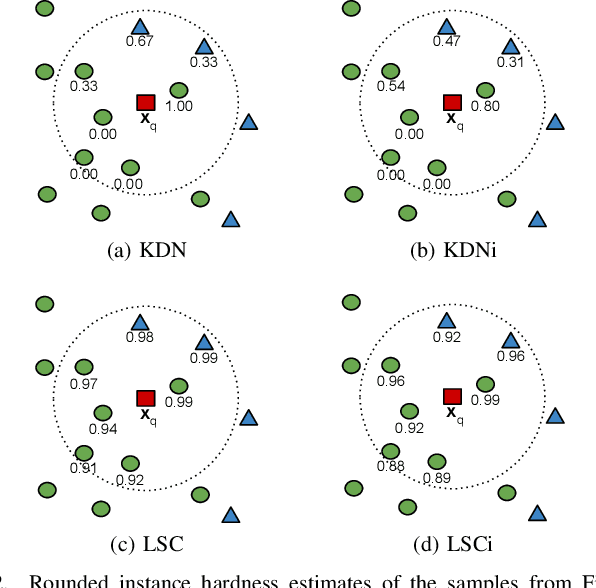
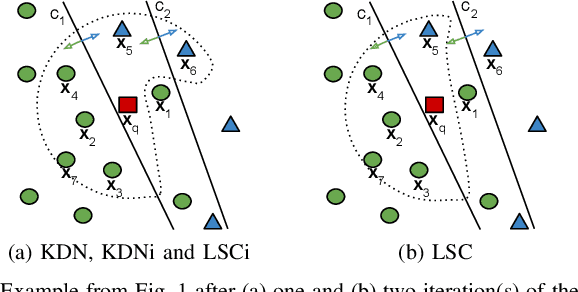
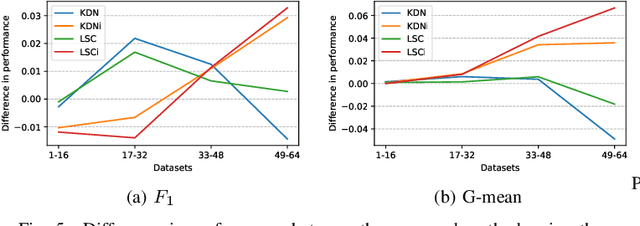
Class imbalance is a characteristic known for making learning more challenging for classification models as they may end up biased towards the majority class. A promising approach among the ensemble-based methods in the context of imbalance learning is Dynamic Selection (DS). DS techniques single out a subset of the classifiers in the ensemble to label each given unknown sample according to their estimated competence in the area surrounding the query. Because only a small region is taken into account in the selection scheme, the global class disproportion may have less impact over the system's performance. However, the presence of local class overlap may severely hinder the DS techniques' performance over imbalanced distributions as it not only exacerbates the effects of the under-representation but also introduces ambiguous and possibly unreliable samples to the competence estimation process. Thus, in this work, we propose a DS technique which attempts to minimize the effects of the local class overlap during the classifier selection procedure. The proposed method iteratively removes from the target region the instance perceived as the hardest to classify until a classifier is deemed competent to label the query sample. The known samples are characterized using instance hardness measures that quantify the local class overlap. Experimental results show that the proposed technique can significantly outperform the baseline as well as several other DS techniques, suggesting its suitability for dealing with class under-representation and overlap. Furthermore, the proposed technique still yielded competitive results when using an under-sampled, less overlapped version of the labelled sets, specially over the problems with a high proportion of minority class samples in overlap areas. Code available at https://github.com/marianaasouza/lords.
Selecting and combining complementary feature representations and classifiers for hate speech detection
Jan 18, 2022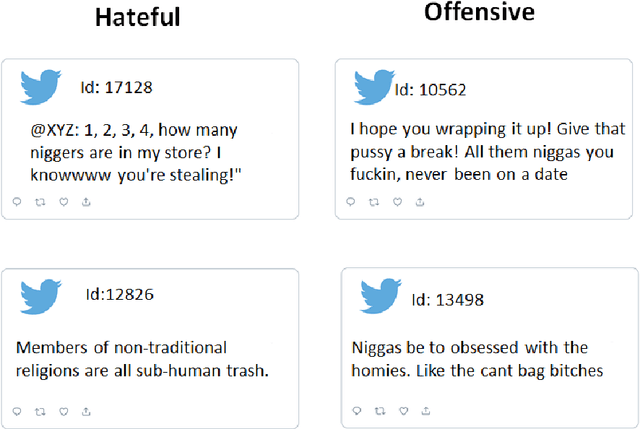
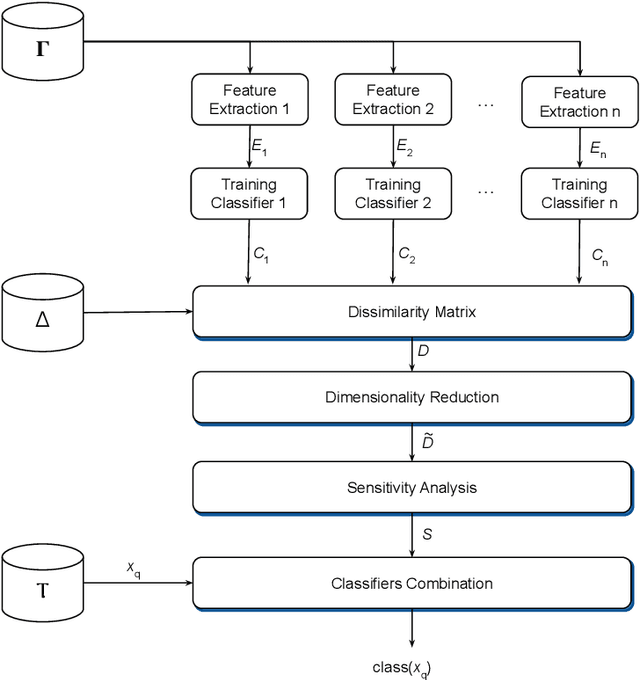
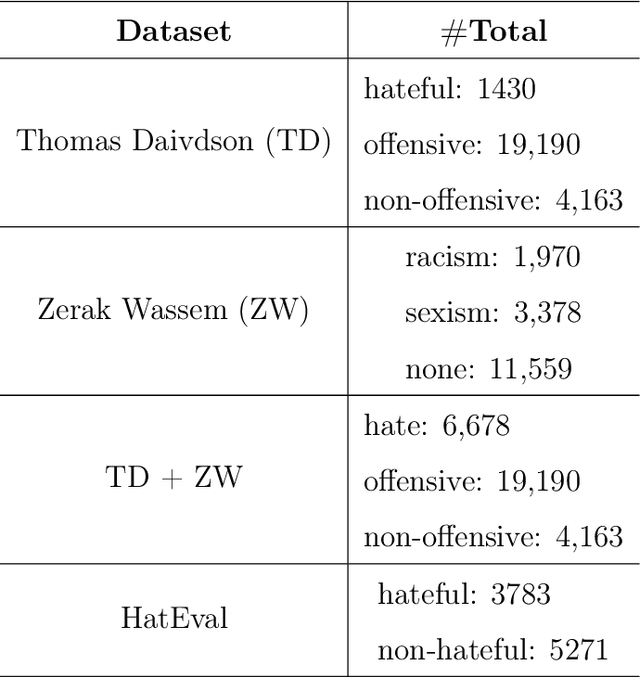

Hate speech is a major issue in social networks due to the high volume of data generated daily. Recent works demonstrate the usefulness of machine learning (ML) in dealing with the nuances required to distinguish between hateful posts from just sarcasm or offensive language. Many ML solutions for hate speech detection have been proposed by either changing how features are extracted from the text or the classification algorithm employed. However, most works consider only one type of feature extraction and classification algorithm. This work argues that a combination of multiple feature extraction techniques and different classification models is needed. We propose a framework to analyze the relationship between multiple feature extraction and classification techniques to understand how they complement each other. The framework is used to select a subset of complementary techniques to compose a robust multiple classifiers system (MCS) for hate speech detection. The experimental study considering four hate speech classification datasets demonstrates that the proposed framework is a promising methodology for analyzing and designing high-performing MCS for this task. MCS system obtained using the proposed framework significantly outperforms the combination of all models and the homogeneous and heterogeneous selection heuristics, demonstrating the importance of having a proper selection scheme. Source code, figures, and dataset splits can be found in the GitHub repository: https://github.com/Menelau/Hate-Speech-MCS.
Label noise detection under the Noise at Random model with ensemble filters
Dec 02, 2021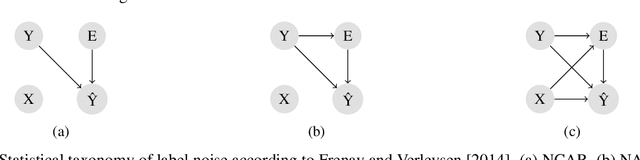


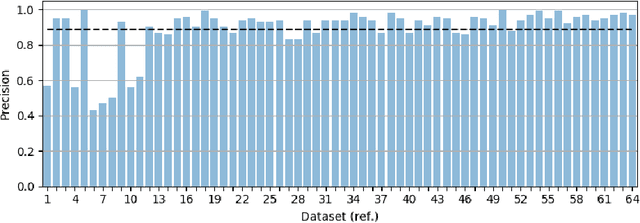
Label noise detection has been widely studied in Machine Learning because of its importance in improving training data quality. Satisfactory noise detection has been achieved by adopting ensembles of classifiers. In this approach, an instance is assigned as mislabeled if a high proportion of members in the pool misclassifies it. Previous authors have empirically evaluated this approach; nevertheless, they mostly assumed that label noise is generated completely at random in a dataset. This is a strong assumption since other types of label noise are feasible in practice and can influence noise detection results. This work investigates the performance of ensemble noise detection under two different noise models: the Noisy at Random (NAR), in which the probability of label noise depends on the instance class, in comparison to the Noisy Completely at Random model, in which the probability of label noise is entirely independent. In this setting, we investigate the effect of class distribution on noise detection performance since it changes the total noise level observed in a dataset under the NAR assumption. Further, an evaluation of the ensemble vote threshold is conducted to contrast with the most common approaches in the literature. In many performed experiments, choosing a noise generation model over another can lead to different results when considering aspects such as class imbalance and noise level ratio among different classes.
Multi-label learning for dynamic model type recommendation
Apr 01, 2020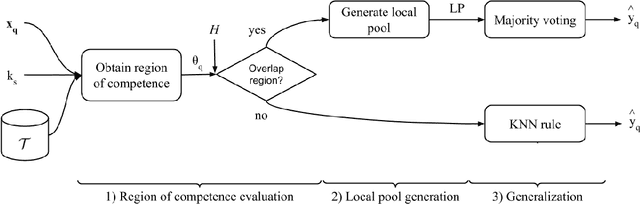
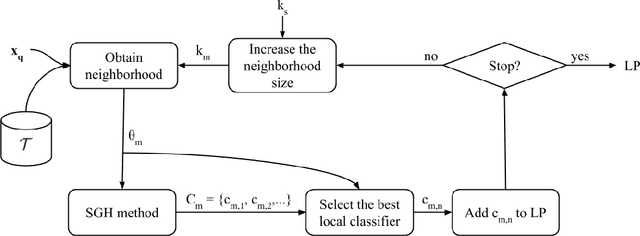
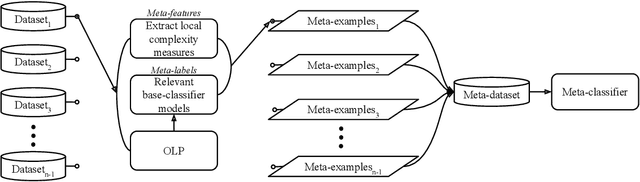
Dynamic selection techniques aim at selecting the local experts around each test sample in particular for performing its classification. While generating the classifier on a local scope may make it easier for singling out the locally competent ones, as in the online local pool (OLP) technique, using the same base-classifier model in uneven distributions may restrict the local level of competence, since each region may have a data distribution that favors one model over the others. Thus, we propose in this work a problem-independent dynamic base-classifier model recommendation for the OLP technique, which uses information regarding the behavior of a portfolio of models over the samples of different problems to recommend one (or several) of them on a per-instance manner. Our proposed framework builds a multi-label meta-classifier responsible for recommending a set of relevant model types based on the local data complexity of the region surrounding each test sample. The OLP technique then produces a local pool with the model that yields the highest probability score of the meta-classifier. Experimental results show that different data distributions favored different model types on a local scope. Moreover, based on the performance of an ideal model type selector, it was observed that there is a clear advantage in choosing a relevant model type for each test instance. Overall, the proposed model type recommender system yielded a statistically similar performance to the original OLP with fixed base-classifier model. Given the novelty of the approach and the gap in performance between the proposed framework and the ideal selector, we regard this as a promising research direction. Code available at github.com/marianaasouza/dynamic-model-recommender.