 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel noise detection under the Noise at Random model with ensemble filters
Paper and Code
Dec 02, 2021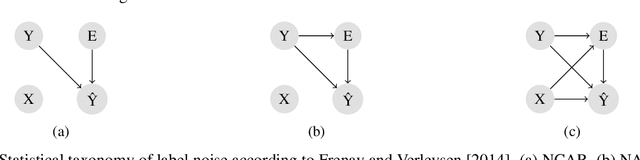

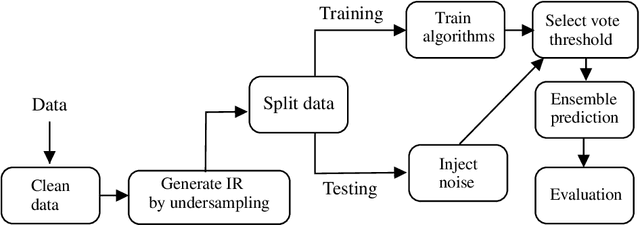

Label noise detection has been widely studied in Machine Learning because of its importance in improving training data quality. Satisfactory noise detection has been achieved by adopting ensembles of classifiers. In this approach, an instance is assigned as mislabeled if a high proportion of members in the pool misclassifies it. Previous authors have empirically evaluated this approach; nevertheless, they mostly assumed that label noise is generated completely at random in a dataset. This is a strong assumption since other types of label noise are feasible in practice and can influence noise detection results. This work investigates the performance of ensemble noise detection under two different noise models: the Noisy at Random (NAR), in which the probability of label noise depends on the instance class, in comparison to the Noisy Completely at Random model, in which the probability of label noise is entirely independent. In this setting, we investigate the effect of class distribution on noise detection performance since it changes the total noise level observed in a dataset under the NAR assumption. Further, an evaluation of the ensemble vote threshold is conducted to contrast with the most common approaches in the literature. In many performed experiments, choosing a noise generation model over another can lead to different results when considering aspects such as class imbalance and noise level ratio among different classes.